吴恩达深度学习课程二: 改善深层神经网络 第三周:超参数调整,批量标准化和编程框架(五)框架演示
此分类用于记录吴恩达深度学习课程的学习笔记,目前已完结,点击进入全集目录
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第二课的第三周内容,3.11的内容,也是本周理论部分的最后一篇。
本周为第二课的第三周内容,你会发现这周的题目很长,实际上,作为第二课的最后一周内容,这一周是对基础部分的最后补充。
在整个第一课和第二课部分,我们会了解到最基本的全连接神经网络的基本结构和一个完整的模型训练,验证的各个部分。
之后几课就会进行更多的实践和进阶内容介绍,从“通用”走向“特化”。
总的来说这周的难度不高,但也有需要理解的内容,我仍会在相对较难理解的部分增加更多基础和例子,以及最后的“人话版”总结。
本篇的内容关于框架高效性的演示,本课程这里开始正式引入深度学习的编程框架TensorFlow,并没有理解上的难度,只需要了解相应的语法即可。
1. Tensorflow的高效性
此前的我们的实践主要使用 PyTorch,PyTorch 与 TensorFlow 是目前最主流的两个深度学习框架,使用它们的开发者几乎占到了整个生态的绝大多数。二者虽然起初有一些明显的差别,但随着一代代更新,也越发的相似,并不存在明显的优劣之分。
要提前说明的是,课程中对Tensorflow的演示只限于反向传播部分,用来展示框架的高效性。我们先进行复现,之后再进行一些拓展。
1.1 Tensorflow1.x 的反向传播
这部分我们就复现一下课程的内容。
假设现在有一个损失函数如下:
你可能已经知道这个函数最小时 \(W=5\) 了,现在我们看看通过 Tensorflow 来最小化这个损失函数的过程。
首先还是导库,这段语法我们在课程一第二周的代码实践里已经介绍过了,就不再多提了。
import numpy as np
import tensorflow as tf
然后来看第一步:初始化用于优化和反向更新的变量。
# 1.定义用于反向传播,可以更新的变量
w = tf.Variable(0,dtype = tf.float32)
# 0:初值
# dtype = tf.float32 : 数据类型为32位浮点数
# 你可以直接把它理解为c语言里的 float w =0; 只是在tf里强调为进行反向传播和优化的变量。
然后我们把刚刚的损失函数代码化,这里要说明的一点是,如果你看过原视频,视频里还用了另一种方法来表示,但那种较为繁琐,在实际编码中很少在定义函数中使用,就不展示了。
# 2.定义损失函数
cost = w**2 - 10w + 25
继续,调用梯度下降法来最小化损失函数:
# 3.进行反向传播
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
# GradientDescentOptimizer 直译:梯度下降优化器,实际上,这个方法在更新中已经被移除。
# 0.01 :学习率
# minimize(cost) :类方法,最小化损失函数
现在,我们就可以看看如何开始训练,这里就是tf 的一些固定设置。
要强调一点的是,这种“启动会话”的语法是tensorflow1.x的语法,在2.x的版本中有了更便捷的语法。
但有趣的是这种语法并没有被淘汰,1.x拥有较强的兼容性和稳定性,2.x带来的重构会让很多使用1.x的项目出现bug,因此使用1.x仍是很多人的选择。
# 4.初始化和创建会话
init = tf.global_variables_initializer() # 初始化所有 TensorFlow 变量,固定语法。
session = tf.Session() # 创建一个 TensorFlow 会话,用于执行计算,固定语法。
session.run(init) # 执行初始化操作,初始化图中的变量,固定语法。
print(session.run(w)) # 打印变量 w的值(在初始化之后,它应该是 0.0)。
