
Tomcat是如何将请求一步步传递到我们编写的HttpServlet类中的
我们平常编写好的HttpServlet类后,就可以处理请求了,但是服务器在接收到请求信息以后是如何将这些请求传递到我们编写的Servlet类中的???这个疑问在我心中的已经很久了,现在要来解决它。
我们之前的一篇文章Tomcat中容器是什么以及容器与容器之间的数量关系。简单介绍Tomcat服务器的容器,以及容器与容器之间的关系。现在来讲一下在服务器端口接收到请求后,这些请求是如何在这些容器之间传递的。
一、先建立一个简单的动态WEB工程,然后写一个HttpServlet的实现类。代码如下
@WebServlet("/TestServlet")
public class TestServlet extends HttpServlet
{
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException
{
System.out.println("这个doGet方法");
request.getRequestDispatcher("/test.jsp").forward(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException
{
}
}
编写一个访问页面,index.jsp.
<body> <h3>主页</h3> <a href="/Test2/TestServlet" >Test</a> </body>
一个响应页面。
<body> <h3>成功响应</h3> </body>
二、请求的需要经过哪些地方。
请求信息会经过以下的接口(java类)及其子类来处理,就相当于要经过许多模块来处理。
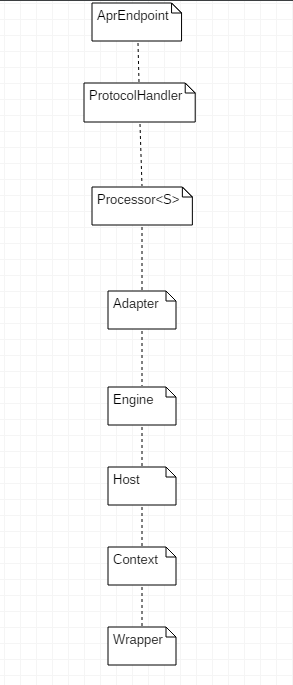
三、具体步骤
如上图,请求在服务器的处理经过:
①、AbstractEndpoint类及其子类来处理。
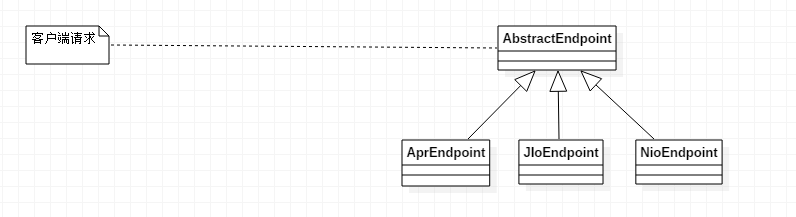
AbstractEndpoint这个抽象类中有一个抽象内部类Acceptor,这个Acceptor的实现类是AbstractEndpoint的三个子类的内部类Acceptor来实现的。

我们的请求就是被这Acceptor监听到并且接收的。这个类其实是一个线程类,因为AbstractEndpoint.Acceptor实现了Runnable接口。
@Override
public void run() {
int errorDelay = 0; // running表示endpoint的状态,在run()方法中这个while循环,会一直循环接收数据,直到endpoint 不处于运行状态。 while (running) { // 当endpoint暂停,但还是运行状态就让线程睡眠。 while (paused && running) { state = AcceptorState.PAUSED; try { Thread.sleep(50); } catch (InterruptedException e) { // Ignore } } //endpoint不处于运行状态,就停止接收数据。 if (!running) { break; } state = AcceptorState.RUNNING;
//下面就是的接收数据的过程。 try { //if we have reached max connections, wait countUpOrAwaitConnection(); long socket = 0; try { // 从server sock 接收传进来的连接。 socket = Socket.accept(serverSock); if (log.isDebugEnabled()) { long sa = Address.get(Socket.APR_REMOTE, socket); Sockaddr addr = Address.getInfo(sa); log.debug(sm.getString("endpoint.apr.remoteport", Long.valueOf(socket), Long.valueOf(addr.port))); } } catch (Exception e) { //省略了部分处理异常的代码。// The processor will recycle itself when it finishes }
state = AcceptorState.ENDED; }
