


1、 w或者uptime都可以直接展示负载
$uptime
09:32:14 up 695 days, 23:42, 2 users, load average: 0.00, 0.01, 0.05
$w
09:32:00 up 695 days, 23:42, 2 users, load average: 0.00, 0.01, 0.05
其中load average分别对应过去的1分钟、5分钟、15分钟的负载均衡值
2、top 查看服务器负载均衡
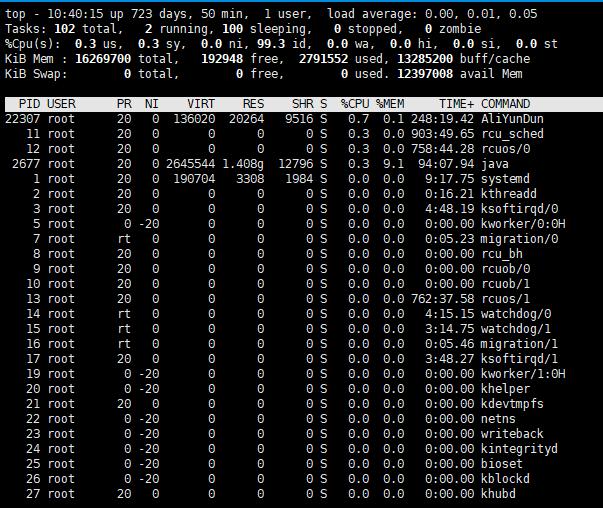
top 指令能够清晰的展示出系统的状态,而且是实时监控的 q:退出
Tasks 行展示的是目前的线程使用情况,要注意的是zombie,表示僵尸进程,不为0则表示有进程出现问题
Cpus 行展示了当前的CPU状态,us标识用户进程占用的cpu比例,sy代表内核进程占用的比例,id表示空闲的CPU百分比
wa代表IO等待所占用的CPU时间的百分比,wa占用超多30%则表示IO压力大
Mem 当前内存的状态,total标识总共的,free代表剩余的,used代表已使用的 buffers是目录缓存
Swap行同Mem行,cached表示缓存,用户已打开的文件。如果Swap的used很高,则表示系统内存不足。
top下的指令:
1(指令):查看服务器有多少CPU,以及每个CUP的使用情况,一般情况下,服务器的合理负载是CPU核数*2,超过了就说明服务器的运行有一定的压力
shift + "c" :进程按CPU使用率从大到小排序
shift + "p" : 进程按内存使用率从大到小排序
3、 iostat命令

top命令是不够的,因为它仅能展示CPU和内存的使用情况,对于负载的另一个原因IO没有清晰明确的展示
iostat可以了解IO的开销
指令:iostat -x 1 10 -x表示显示所有参数的信息,1表示每隔1秒监控一次,10 表示共监视10次
其中:rsec/s (r/s)表示读入,wsec/s (w/s)表示每秒写入,两个参数某一个表示磁盘IO有很大压力,util表示IO使用率,如果接近100%,表示IO满负载运转。
4、 相关指令:
a、 查看磁盘:
df -h , df 命令用于显示磁盘分区上的可使用磁盘空间。默认单位是kb -h 使用-h选项以KB以上的单位来显示,可读性高
b、 查看内存大小:
free -h / free -m

其中 used - buff/cache 反应的是被程序真真实实吃掉的内存
而 free + buff/cache 反应的是可以挪用的内存总数
c、 查看cpu
cat /proc/cpuinfo 读取cpu内存详情
grep "model name" /proc/cpuinfo | wc -l 读取cpu个数
d、 查看系统内存
cat /proc/meminfo ------------------------------------proc 文件下边记录着很多cpu、内存信息
e、 查看每个进程的情况
cat /proc/5346/status 5347是pid ----------------proc 文件下边有很多都是进程的记录
f、 查看复杂
w / uptime
g、 查看查看服务器负载情况
top
5、性能监视sar指令
sar -u : 显示cpu信息,-u 是sar的默认选项,改输出以百分比显示cpu的使用情况
sar 5 10 : sar 以每5秒间隔取得10次样本
sar -n { DEV | EDEV | NFS | NFSD | SOCK | ALL } :sar 提供6中不同的语法来显示信息
6、查看命令历史(含时间戳)
这个很重要,可以查看历史的指令,来学习指令
export HISTTIMEFORMAT='%F %T ';history| more
7、查看文件夹和文件的大小
du -h --max-depth=0 dm 查看dm目录大小
du -h --max-depth=1 dm 查看dm目录大小,以及dm各文件文件夹的大小
du -h --max-depth=0 查看当前文件夹大小
8、linux 负载高,主要是CPU的使用、内存的使用、IO消耗三部分。
9、查询linux 负载高,检查
a、w 或者 uptime 来展示负载