最后开始训练,打印训练完的参数:
# 5.训练
for i in range(1000):
session.run(train) #进行一千次训练
print(session.run(w))# 打印训练完的w
我们给出完整代码:
import numpy as np
import tensorflow as tf
w = tf.Variable(0,dtype = tf.float32)
cost = w**2 - 10*w + 25
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
print(session.run(w))
for i in range(1000):
session.run(train)
print(session.run(w))
现在,如果像课程里一样使用 tensorflow1.x来运行,你就可以看到w从0到无限接近5的训练效果。
就像课程里这样:
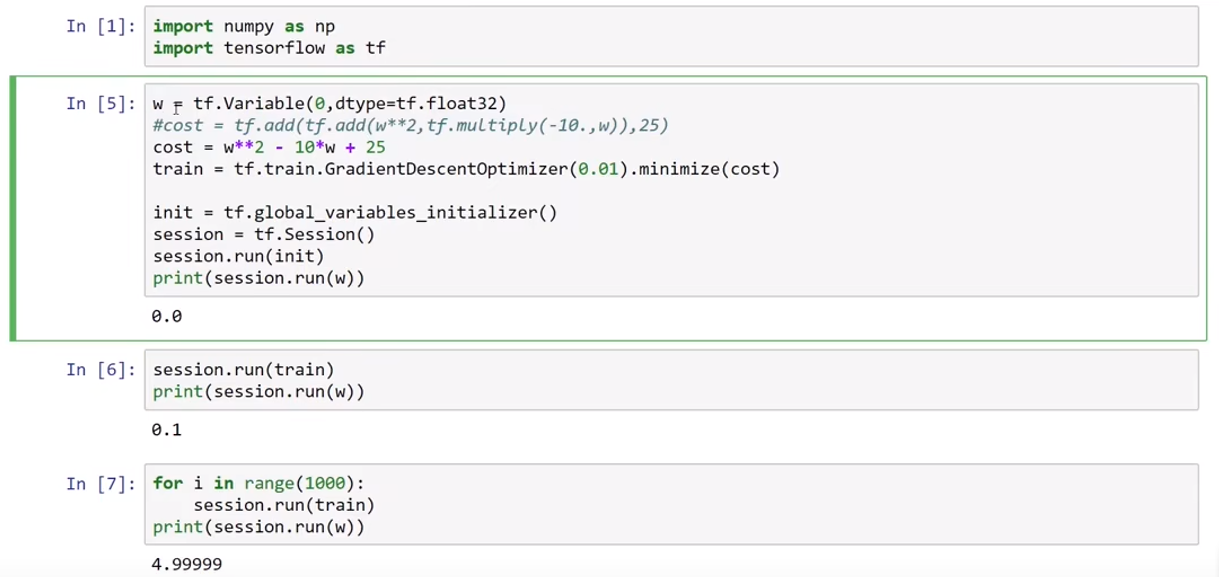
我们没有定义反向传播,没有定义更新公式,没有定义求导方法,这一切都由框架帮我们封装在我们调用的函数里,这就是框架的高效性所在。
1.2 Tensorflow2.x 的反向传播
无论如何,2.x在2019年就已经发布了,虽然1.x仍占有一定份额,但与时俱进仍然是必要的,我们来看看上面的代码在2.x版本里是什么样的。
import tensorflow as tf
# 1. 定义变量 w,通过“.”自动识别为32位浮点型
w = tf.Variable(0.)
# 2.优化器的API替换: GradientDescentOptimizer → SGD
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
# 3.没有会话机制,可以直接打印参数
print(w)
# numpy()是w的数值部分
print(w.numpy())
# 3. 训练循环
for i in range(200):
# GradientTape 是 TF2 的自动求导工具,
# 相当于一个“梯度记录器”:所有在 tape 下发生的计算
# 都会被记录,用来事后求梯度。
with tf.GradientTape() as tape:
# 每次循环都重新计算损失,GradientTape 会追踪计算过程
cost = w**2 - 10*w + 25
# 自动求梯度
# 这一步在 TF1.x 中被封装在minimize(cost)里。
grads = tape.gradient(cost, [w])
# 使用优化器(SGD)根据梯度更新 w
# TF1.x 中 session.run(train) 就在内部完成了这一步。
optimizer.apply_gradients(zip(grads, [w]))
# 4.打印最终 w
print(w.numpy())
其结果如下:
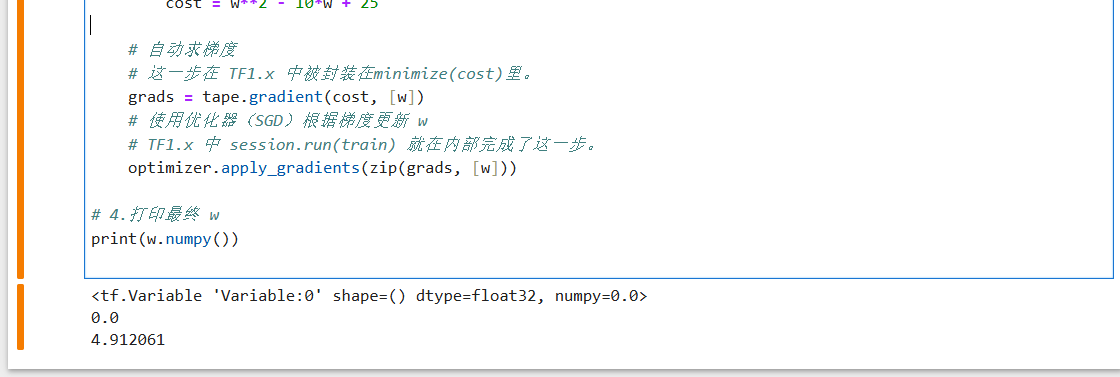
可以看到同样几乎完成了cost的最小化。
很明显,TF的1.x和2.x有了很多API和机制上的不同,这带来了一定程度的“陌生感”。
但无论如何,这种很庞大的,完整的框架都需要一定的学习时间,有一个熟练使用的过程。
2. pytorch 和 Tensorflow
上两部分只是用了一个简单的cost来演示框架在反向传播中的高效性,现在我们已经了解了这一点,我们可以通过调用框架里的模块和方法来简便的完成复杂网络的构建。
现在,我们再对比一下框架间的不同。
还是用我们一直在每周的代码实践部分更新的pytorch框架中的网络结构:
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.hidden1 = nn.Linear(128 * 128 * 3, 1024)
self.hidden2 = nn.Linear(1024, 512)
self.hidden3 = nn.Linear(512, 128)
