
deeplearning.ai涉及论文
A collection of papers mentioned in the deep learning course of Andrew Ng
1. Neural Networks and Deep Learning
None
2. Improving Deep Neural Networks Hyperparameter tuning, Regularization and Optimization
Dropout; regularization;
Srivastava, Nitish, et al. “Dropout: A simple way to prevent neural networks from overfitting.” The Journal of Machine Learning Research 15.1 (2014): 1929-1958.
https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf
RMSprop; optimization of gradient descent, it is an unpublished, adaptive learning rate method proposed by Geoff Hinton in Lecture 6e of his Coursera Class. RMSprop and Adadelta have both been developed independently around the same time stemming from the need to resolve Adagrad’s radically diminishing learning rates.
Tieleman, Tijmen, and Geoffrey Hinton. “Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude.” COURSERA: Neural networks for machine learning 4.2 (2012): 26-31.
Adam optimization algorithm; an algorithm for first-order gradient-based optimization of stochastic objective functions, based on adaptive estimates of lower-order moments.
https://arxiv.org/pdf/1412.6980.pdf
Batch normalization
Ioffe, Sergey, and Christian Szegedy. “Batch normalization: Accelerating deep network training by reducing internal covariate shift.” International conference on machine learning. 2015.
3. Structuring Machine Learning Projects
None
4. Convolutional Neural Networks
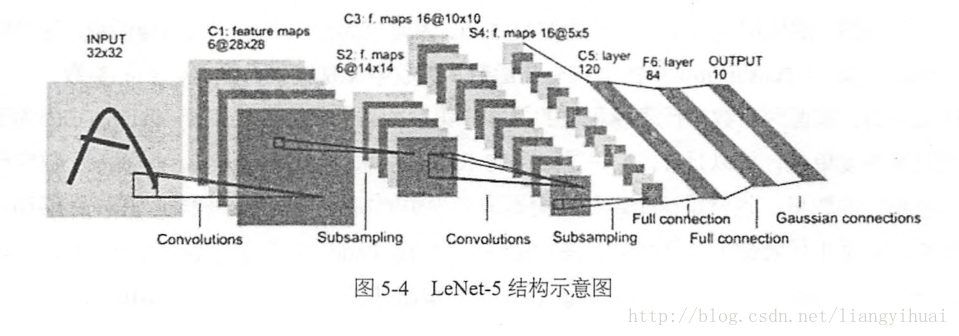
LeNet-5; a kind of nueral network model;
LeCun et al., 1998. Gradient-based learning applied to document recognition
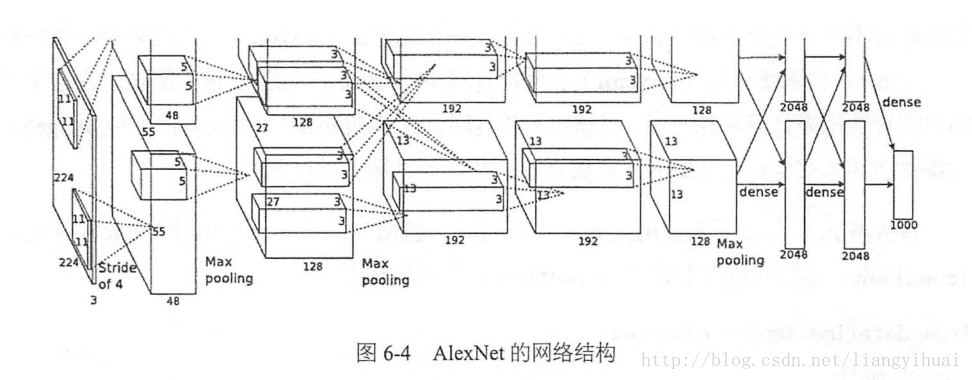
- AlexNet; a kind of nueral network model;
Krizhevsky et al., 2012. ImageNet classification with deep convolutional neural networks

- VGG-16;
Simonyan & Zisserman 2015. Very deep convolutional networks for large-scale image recognition
ResNet(Residual Network);
He et al., 2015. Deep residual networks for image recognition
Network in Network (one by one convolution); filter size is (1 ,1), but filter number is more than one;
Lin et al., 2013, Network in network.
inception network; motivation for inception network;
Szegedy et al. 2014. Going deeper with convolutions
object recognition;
Sermanet et al., 2014, OverFeat: Integrated recognition, localization and detection using convolutional networks
YOLO (you only look once); real-time object detection;
Redmon et al,. 2015. You Only Look Once: Unified real-time object detection.
R-CNN; region proposal, classify proposed regions one at a time. output label + bounding box;
Girshik et al., 2013. Rich feature hierarchies for accurate object detection and semantic segmentation.
Fast R-CNN; Propose regions, use convolution implementation of sliding windows to classify all the proposed regions;
Girshik, 2015. Fast R-CNN.
Faster R-CNN; use convolutional network to propose regions;
Ren et.al, 2016. Faster R-CNN:Towards real-time object detection with region proposal networks.
Siamese network; Face recognition;
Taigman et.al., 2014. DeepFace closing the gap to human level performance
FaceNet;
Schreff et.al., 2015, FaceNet: A unified embedding for face recognition and clustering
5. Sequence Models
gated recurrent unit;
Cho et al., 2014. On the properties of neural machine translation: Encoder-decoder approaches
gated recurrent unit;
Chung et al., 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling.
LSTM (long short-term memory);
Hochreiter & Schmidhuber 1997. Long short-term memory
Visualizing word embeddings
van der Maaten and Hinton., 2008. Visualizing data using t-SNE
About word embedding
Mikolov et.al., 2013. Linguistic regularities in continuous space word representations
neural language model. to predict next word.
Bengio et.al., 2003, A neural probabilistic language model
Skip-gram model, about how to learn word-to-vector of word embedding in the neural network.
Mikolov et.al., 2013. Efficient estimation of word representations in vector space
Negative sampling; similar to skip-gram model but with much more efficient.
Mikolov et.al., 2013. Distributed representation of words and phrases and their compositionality.
GloVe (global vectors for word representation); Has some momentum in the NLP community. It is not used as much as the Word2Vec or the skip-gram models.
Pennington et.al., 2014. GloVe: Global vectors for word representation.
About the problem of bias in word embeddings.
Bolukbasi et.al., 2016. Man is to computer programmer as woman is to homemaker? Debiasing word embeddings
CTC (Connectionist temporal classification) cost for speech recognition
Graves et al., 2006. Connectionist Temporal Classification: Labeling unsegmented sequence data with recurrent neural networks
language tranlation; Sequence to sequence model
Sutskever et al., 2014. Sequence to sequence learning with neural networks
language tranlation; Sequence to sequence model
Cho et al., 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation
Image captioning
Mao et. al., 2014. Deep captioning with multimodal recurrent neural networks
Vinyals et.al., 2014. Show and tell: Neural image caption generator
Karpathy and Fei Fei, 2015. Deep visual-semantic alignments for generating image descriptions
Evaluating machine translation
Papineni et.al., 2002. A method for automatic evaluation of machine translation
Attention model
Bahdanau et.al., 2014. Neural machine translation by jointly learning to align and tranlate
Xu et.al., 2015. Show attention and tell: neural image caption generation with visual attention

 浙公网安备 33010602011771号
浙公网安备 33010602011771号