以上就是AprEndpoint接收请求的过程。就是用一个接收器接收请求,过程中会使用套接字。但是好像并不是有的请求都会用这个Acceptor来接收。
当接收请求完毕,经过一系列的处理后就会由AprEndpoint的内部类SocketProcessor来将请求传给ProtocolHandler来处理。这个SocketProcessor也是一个线程类。
它有一行代码将套接字传给了第二步来处理。
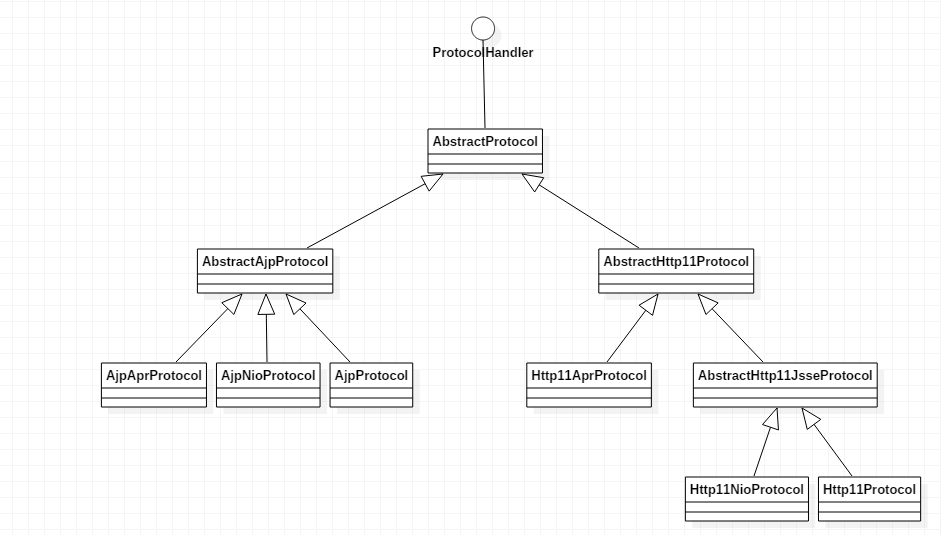
代码中的handler就是AbstractProtocol中的内部类AbstractConnectionHandler的实例,这样,套接字就被传到第②步了。

②、在AbstractConnectionHandler接收到第一步传来的套接字以后,对套接字进行处理,下面是它进行处理的代码。
@SuppressWarnings("deprecation") // Old HTTP upgrade method has been deprecated
public SocketState process(SocketWrapper<S> wrapper,
SocketStatus status) {
//省略部分代码
//这是第三步中Processor接口的实现类。connections是一个Map对象,套接字为键,Processor接口实现类实例为值。
Processor<S> processor = connections.get(socket);
if (status == SocketStatus.DISCONNECT && processor == null) {
// Nothing to do. Endpoint requested a close and there is no
// longer a processor associated with this socket.
return SocketState.CLOSED;
}
wrapper.setAsync(false);
ContainerThreadMarker.markAsContainerThread();
try {
if (processor == null) {
processor = recycledProcessors.poll();
}
if (processor == null) {
processor = createProcessor();
}
initSsl(wrapper, processor);
SocketState state = SocketState.CLOSED;
do {
if (status == SocketStatus.DISCONNECT &&
!processor.isComet()) {
// Do nothing here, just wait for it to get recycled
// Don't do this for Comet we need to generate an end
// event (see BZ 54022)
} else if (processor.isAsync() || state == SocketState.ASYNC_END) {
state = processor.asyncDispatch(status);
if (state == SocketState.OPEN) {
// release() won't get called so in case this request
// takes a long time to process, remove the socket from
// the waiting requests now else the async timeout will
// fire
getProtocol().endpoint.removeWaitingRequest(wrapper);
// There may be pipe-lined data to read. If the data
// isn't processed now, execution will exit this
// loop and call release() which will recycle the
// processor (and input buffer) deleting any
// pipe-lined data. To avoid this, process it now.