self.hidden4 = nn.Linear(128, 32)
self.hidden5 = nn.Linear(32, 8)
self.hidden6 = nn.Linear(8, 3)
self.relu = nn.ReLU()
# 输出层
self.output = nn.Linear(3, 1)
self.sigmoid = nn.Sigmoid()
# Xavier初始化输出层
init.xavier_uniform_(self.output.weight)
def forward(self, x):
x = self.flatten(x)
x = self.relu(self.hidden1(x))
x = self.relu(self.hidden2(x))
x = self.relu(self.hidden3(x))
x = self.relu(self.hidden4(x))
x = self.relu(self.hidden5(x))
x = self.relu(self.hidden6(x))
x = self.sigmoid(self.output(x))
return x
如果你看过之前每周的代码实践部分,想必对这段代码并不陌生。
如果你没有这方面的基础也不用担心,这只是使用另一个框架构建的网络结构。
而用Tensorflow来构建这个网络是这样,你会发现二者很相似:
import tensorflow as tf
from tensorflow.keras import layers, models
class NeuralNetwork(tf.keras.Model):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = layers.Flatten()
#1.网络层设置,少了“接水管”过程,会自动适配上一层输出大小。
#2.激活函数改为包含在层参数里。
self.hidden1 = layers.Dense(1024, activation='relu')
self.hidden2 = layers.Dense(512, activation='relu')
self.hidden3 = layers.Dense(128, activation='relu')
self.hidden4 = layers.Dense(32, activation='relu')
self.hidden5 = layers.Dense(8, activation='relu')
self.hidden6 = layers.Dense(3, activation='relu')
self.output = layers.Dense(1, activation='sigmoid')
def call(self, x):
x = self.flatten(x)
x = self.hidden1(x)
x = self.hidden2(x)
x = self.hidden3(x)
x = self.hidden4(x)
x = self.hidden5(x)
x = self.hidden6(x)
x = self.output(x)
return x
model = NeuralNetwork()
# 3.初始化
# 对于 ReLU激活函数,TensorFlow默认使用 He 初始化
# 对于 sigmoid(或者其他饱和激活函数),TensorFlow 默认使用Xavier初始化
initializer = tf.initializers.GlorotUniform()
model.output.kernel_initializer = initializer
在大体结构相似下二者仍有各自的不同之处,因为框架的庞大,本篇展示的只是冰山一角。
总的来说,框架的本质还是使用别人封装好的代码,在了解,学习的基础上,使用什么框架,框架的什么版本都还是应以适合自己为主。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号