HDFS
HDFS
简介:
- HDFS:是一个分布式的文件存储系统
- namenode:管理者,一个HDFS体系只有一个nn节点,保存数据在dn上的位置等信息,确定数据上传时存储的具体位置
- datanode:员工:用来直接存储数据,一个体系中可以有一个或多个dn
- secondarynamenode:是对nn进行备份的
- client:客户端,用户直接进行操作的地方,负责将数据上传到dn,跟nn通信,数据的下载。
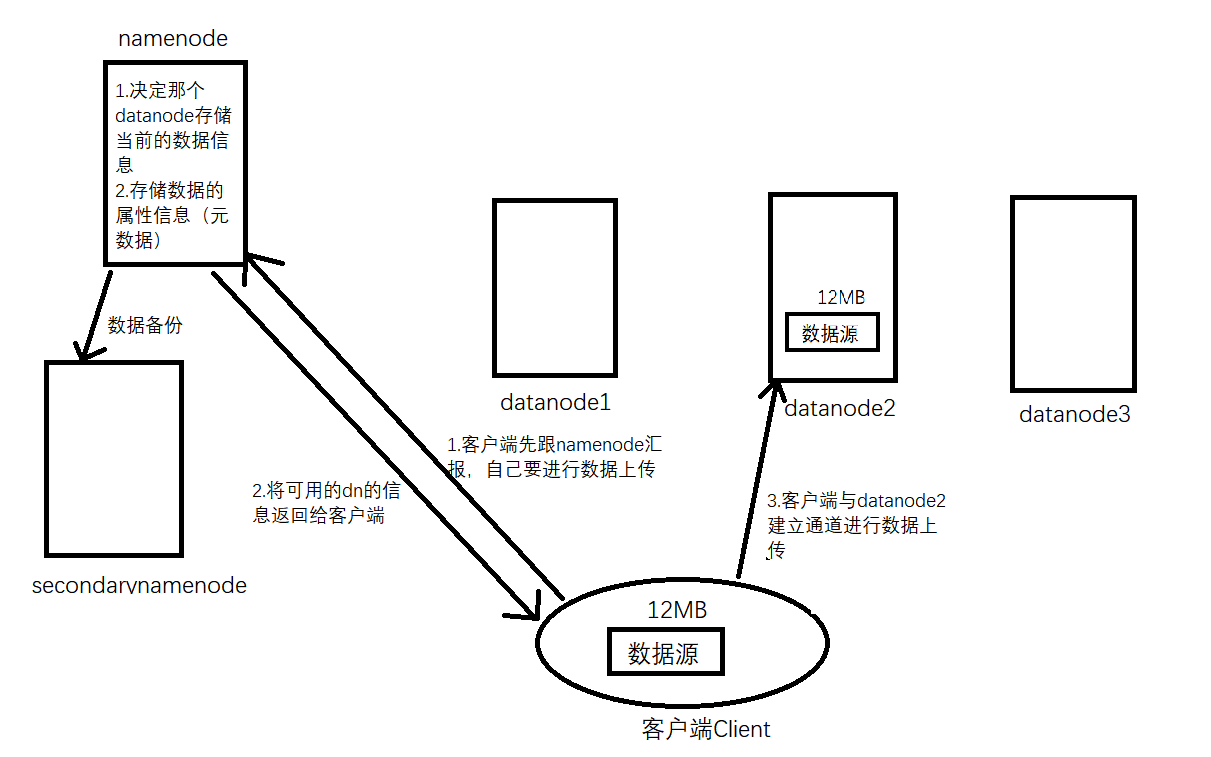
注:多个节点组成一个集群,在他们上面进行数据的存储,形成的系统就是HDFS(这里的节点跟服务器和客户端一样都是应用)
HDFS安装模式的分类
本地模式:
- 特点:
- 运行在单台机器上
- 没有分布式的概念,使用的是本地文件系统
- 用途:
- 用于对MapReduce程序的逻辑进行调试,确保程序的正确
- 由于在本地模式下测试和调试MapReduce程序较为方便,因此,这种模式适宜用在开发阶段。
伪分布式模式:
- 特点:
- 在一台机器上安装,使用的是分布式文件系统,非本地文件系统
- HDFS涉及到的相关守护进程(namenode,datanode,secondarynamenode)都运行在一台机器上,都是独立的Java进程
- 用途:
- 比Standalone mode多了代码调试功能,允许检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
(与本地模式的区别:一个没有分布式系统,一个是具有分布式系统的)
- 比Standalone mode多了代码调试功能,允许检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
完全分布式模式:
