简单的网页爬虫开发
1. requests安装
使用pip安装requests,代码如下:
pip install requests
1. 使用requests获取网页源代码
网页有很多种打开方式,最常见的是GET方式和POST方式。
1.1 GET方式
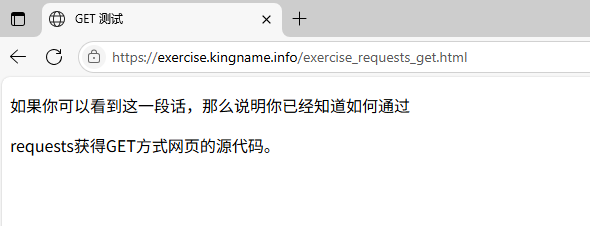
通过网页 http://exercise.kingname.info/exercise_requests_get.html
可以测试使用requests的get()方法获取网页
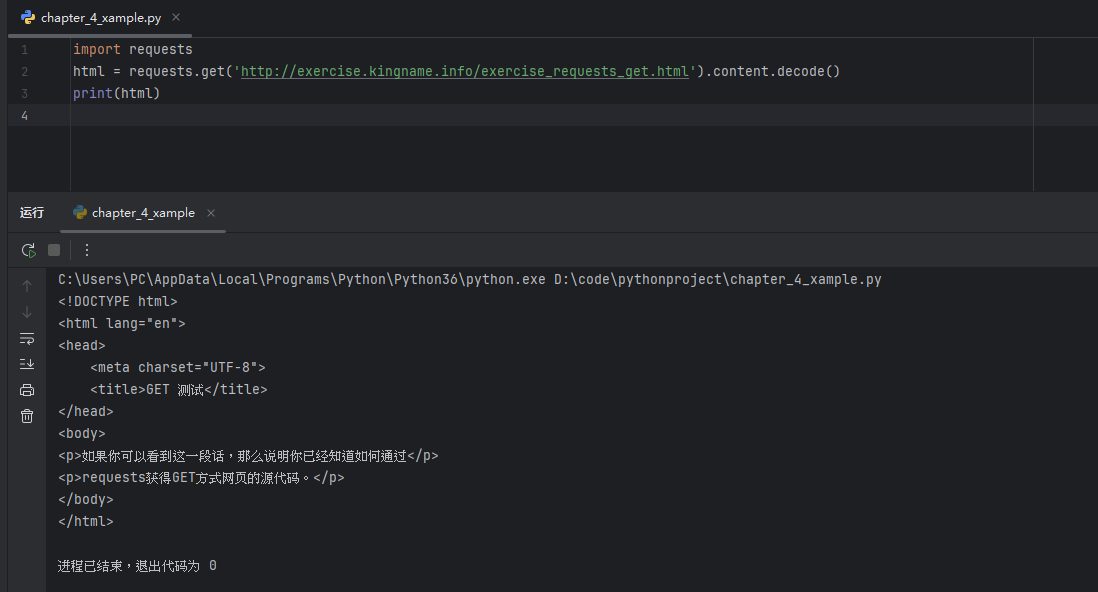
import requests
html = requests.get('http://exercise.kingname.info/exercise_requests_get.html').content.decode()
print(html)
1.2 结合requests与正则表达式
1.提取标题
title = re.search('title>(.*?)<',html,re.S).group(1)
2.提取正文,并将两段正文使用换行符拼接起来。
content_list = re.findall('p>(.*?)<',html,re.S)
content_str = '\n'.join(content_list)
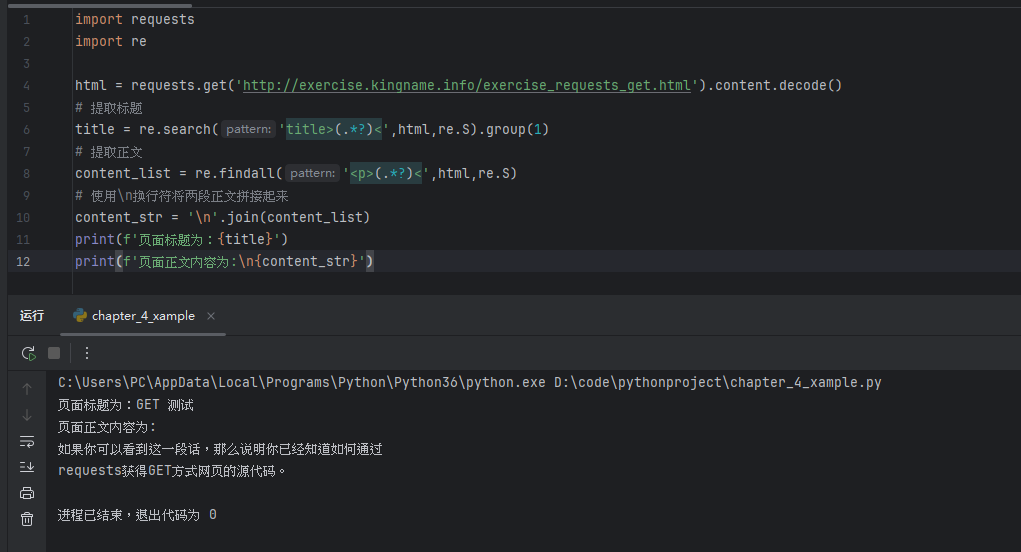
import requests
import re
html = requests.get('http://exercise.kingname.info/exercise_requests_get.html').content.decode()
