node_modules 瘦身
起因
场景一:
当前项目经历了刀耕火种地开发, 之后接入了 cli 工具集中管理打包, 那么项目中的依赖,
和 cli 工具中的依赖重合度是多少, 并且他的的版本是否相同, 是否有冗余代码
场景二:
项目中某一个库升级了, 他依赖了 A 库的 V3 版本, 同时当前项目依赖的是 A 库 V2版本, 这个时候打包很明显, 就会将这一个包的不同版本同时打入
场景三:
当前 deps 中有对应的依赖库, 但是业务代码中并未使用到
由于上述的场景, 我们需要一个工具来解决这些情况
思考🤔
这些场景改如何解决, 解决的方案是什么
针对场景三来说, 现在已经有一个库: depcheck
简单的原理: 通过检测项目中的文件 import 或者 require 和依赖进行对比, 最后生成依赖列表
想要一定的配置
(通过实际的调用, 发现还存在一定的问题: 在子模块中的代码未能被检测, 同时关于依赖中的 babel 配置插件检测也是同样的)
而场景一和二就和三不太一样了, 他是已有库, 但是略有重复, 所有需要针对库进行检测
目前计划是通过 node 脚本来运行
-
检查 node_modules 或者 lock 文件中, 是否存在同一库的多个版本
-
node_modules 文件层级太多, lock 文件是他的一层映射, 考虑从这里入手
-
确保 lock 文件是最新的(这一层比较麻烦, 没标识来保证, 明确就确保此文件是否存在即可)
-
打开本地网站, 针对结果的可视化显示(经过实际的操作, 这一场景放弃, 具体原因放下下方详述)
开发
这里我们首先解决场景一的问题
场景一
在上面的思考中针对此场景已经了一解决方案了, 即 depcheck 场景, 但是他的配置需要重新编写:
check 配置更新
const options = {
ignoreBinPackage: false, // ignore the packages with bin entry
skipMissing: false, // skip calculation of missing dependencies
ignorePatterns: [
// files matching these patterns will be ignored
'sandbox',
'dist',
'bower_components',
'tsconfig.json'
],
ignoreMatches: [
// ignore dependencies that matches these globs
'grunt-*',
],
parsers: {
// the target parsers
'**/*.js': depcheck.parser.es6,
'**/*.jsx': depcheck.parser.jsx,
'**/*.ts': depcheck.parser.typescript,
// 这里 ts 类型可能会出问题, 但是经过实际的运行和文档说明是没问题的
'**/*.tsx': [depcheck.parser.typescript, depcheck.parser.jsx],
},
detectors: [
// the target detectors
depcheck.detector.requireCallExpression,
depcheck.detector.requireResolveCallExpression,
depcheck.detector.importDeclaration,
depcheck.detector.exportDeclaration,
depcheck.detector.gruntLoadTaskCallExpression,
depcheck.detector.importCallExpression,
depcheck.detector.typescriptImportEqualsDeclaration,
depcheck.detector.typescriptImportType,
],
// specials: [
// // Depcheck API在选项中暴露了特殊属性,它接受一个数组,以指定特殊分析器。
// ],
// 这里将会覆盖原本的 package.json 的解析
// package: {
// },
};
之后再调用配置:
// 默认即当前路径
const check = (path = process.cwd()) => depcheck(path ,options)
最后加上打印结果:
console.log('Unused dependencies:')
unused.dependencies.forEach(name=>{
console.log(chalk.greenBright(`* ${name}`))
})
console.log('Unused devDependencies:');
unused.devDependencies.forEach(name=>{
console.log(chalk.greenBright(`* ${name}`))
})
调用结果的例子展示:
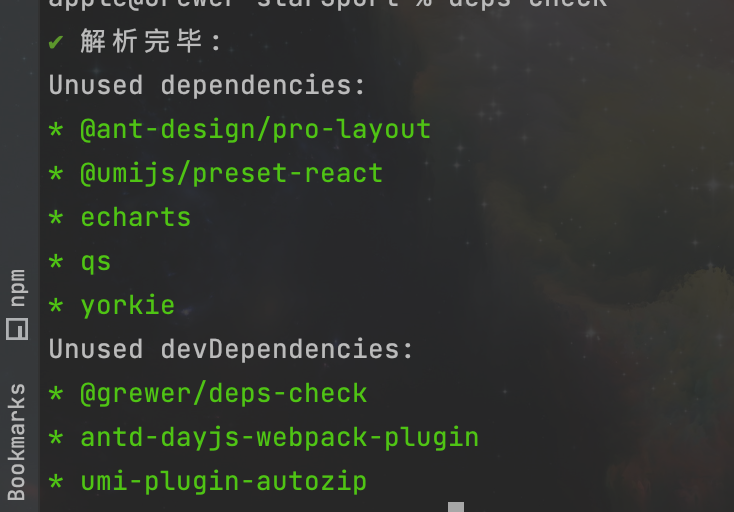
场景二
指令技术选型:
- commander
推荐最多的, 同时也是下载量最多的, 下载量 8kw+
- package-lock.json
针对的 lock 文件, 默认 npm 及其对应的解析, 现在还有 yarn, pnpm 比较流行, 但是
一般在服务器上打包时都用使用 npm 指令
指令的开发
计划中的指令
- check // 默认场景一的操作
- check json // 解析 .lock 文件, 同时打印占用空间的包
- check json -d // 将结果打印成文件
第一步
指令的定义:
const main = () => {
const program = new commander.Command();
program.command('check')
.description('检查使用库')
.action((options) => {
// 显示一个 loading
const spinner = ora('Loading check').start();
// check
check()
}).command('json').description('解析 lock文件').option('-d, --doc', '解析 lock 文件, 将结果保存')
.action(async (options) => {
// 显示 loading
const spinner = ora('Loading check').start();
// 执行脚本
// 额外判断 options.open
deepCheck(spinner, options)
})
program.parse();
}
第二步 解析文件
首先我们通过 fs 来获取文件内容:
const lockPath = path.resolve('package-lock.json')
const data = fs.readFileSync(lockPath, 'utf8')
针对 lock 数据解析:
const allPacks = new Map();
Object.keys(allDeps).forEach(name => {
const item = allDeps[name]
if (item.dev) {
// dev 的暂时忽略掉
return
}
if (item.requires) {
// 和item.dependencies中的操作类似
setCommonPack(item.requires, name, item.dependencies)
}
if (item.dependencies) {
Object.keys(item.dependencies).forEach(depsName => {
const depsItem = item.dependencies[depsName]
if (!allPacks.has(depsName)) {