//wapper就是套接字包装类的对象,这里还是理解为套接字,套接字在这里传给了第③步的Processor接口的实例。
state = processor.process(wrapper);
}
} else if (processor.isComet()) {
state = processor.event(status);
} else if (processor.getUpgradeInbound() != null) {
state = processor.upgradeDispatch();
} else if (processor.isUpgrade()) {
state = processor.upgradeDispatch(status);
} else {
//注释同上,
state = processor.process(wrapper);
}
if (state != SocketState.CLOSED && processor.isAsync()) {
state = processor.asyncPostProcess();
//省略掉部分代码
} catch(java.net.SocketException e) {
//将部分捕获异常的代码省略掉
// Make sure socket/processor is removed from the list of current
// connections
connections.remove(socket);
// Don't try to add upgrade processors back into the pool
if (!(processor instanceof org.apache.coyote.http11.upgrade.UpgradeProcessor)
&& !processor.isUpgrade()) {
release(wrapper, processor, true, false);
}
return SocketState.CLOSED;
}
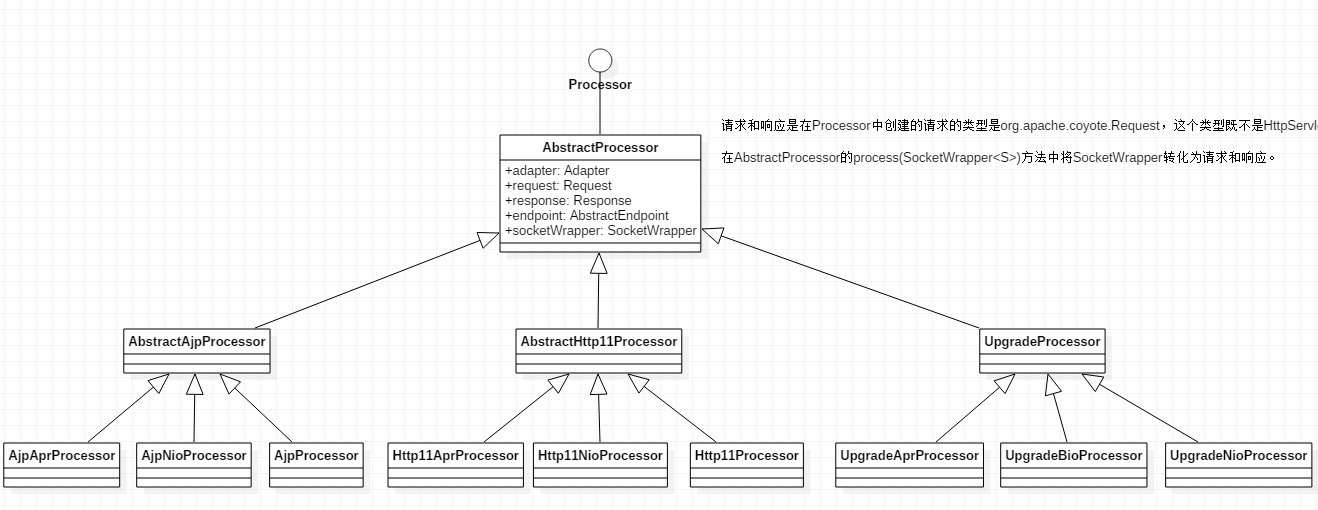
③、第二步完成后,就会交给Processor<S>接口的实现类来处理。在AbstractHttp11Processor中的process(...)方法来处理.部分代码如下:
在这里将会创建请求和响应,但不是我们熟悉的HttpServletRequest或HttpServletResponse类型或其子类型。而是
@Override public SocketState process(SocketWrapper<S> socketWrapper) throws IOException { //省略部分代码 // Process the request in the adapter if (!getErrorState().isError()) { try { rp.setStage(org.apache.coyote.Constants.STAGE_SERVICE);
//请求和响应在这个类中被创建并将套接字中的信息写入的请求中。在这里,请求将会被传递到第④步。
//这个adapter就是CoyoteAdapter的一个实例
adapter.service(request, response); // Handle when the response was committed before a serious // error occurred. Throwing a ServletException should both // set the status to 500 and set the errorException. // If we fail here, then the response is likely already // committed, so we can't try and set headers. if(keepAlive && !getErrorState().isError() && ( response.getErrorException() != null || (!isAsync() && statusDropsConnection(response.getStatus())))) { setErrorState(ErrorState.CLOSE_CLEAN, null); } setCometTimeouts(socketWrapper); } catch (InterruptedIOException e) { //省略部分代码 } }
④、第三步完成之后交给CoyoteAdapter来处理,CoyotoAdapter是将请求传入Server容器的切入点。
我一直不明白coyote是什么意思,有道上说是一种产于北美大草原的小狼。。。感觉不太能理解。所以我把Adapter接口的类注释贴上来,只有一句简单的话,如下:
Adapter. This represents the entry point in a coyote-based servlet container.
