Python-网络爬虫
问题
?为什么获取到请求头就可以越过反爬虫机制
?IP地址被服务器屏蔽之后,使用代理IP是如何实现的
网络爬虫概述
按照指定的规则(网络爬虫算法)自动浏览或者抓取网络中的信息。
网络爬虫的分类
1.通用网络爬虫
2.聚焦网络爬虫(主题网络爬虫):
按照预先定义好的主题,有针对性的选择相关的网页爬取信息
3.增量式网络爬虫:
爬取新产生的页面或者有新内容更新的页面
4.深层网络爬虫:
Surfase Web:不需要提交表单,通过超链接就可以访问的静态页面
Deep Web:需要提交一些关键词才能获取内容的页面
网络爬虫的基本原理
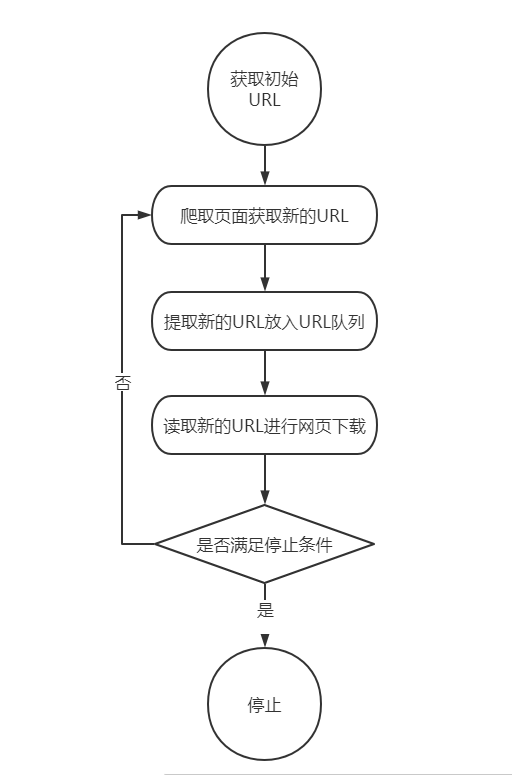
网络爬虫的常用技术
示例:
1.urllib 模块
import urllib.request
res = urllib.request.urlopen("http://www.httpbin.org")
html = res.read()
print(html)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号