
吴恩达深度学习课程二: 改善深层神经网络 第一周:深度学习的实践(一)偏差与方差
此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本周为第二课的第一周内容,就像课题名称一样,本周更偏向于深度学习实践中出现的问题和概念,在有了第一课的机器学习和数学基础后,可以说,在理解上对本周的内容不会存在什么难度。
当然,我也会对一些新出现的概念补充一些基础内容来帮助理解,在有之前基础的情况下,按部就班即可对本周内容有较好的掌握。
1.数据划分
我们在第一课的第二周习题部分就已经简单介绍了训练集,验证集,测试集的概念,这里跟随课程进度,我们再补充一些细节:

这便是一些常用的数据划分方式,此外,在实际应用中,我们还应注意一点,就是训练集和后二者的来源,分布可能不同,这也需要我们有相应的措施,具体看一下:
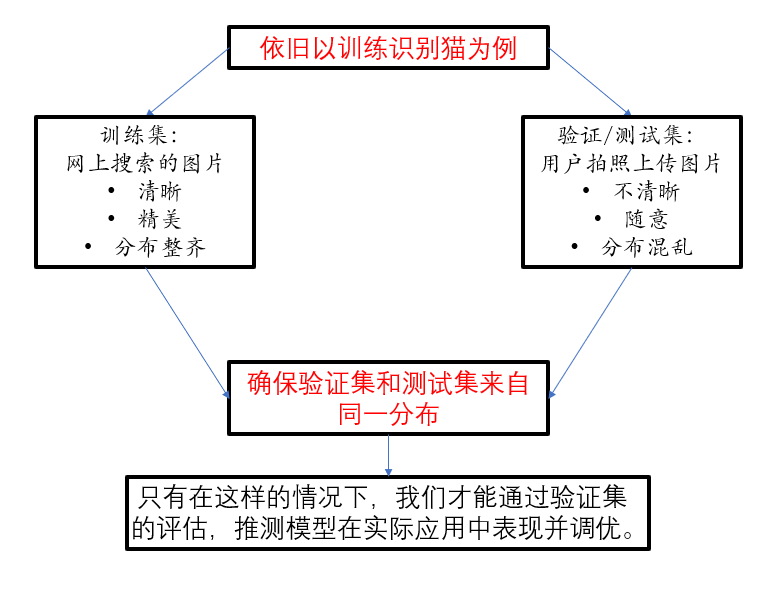
这便是在数据划分部分课程补充的一些内容,接下来我们引入两个新概念:偏差和方差。
2.偏差和方差
2.1 什么是偏差和方差
还是先摆一下概念吧,这事好久没做了:
偏差是指模型的预测值与真实值之间的系统性误差。它衡量的是模型对数据真实规律的拟合能力。
方差是指模型对训练数据中随机噪声或小波动的敏感程度。它衡量的是模型在不同训练集上训练时,其预测结果的不稳定性。
我们用课程里的具体例子来理解一下这两个概念:
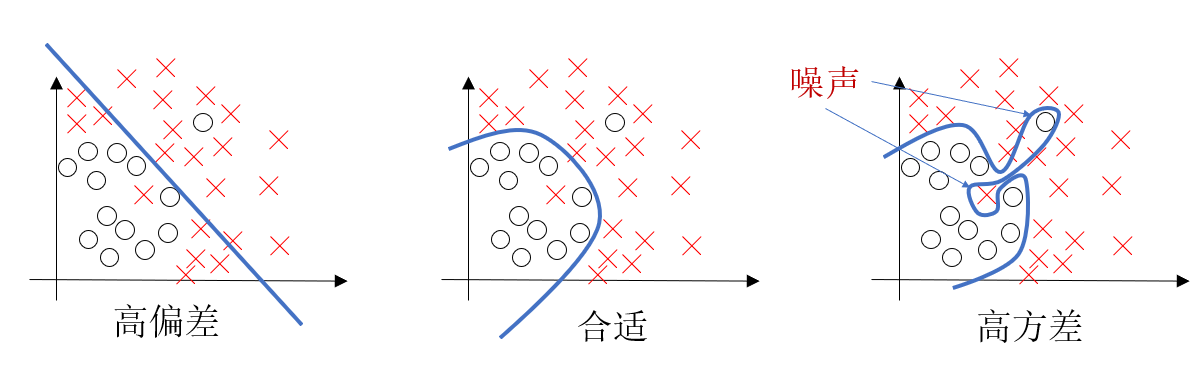
依旧是二分类:
我们先看第一幅图,这里,我们用一条直线来进行分类,很明显,出现了很多被错误分类的样本。
对于这种不能较好的拟合,误差较大的结果,就是高偏差。
高偏差的基本表现就是欠拟合(Underfitting),即在训练集和验证集上的表现都很差。如用一条直线去拟合一组明显呈抛物线分布的数据。
然后再看第三幅图,这里,我们非常准确的区分了每一个样本。
但是要注意,我们观察发现,在图中,有两个样本偏离了大部分该类样本的位置。
对于这种变异的,无法正确反应类别规律的样本数据,我们就称为噪声。
而在第三幅图中,我们的模型敏感度较高,为了拟合这两个无法正确反应规律的样本,反而降低了最终的准确率,这种过于敏感以至于拟合噪声导致性能下降的结果,就是高方差。
高方差的基本表示就是过拟合(Overfitting),即在训练集上表现很好,但在验证集或测试集上表现很差。就像一个非常复杂的神经网络,完美记住了训练数据的所有点(包括噪声),反而会对新数据泛化能力极差。
而我们在第二份图标注合适的原因,就是因为它做到了拟合大部分数据的规律实现低偏差,又没有被噪声干扰偏离正确规律从而实现低方差。
低偏差和低方差,就是我们追求的模型目标。
2.2 从数据分析偏差和方差高低
现在,我们已经知道了偏差和方差的概念,而在实际代码运行中,我们则需要从代码的结果,即评估指标来判断这两点,来继续看猫狗分类的例子,我们从代码结果上看看如何分析偏差和方差的高低。

