当博主正在看概率论的时候,QQ群突然出现了:

可是博主的手绘板还没到,明天又要交差了,无论怎么赶,都搞不出一份像模像样的作品了。
但博主想起曾经在知乎上看到的文章(https://www.zhihu.com/question/27621722),不久前还学习了爬虫技术,再加上学校的包容开放,便有了这个想法:
将相关的图片拼接在一起,组成内容。
说干就干。在查阅资料后,博主选择了旧版的百度图片(方便操作,也没有爬虫警告和防爬机制)。经过分析,我们发现:
https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E6%AD%A6%E6%B1%89%E5%8A%A0%E6%B2%B9&pn=20&gsm=3c&ct=&ic=0&lm=-1&width=0&height=0
对于一个特定的关键词(就是word后面的部分,这里是“武汉加油”),百度会搜集与之相关的图片。而后面pn则是相应的偏移数目,由于旧版百度图片一页上会放20张图,20就相当于翻了一页(说实话,我觉得旧版的这样的设计好多了,新版的还会不停加载,非常难受和别扭)。
接下来是获得url。根据百度的特性,我们不难发现:
这里用正则表达式:"objURL":"(.*?)"去匹配就好了,效果不错。
代码:


1 import requests 2 import os 3 from bs4 import BeautifulSoup as bs 4 import re 5 6 maxstep=10 7 tot=0 8 path="picture" 9 10 headers={ 11 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE' 12 } 13 #######################################新建文件夹 14 def mkdir(path): 15 if os.path.exists(path): 16 return 17 else: 18 os.makedirs(path) 19 #######################################保存图片 20 def save(content): 21 global tot,path 22 mkdir(path) 23 with open(path+"/"+str(tot)+".png","wb+") as file: 24 file.write(content) 25 file.close() 26 #######################################下载图片 27 def download(url): 28 global tot 29 tot=tot+1 30 try: 31 html=requests.get(url,timeout=2) 32 save(html.content) 33 print(tot,"succeeded") 34 except: 35 print(tot,"failed") 36 #######################################获得相应信息 37 def getHtml(url): 38 html=requests.get(url,headers=headers) 39 html.encoding="utf-8" 40 return html.content 41 #######################################主函数 42 def main(): 43 for pages in range(1,30): 44 print("Now page",pages) 45 url="https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E6%AD%A6%E6%B1%89%E5%8A%A0%E6%B2%B9&pn="+str(pages*20)+"&gsm=3c&ct=&ic=0&lm=-1&width=0&height=0" 46 html=getHtml(url) 47 pat='"objURL":"(.*?)"' 48 result=re.compile(pat).findall(str(html)) 49 for i in result: 50 print(i) 51 download(i) 52 # file=open("observe.txt","w",encoding="utf-8") 53 # file.write(soup.prettify()) 54 ####################################### 55 if(__name__=="__main__"): 56 main()
下载内容:
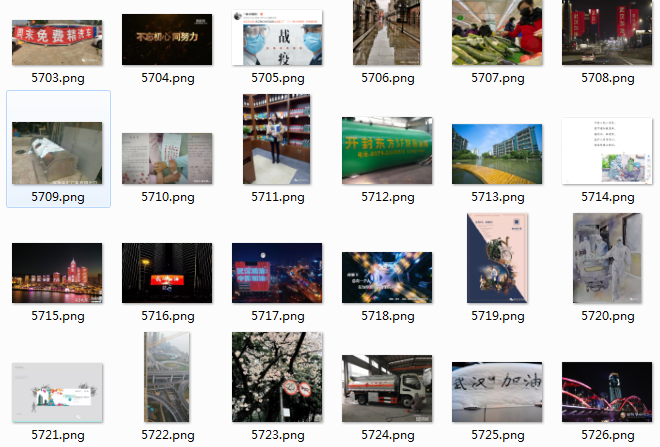
接下来就是拼图片。使用软件Foto-Mosaik-Edda(操作简便,小学一年级英语水平就能使用)就能完成拼接。
加了些许修改的原图片:(作者当然不是我,不然我还写什么爬虫)

拼接后:

一个小时内完成赶工。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号