【深度学习项目】基于改进Bert模型的夸夸聊天机器人(1)数据预处理篇
项目概述
该项目构建一个基于UniLM的生成式夸夸bot
UniLM 是在微软研究院在BERT的基础上,最新产出的预训练语言模型,被称为统一预训练语言模型
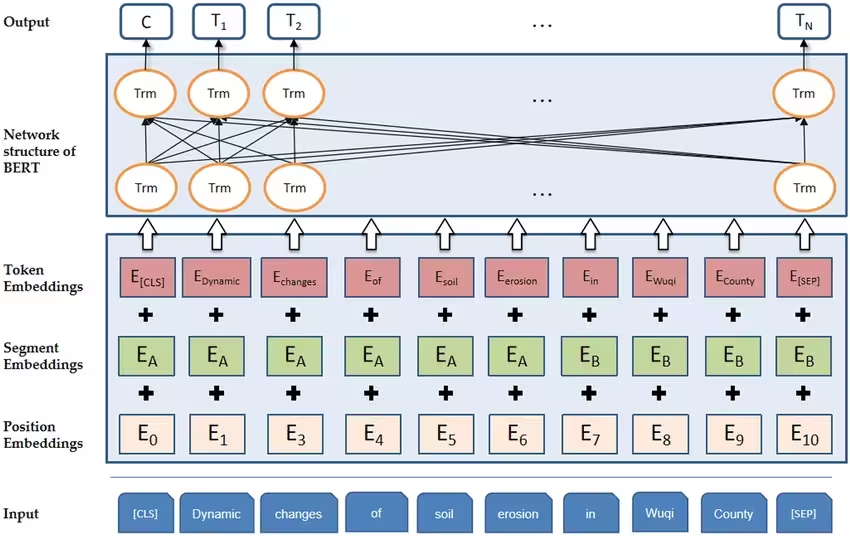
bert结构如下:
bert只含有双向语言模型
UniLM结构如下:
UniLM的框架与bert一致,不同之处在于训练方式,UniLM需要联合训练三种不同目标函数的无监督语言模型,U能够同时完成三种预训练目标,包括:双向语言模型、单向语言模型、序列到序列语言模型
包括三个嵌入层:词嵌入层、位置嵌入层、段嵌入层
特点:三种不同训练目标共享网络参数;
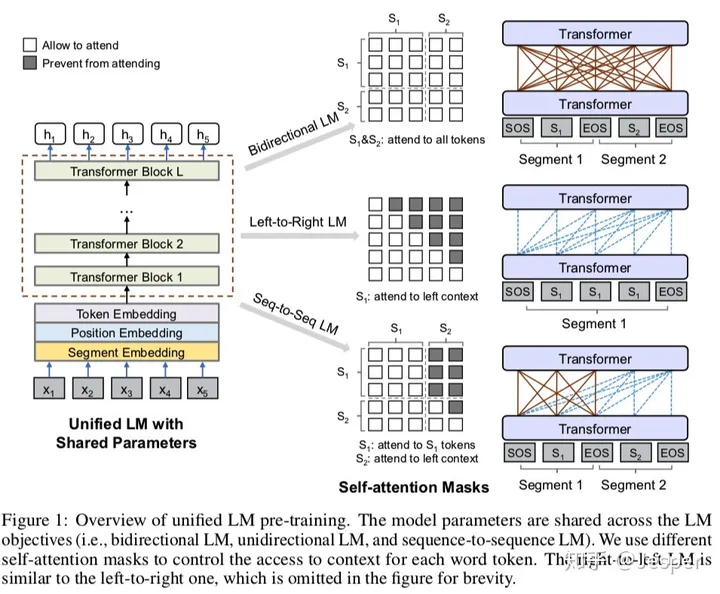
Unified LM with Shared Parameters:共享参数的统一语言模型
attend to S1 tokens:注意力掩码
segment:段落
参考:https://www.bilibili.com/read/cv30133428/
https://zhuanlan.zhihu.com/p/392188520
https://blog.csdn.net/m0_72947390/article/details/134891154
https://www.pianshen.com/article/6859880160/
数据预处理
该步骤包含数据清洗、敏感词过滤和格式转换,转换成适合模型训练的数据,如:
{"src_text": "要去打球赛了", "tgt_text": "全场最帅(・ัω・ั)卡胃踩脚拇指戳肋骨无毒神掌天下无敌,然后需要代打嘛"}
{"src_text": "要去打球赛了", "tgt_text": "是篮球哈哈哈"}
{"src_text": "要去打球赛了", "tgt_text": "我不,我还想问问什么鞋码,多高多重,打什么位置的"}
数据爬取
原始数据来源于豆瓣夸夸组,爬取后的数据预览如下:
Q: 春天好好生长,打卡卡卡
A: 一个人好好过也棒棒的,不着急也可以找到合适的(*¯︶¯*)
Q: 春天好好生长,打卡卡卡
A: 嗯呀我也准备最近好好生活啦不想感情的事情了
Q: 春天好好生长,打卡卡卡
A: 居然坚持了一天,好友毅力,点赞
Q: 春天好好生长,打卡卡卡
A: 哈哈哈哈哈哈哈哈一天都能被夸你是小天使吗
数据清洗
构建敏感词字典树
该步骤用于去除语料中的敏感词
导入敏感词语料,将其构建为一个字典树
- 定义一个字典树类
class Trie:
def __init__(self):
self.root = {} #根节点
self.end="#"
# 构建字典树
def insert(self,word):
curNode = self.root
for c in word:
if not c in curNode: # 如果当前结点的分支没有字符,或该字符不在当前结点的分支里,则添加该子节点
curNode[c] = {}
curNode=curNode[c] #更新节点,将子节点作为当前结点
curNode[self.end]=True
# 查找单词
def search(self,word):
curNode = self.root #从根节点开始查找
for c in word:
if not c in curNode: return False # 如果字符不在当前结点里,退出循环
curNode=curNode[c] # 如果单词在结点里
if not self.end in curNode:
return False
return True
def startsWith(self,pcurNodeix):
curNode = self.root
for c in pcurNodeix:
if not c in curNode: return False
curNode=curNode[c]
return True
def get_start(self,prefix):
def _get_key(pre,pre_node):
words_list=[]
if pre_node.is_word:
words_list.append(pre)
for x in pre_node.data.keys():
words_list.extend(_get_key(pre + str(x), pre_node.data.get(x)))
return words_list
words=[]
if not self.startsWith(prefix):
return words
if self.search(prefix):
words.append(prefix)
return words
node=self.root
for letter in prefix:
node=node.data.get(letter)
return _get_key(prefix,node)
def enumerateMatch(self,word,space=""):
matched=[]
while len(word)>1:
if self.search(word):
matched.append(space.join(word[:]))
del word[-1]