# 提取标题
title = re.search('title>(.*?)<',html,re.S).group(1)
# 提取正文
content_list = re.findall('<p>(.*?)<',html,re.S)
# 使用\n换行符将两段正文拼接起来
content_str = '\n'.join(content_list)
print(f'页面标题为:{title}')
print(f'页面正文内容为:\n{content_str}')
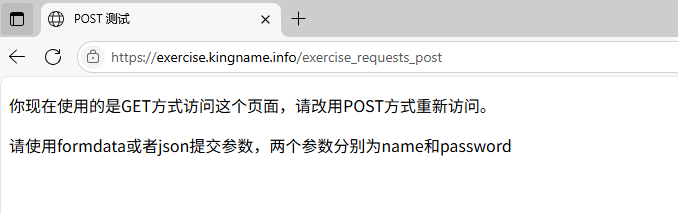
1.3 POST方式
通过浏览器直接访问网页会得到错误信息,故可以通过post方式在网页:https://exercise.kingname.info/exercise_requests_post
可以测试使用requests的post()方法获取网页
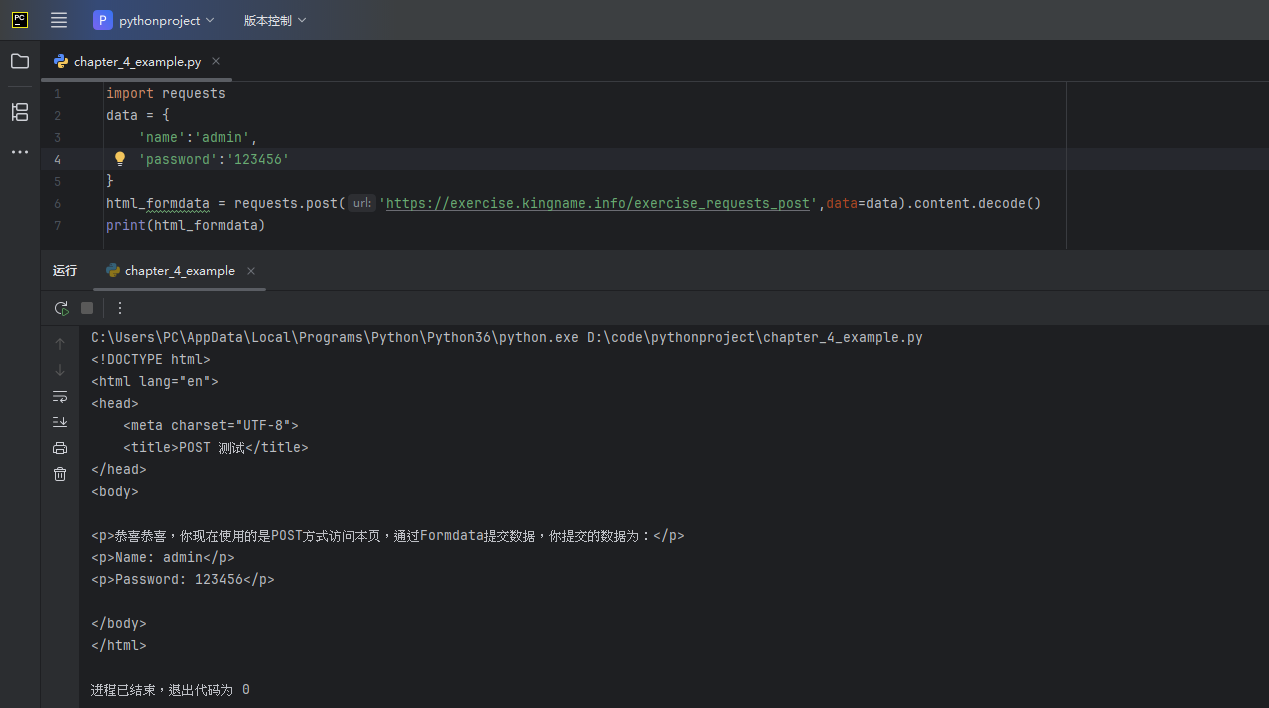
import requests
data = {
'name':'admin',
'password':'123456'
}
html_formdata = requests.post('https://exercise.kingname.info/exercise_requests_post',data=data).content.decode()
print(html_formdata)
1.4 多线程爬虫测试
循环访问百度首页100次
单线程爬虫
def query(url):
requests.get(url)
start = time.time()
for i in range(100):
query('https://www.baidu.com')