load average 分别对应过去1分钟、5分钟、15分钟的负载平均值
load :是计算机干活多少的度量(WikiPedia:the system Load is a measure of the amount of work that a compute system is doing)
简单的说就是进程队列的长度。loand average 就是一段时间(1分、5分、15分)内的平均Load
如何判断系统是否已经over Load :
对一般的系统来说,根据cpu数量去判断。如果平均负载始终在1.2以下,而你有2颗cup的机器。那么基本不会出现cpu不够用的情况。
也就是Load平均要小于Cpu的数量,一般是会根据15分钟那个load 平均值为首先。
b、 top 来查看服务器负载
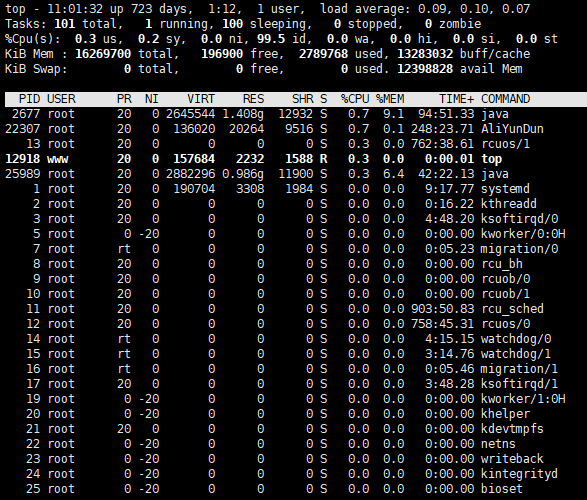
Tasks行展示了目前的进程总数及所处状态,要注意zombie,表示僵尸进程,不为0则表示有进程出现问题。 ------关注 zombie
Cpu(s)行展示了当前CPU的状态,us表示用户进程占用CPU比例,sy表示内核进程占用CPU比例,id表示空闲CPU百分比,
wa表示IO等待所占用的CPU时间的百分比。wa占用超过30%则表示IO压力很大。 --------关注 wa
Mem行展示了当前内存的状态,total是总的内存大小,userd是已使用的,free是剩余的,buffers是目录缓存。
Swap行同Mem行,cached表示缓存,用户已打开的文件。如果Swap的used很高,则表示系统内存不足。 -----关注swap
在top命令下,按1,则可以展示出服务器有多少CPU,及每个CPU的使用情况
shift + "c" : cpu 使用率从大到小排序
shift + "p" 内存使用率从大到小排序,结合使用很容易定位那些服务使用了较高的CPU和内存。
c、iostat 来查看io开销

其中rsec/s表示读入,wsec/s表示每秒写入,这两个参数某一个特别高的时候就表示磁盘IO有很大压力
util表示IO使用率,如果接近100%,说明IO满负荷运转。
10、查看系统的负载情况
$ vmstat

r 列表示运行和等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu。
b 列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。 cpu 表示cpu的使用状态
us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,
这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
id 列显示了cpu处在空闲状态的时间百分比 system 显示采集间隔内发生的中断数
in 列表示在某一时间间隔中观测到的每秒设备中断数。
cs列表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
swpd 切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free 当前的空闲页面列表中内存数量(k表示) buff 作为buffer cache的内存数量,一般对块设备的读写才需要缓冲
cache: 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。 si 由内存进入内存交换区数量。 so由内存交换区进入内存数量。 IO
bi 从块设备读入数据的总量(读磁盘)(每秒kb)。 bo 块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析
11、Load误解
a:系统load高一定是性能有问题。
真相:Load高也许是因为在进行cpu密集型的计算
b:系统Load高一定是CPU能力问题或数量不够。
真相:Load高只是代表需要运行的队列累计过多了。但队列中的任务实际可能是耗Cpu的,也可能是耗i/0及其他因素的。
c:系统长期Load高,首先增加CPU
真相:Load只是表象,不是实质。增加CPU个别情况下会临时看到Load下降,但治标不治本。
d:在Load average 高的情况下如何鉴别系统瓶颈。
是CPU不足,还是io不够快造成或是内存不足?
12、jdk自带的有用的工具
jsp :罗列出目前再服务器上运行的java程序及进程ID 有的时候(tomcat)不好用,所以一般使用 ps -ef|grep java 来查找
jstat :用于输出java程序内存使用情况,包括新生代、老年代、元数据区容量、垃圾回收的情况
jstat -gcutil 1133 2000 2 :1133 是java的进程 2000毫秒执行一次 执行两次
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
96.12 0.00 57.37 64.03 98.39 96.87 42 0.530 3 0.335 0.865
96.12 0.00 57.37 64.03 98.39 96.87 42 0.530 3 0.335 0.865
S0:幸存1区当前使用比例
S1:幸存2区当前使用比例
E:伊甸园区使用比例
O:老年代使用比例
M:元数据区使用比例
CCS:压缩使用比例
YGC:年轻代垃圾回收次数
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
jmap :用于输出java程序中内存对象的使用情况,包括那些对象,对象的数量
jmap -histo 3618
一般我们都进行打印数据的:jmap -dump:live,format=b,file=heap.hprof 3618
jstack:用户输出java程序线程栈的情况,常用于定位因为某些线程问题造成的故障或性能问题。
jstack 3618 > jstack.out
上述命令将进程ID为3618的栈信息输出到外部文件,便于传输到windows电脑上进行分析
导出查看分析线程waiting 的原因
13、windows 有一个 jvisualvm.exe 软件
就在在JDK安装目录下的bin目录下面,双击即可打开
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号