简单来说:
偏差高低就看数据在训练集上的表现好不好。
方差高低就看数据在训练集和验证集上的差别大不大。
此外,并不是说只有0.5%或以下才是低方差或者低误差。
这涉及到一个基本误差的概念:我们人眼判断错误的概率。
假设我们人眼只有1%的概率会错误分类猫狗,那我们的方差和偏差的高低标准就会以1%为标准判断。
基本误差根据任务不同,自然也不同。
等等,好像还有一点不太清晰。
我们刚刚引出概念的时候谈到,高偏差的表现是欠拟合,高方差的表现是过拟合,但从二者的定义上来看,欠拟合和过拟合不是冲突的吗?那为什么高偏差和高方差可以同时存在呢?
对于这个问题,从表面上看:
- 高偏差 → 欠拟合(模型太简单,对规律学得不够)
- 高方差 → 过拟合(模型太复杂,对噪声学得太多)
似乎一个模型“学的不够”,另一个“学的太多”,那怎么可能又多又少?
问题就在于——我们用“表现”来简化这两个概念,但其实它们真正反映的是模型表现的两个不同维度。
举一个飞镖的例子 : - 每次都扔偏了靶心(高偏差);
- 而且每次落点都不一样(高方差)。
这就是“又不准又不稳”的情况,即 高偏差 + 高方差同时存在。
其次,欠拟合和过拟合都可以是局部的,我们可能在图像某一区域发生了欠拟合,又在另一区域发生了过拟合,从这个角度看,即 欠拟合 + 过拟合同时存在。
这样便可以比较好的回答这个问题。
2.3 如何调整偏差和方差
现在我们已经知道如何判断算法的偏差和误差情况了,那相应的,采取什么样的措施才能调整二者,从而实现算法的调优呢?
总结成一张图如下:

这是一些基本措施。
要说明的一点是,方差和误差往往是联动的,我们的一些措施往往会同时增加或减少二者,用什么算法,什么样的超参数等等都会产生影响,而随着技术的发展,才出现了可以单独影响二者之一的新方法技术,我们遇到再说。
总结来说,构建更大,更复杂的网络往往能起到更好的效果,但实际上,在这方面,目前并没有数学概念上的“最优解”,即可以在所有问题上实现最好效果的架构或算法。
这便是为什么我们往往把训练模型称为“炼丹”的原因,我们需要一点点,一步步地调试,来摸索出针对自己的问题效果最好的模型,有些时候,我们自己也不知道为什么某样组合能达到更好的效果。
这便是本篇的内容,下一篇,我们就会介绍到刚刚的图里新出现的概念:正则化,它可以帮我们缓解过拟合的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号