- 特点:
- 真实环境,多台机器,共同配合,来构建一个完整的分布式文件系统。
- 真实环境,HDFS中的相关守护进程会分布在不同的机器中,如:
- namenode尽可能单独部署在一台硬件性能相对来说比较好的机器中。
- 其他的每台机器都会部署一个datanode守护进程,一般的硬件环境即可(这里主要考虑成本)
- secondarynamenode守护进程最好不要和namenode在同一台机器中,不然的话备份的作用就失去了意义,一台机器挂掉了就两个节点都刮掉了,所以最好不在同一台机器中。
完全分布式系统的搭建
Hadoop配置文件
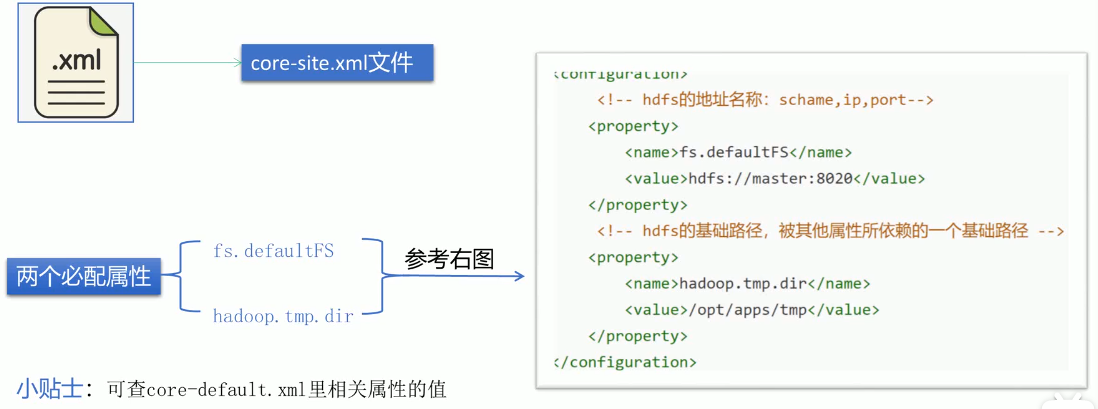
- 针对于Hadoop的属性配置,有以下三处需要注意的地方:
- 默认配置文件:
- core-default.xml
- hdfs-default.xml
- mapred-default.xml
- yarnn-default.xml
- 用户自定义配置文件
- core-site.xml
- hdfs-site.xml
- mqpred-site.xml
- yarn-site.xml
- 代码中设定的参数
- 默认配置文件:
- 如果三个地方都进行了相关属性的配置,那么属性的值是有一个优先级的:
- 代码中设定参数 > 用户自定义配置文件 > 默认配置文件
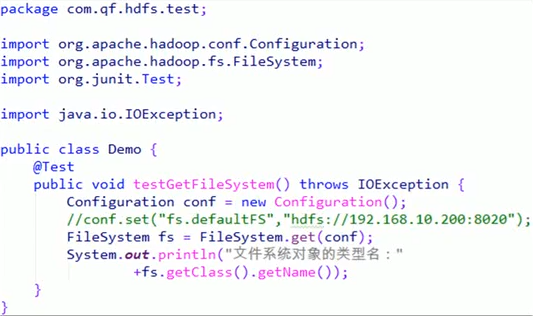
相关配置文件的修改
- 想要搭建完全分布式集群,需要对hadoop-3.2.2/etc/hadoop/目录下的用户自定义配置文件进行如下配置:
- core-site.xml
- core-site.xml

 浙公网安备 33010602011771号
浙公网安备 33010602011771号