end = time.time()
print(f'单线程循环访问100次百度首页,耗时:{end - start}')
多线程爬虫
start = time.time()
url_list = []
for i in range(100):
url_list.append('https://www.baidu.com')
pool = Pool(5)
pool.map(query,url_list)
end = time.time()
print(f'五线程循环访问100次百度首页,耗时:{end - start}')
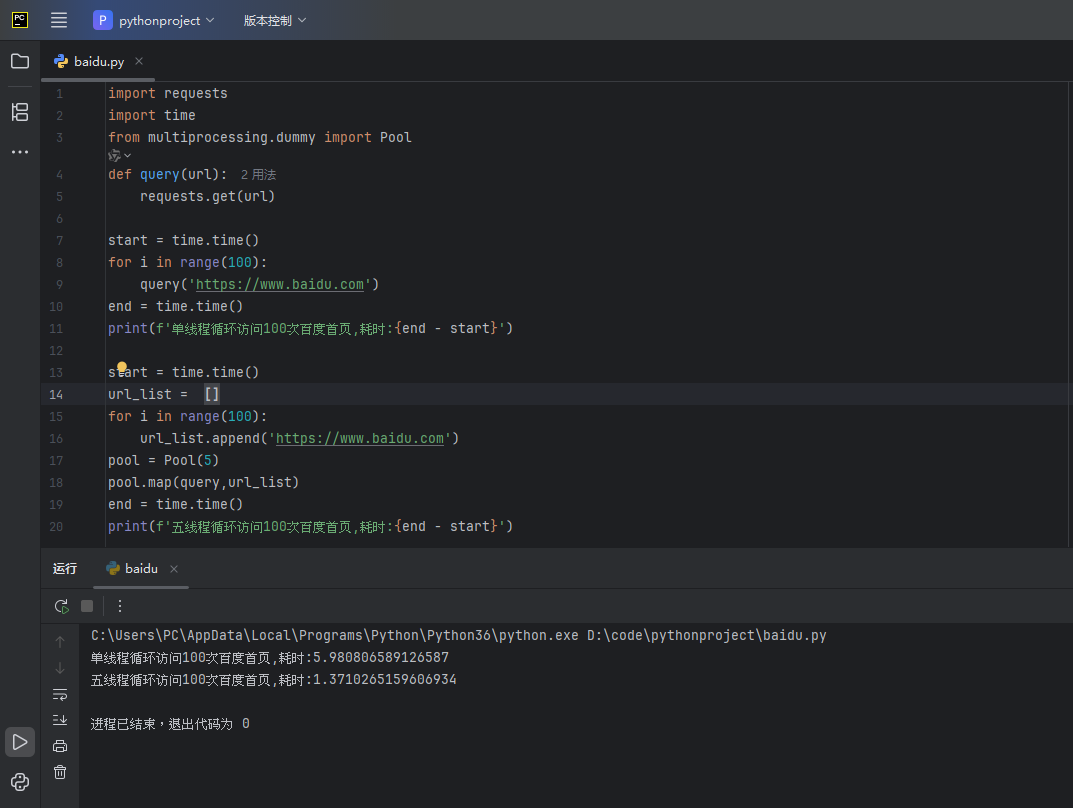
import requests
import time
from multiprocessing.dummy import Pool
def query(url):
requests.get(url)
start = time.time()
for i in range(100):
query('https://www.baidu.com')
end = time.time()
print(f'单线程循环访问100次百度首页,耗时:{end - start}')
start = time.time()
url_list = []
for i in range(100):
url_list.append('https://www.baidu.com')
pool = Pool(5)
pool.map(query,url_list)
end = time.time()
print(f'五线程循环访问100次百度首页,耗时:{end - start}')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号