return matched
- 实例化字典树,定义一个去除敏感词的类,该类包括读取敏感词语料、构建敏感词字典树、获取语句中的敏感词汇
from trie import Trie
class dirty_reg():
def __init__(self, path):
self.trie = Trie()
self.build(path)
def insert_new(self, word_list):
word_list = [word.lower() for word in word_list] # 10八 转换为['1', '0', '八']
self.trie.insert(word_list)
def build(self, path):
# 读取文本
f = open(path, "r", encoding='utf-8')
for line in f:
line = line.strip()
if line:
self.insert_new(line) # 对每个词汇建立字典树
def enumerateMatchList(self, word_list):
word_list = [word.lower() for word in word_list]
match_list = self.trie.enumerateMatch(word_list)
return match_list
def match(self,query):
al=set()
length=0
for idx in range(len(query)):
idx=idx+length
match_list = self.enumerateMatchList(query[idx:])
if match_list==[]:
continue
else:
match_list=max(match_list)
length=len("".join(match_list))
al.add(match_list)
return al
去除不相关问题和回答
去除行数据含有'...'的问题和'谢谢'的回答
if '...' in q or '谢谢' in a:
continue
去除敏感词
# 判断句子是否包含敏感词
def remove_sensitive(dirty_obj, sentence):
if len(dirty_obj.match(sentence)) == 0:
return False
else:
return True
去除HTML标签
def remove_html(text):
pattern = r'<[^>]*>'
text = re.sub(pattern, '', text).replace('\n', "").replace(" ", "")
return text
去除标点符号
# 去除连续标点
def remove_multi_symbol(text):
'''
:param text:
:return:
'''
r = re.compile(r'([.,,/\\#!!??。$%^&*;;::{}=_`´︵~()()-])[.,,/\\#!!??。$%^&*;;::{}=_`´︵~()()-]+')
text = r.sub(r'\1', text)
return text
去除emoji
def remove_emojis(text):
'''
:param text:
:return:
'''
emoji_pattern = re.compile("["u"\U0001F600-\U0001F64F"
u"\U0001F300-\U0001F5FF"
u"\U0001F680-\U0001F6FF"
u"\U0001F1E0-\U0001F1FF"
"]+", flags=re.UNICODE)
text = emoji_pattern.sub(r'', text)
return text
去除夸夸词
s = ["大家来留言吧!我来夸你们", "求表扬", "有人夸我吗", "求安慰", "求祝福", "能被表扬吗", "求夸奖", "求鼓励",
"来表扬我一下好吗", "求夸", "我好棒啊", "球表演", "求彩虹屁", "快来夸我嘛", "快来夸夸我", "再来夸一次哈哈"]
for s_ in s:
q=q.replace(s_,"")
过滤长度,转换格式
data_dict={}
# 过滤长度较小的数据
if len(q)<=4 or len(a) <=4:
continue
else:
if q not in data_dict:
data_dict[str(q)] = set()
data_dict[str(q)].add(a)
else:
data_dict[str(q)].add(a)
# 保存成模型训练所需要的数据格式
fin = open(save_path, "w", encoding="utf-8")
for key in data_dict.keys():
for value in data_dict[key]:
fin.write(json.dumps({"src_text": key, "tgt_text": value}, ensure_ascii=False) + "\n")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号