CoyoteAdapter中有一个service()方法。这个方法持有一个Connector的引用。这个Connector又持有一个Service容器的引用,而Service容器有持有一个Container(Container的实现类有StandardEngine、StandardHost等等)的引用。所以CoyoteAdapter就可以根据这些引用将请求传递到Server容器中了。如下图中的代码:

还是将CoyoteAdapter的service(...)方法的代码帖出来一下吧。
/** * Service method. */ @Override public void service(org.apache.coyote.Request req, org.apache.coyote.Response res) throws Exception { //下面这两行代码就是将请求处理后转化为HttpServletRequest的 Request request = (Request) req.getNote(ADAPTER_NOTES); Response response = (Response) res.getNote(ADAPTER_NOTES); //如果请求为null就让Connector来创建。 if (request == null) { // Create objects request = connector.createRequest(); request.setCoyoteRequest(req); response = connector.createResponse(); response.setCoyoteResponse(res); //省略部分代码 } if (connector.getXpoweredBy()) { response.addHeader("X-Powered-By", POWERED_BY); } boolean comet = false; boolean async = false; boolean postParseSuccess = false; try { // Parse and set Catalina and configuration specific // request parameters req.getRequestProcessor().setWorkerThreadName(Thread.currentThread().getName()); postParseSuccess = postParseRequest(req, request, res, response); if (postParseSuccess) { //check valves if we support async request.setAsyncSupported(connector.getService().getContainer().getPipeline().isAsyncSupported()); // Calling the container 在这里将请求传到Server容器中。 connector.getService().getContainer().getPipeline().getFirst().invoke(request, response); //省略部分代码 } } /**
⑤、如果上面的请求传递到的Container是StandaradEngine,那么就会Engine就会调用它持有的StandardPipeline对象来处理请求。StandardPipeline就相当于一条管道,这条管道中的有许多阀门,这些阀门会对请求进行处理,并且控制它下一步往哪里传递。StandardEngine的管道使用的阀门是StandardEngineValve。
⑥、和StandardEngine一样,StandardHost、StandardContext、StandardWrapper这几个容器都拥有自己的一条管道StandardPipeline来处理的请求。但是需要注意的是他们使用的阀门是不一样的。StandardHost则会使用StandardHostValve,其他的同理。。。。。。。
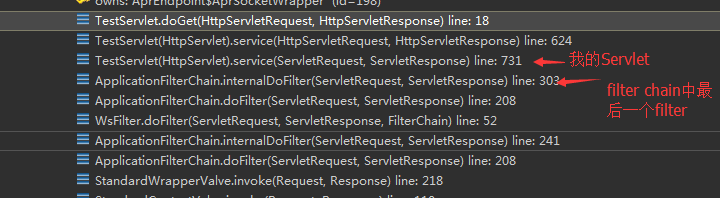
⑦、当最后一个StandardWrapperVale处理完请求后,此时这个请求会如何传递呢??此时请求已经到达了最底层的容器了。StandardWrapper就是最底层的容器,它不允许再有子容器。其实每一个StandardWrapper代表一个Servlet,因为每一个StandardWrapper都会持有一个Servlet实例的引用。阀门会将请求交给谁???看一张图:

这是debug的截图,右上图可知,当最后一个StandardWrapperValve处理完请求以后,把请求交给Filter来处理,此时请求进入过滤器链条中,也就是我们熟悉 filter chain。
⑧、当过滤器处理完之后当然是将请求传递给我们编写的HttpServlet来处理了。
以上就是请求如何,从在服务器的监听端口一步步经过处理和传递到我们自己编写的Servlet的过程。当然过程中有什么错误的地方还望各位大神指出。
本文为GooPolaris原创,转载须附上原文链接:https://i.cnblogs.com/EditPosts.aspx?postid=8115784

 浙公网安备 33010602011771号
浙公网安备 33010602011771号