allPacks.set(depsName, [])
}
const packArr = allPacks.get(depsName);
packArr.push({
location: `${name}/node_modules/${depsName}`,
version: depsItem.version,
label: 'reDeps', // 标识为重复的依赖
size: getFileSize(`./node_modules/${name}/node_modules/${depsName}`)
})
allPacks.set(depsName, packArr)
})
}
})
最后通过一个循环来计算出暂用空间最大的包:
// 创建一个排序数据, push 之后自动根据 size 排序
let topSizeIns = createTopSize()
allPacks.forEach((arr, name, index) => {
if(arr.length <= 1){
return
}
let localSize = 0
arr.forEach((item, itemIndex) => {
const size = Number(item.size)
localSize += size
})
topSizeIns.push({items: arr, size: localSize})
})
// 最后打印结果, 输出可选择文档
if (options.doc) {
fs.writeFileSync(`deepCheck.json`, `${JSON.stringify(mapChangeObj(allPacks), null, 2)}`, {encoding: 'utf-8'})
}
// 打印 top5
console.log(chalk.yellow('占用空间最大的 5 个重复库:'))
topSizeIns.arr.forEach(itemObj => {
const common = itemObj.items.find(it => it.label === 'common')
console.log(chalk.cyan(`${common.location}--${itemObj.size.toFixed(2)}KB`));
itemObj.items.forEach(it => {
console.log(`* ${it.location}@${it.version}--size:${it.size}KB`)
})
})
第三步
图形化方案(已经弃用)
先说说实现方案:
- 转换json 生成的数据至图表需要的数据
- 启动本地服务, 引用 echart 和数据
数据转换:
let nodes = []
let edges = []
packs.forEach((arr, name, index) => {
let localSize = 0
arr.forEach((item, itemIndex) => {
const size = Number(item.size)
nodes.push({
x: Math.random() * 1000,
y: Math.random() * 1000,
id: item.location,
name: item.location,
symbolSize: size > max ? max : size,
itemStyle: {
color: getRandomColor(),
},
})
localSize += size
})
topSizeIns.push({items: arr, size: localSize})
const common = arr.find(it => it.label === 'common')
if (common) {
arr.forEach(item => {
if (item.label === 'common') {
return
}
edges.push({
attributes: {},
size: 1,
source: common.location,
target: item.location,
})
})
}
})
启动服务:
服务并没有使用三方库, 而是添加了一个node http 服务:
var mineTypeMap = {
html: 'text/html;charset=utf-8',
htm: 'text/html;charset=utf-8',
xml: "text/xml;charset=utf-8",
// 省略其他
}
const createServer = () => {
const chartData = fs.readFileSync(getFile('deepCheck.json'), 'utf8')
http.createServer(function (request, response) {
// 解析请求,包括文件名
// request.url
if (request.url === '/') {
// 从文件系统中读取请求的文件内容
const data = fs.readFileSync(getFile('tools.html'))
response.writeHead(200, {'Content-Type': 'text/html'});
// 这里是使用的类似服务端数据的方案, 当然也可以使用引入 json 的方案来解决
const _data = data.toString().replace(new RegExp('<%chartData%>'), chartData)
// 响应文件内容
response.write(_data);
response.end();
} else {
const targetPath = decodeURIComponent(getFile(request.url)); //目标地址是基准路径和文件相对路径的拼接,decodeURIComponent()是将路径中的汉字进行解码
console.log(request.method, request.url, baseDir, targetPath)
const extName = path.extname(targetPath).substr(1);
if (fs.existsSync(targetPath)) { //判断本地文件是否存在
if (mineTypeMap[extName]) {
response.setHeader('Content-Type', mineTypeMap[extName]);
}
var stream = fs.createReadStream(targetPath);
stream.pipe(response);
} else {
response.writeHead(404, {'Content-Type': 'text/html'});
response.end();
}
}
}).listen(8080);
console.log('Server running at http://127.0.0.1:8080/');
opener(`http://127.0.0.1:8080/`);
}
export default createServer
效果图:

通过此图, 可以看到大概问题点所在:
- 依赖包太多, 导致数据显示杂乱
- 根据包真实尺寸大小显示圆圈, 其中的差距过大, 大的有几万 kb, 小的有几十kb
图中暂时闲置了最大 size 200
所以暂时不开启此功能
其他解决方案
在使用 pnpm 的时候, 我发现他能够解决 多余包的大小问题 所以这里我也列了出来
总结
当前已构建出包: @grewer/deps-check 可尝试使用
针对文章一开始提出的三种常见场景, 此包基本上能够解决了
之后还能提出一些优化点, 比如有些包的替换(moment 替换 dayjs, lodash 和 lodash.xx 包不能同时存在等等)
这些就需要长期维护管理了
大家看了本文, 如果有什么好的建议也可以留言告诉我

 浙公网安备 33010602011771号
浙公网安备 33010602011771号