YoutubeDNN 文章个人解读
CTR 代码仓
1、deepctr, deepmatch, graph_embedding https://github.com/shenweichen
2、腾讯信息流代码库 https://www.showmeai.tech/article-detail/64
3、https://github.com/wziji/deep_ctr
4、EGES https://github.com/wangzhegeek/EGES https://zhuanlan.zhihu.com/p/110442164
5、https://zhuanlan.zhihu.com/p/96338316
6、https://github.com/large-scale-recsys-in-action/large-scale-recsys-in-action # 来自书籍 《大规模推荐系统实战》
7、https://github.com/kangshantong/ps-dnn # 来自书籍 《检索匹配-深度学习在搜索、广告、推荐系统中的应用》
8、DIN https://github.com/zhougr1993/DeepInterestNetwork
9、DIEN https://github.com/mouna99/dien
10、https://github.com/recommendation-algorithm/FiBiNet
YoutubeDNN 来自 Google 16年的经典论文《Deep Neural Networks for YouTube Recommendations》
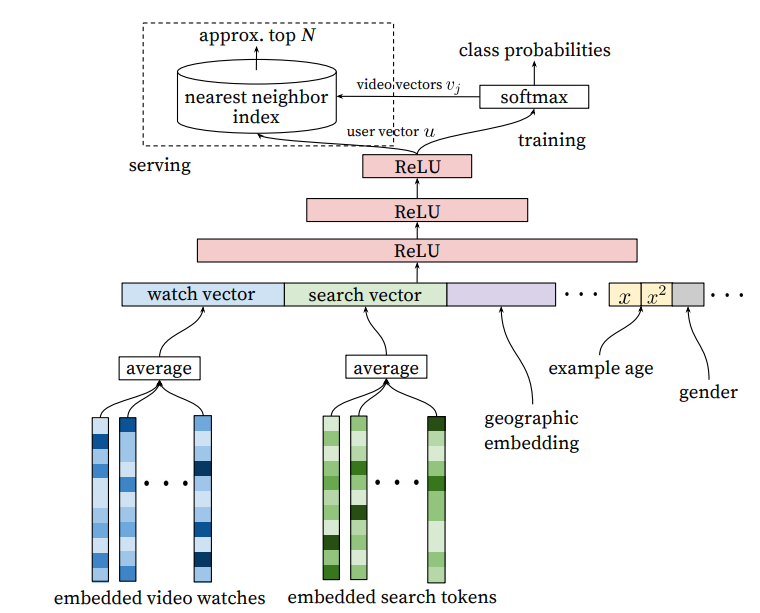
- Candidate Generation(召回阶段) 完成候选视频的快速筛选,这一步候选视频集合由百万降低到了百的量级
-
注意到这一步骤对应的是多分类任务(全库商品都要进行打分):输入是用户的历史行为的embedding向量 和 搜索词的embedding向量(对应到搜索任务),不同于精排阶段(二分类任务)(存在候选 target item, 逐个对候选 target item 进行打分,因此输入中包括候选 item )。对于这一多分类任务,每一类代表一个 item, softmax 层的矩阵 \(V\) 则相当于每个类的类模板,也可以看做是每个 item 的 embedding vector, 但学习到这个 embedding vector 只使用到标记信息,却没有显式利用到该 item 的信息。
-
这与传统的机器学习多分类任务形成了鲜明对比,例如,对于 CIFAR-100 数据集分类,输入是 \(\{(x_i, y_i)\}\), 其中 \(x_i\) 是 \(y_i\) 所对应类的一个实例(例如一张 cat 的图片),两者强相关,或者说 \(x_i\) 定义了 \(y_i\) 所代表的事物。而对于召回所对应的多分类任务,输入是 \(\{([a_i, b_i], y_i)\}\), 我们给 \([a_i, b_i]\) 打上 label \(y_i\) 表示在用户历史行为 \(a_i\)、输入搜索词 \(b_i\) 下,(当把 \(y_i\) 对应的 item 呈现给用户时), 用户对 \(y_i\) 对应的 item 产生了交互作用。但由于用户兴趣的多样性、传递性等, \([a_i, b_i]\) 与这一 item 可能只有隐式的关联(弱相关),没有显式的关联(强相关)。
-
在线推断时,为了速度的考虑,冒着牺牲少许精度的风险,直接使用 ANN 索引的方法,在 \(\{\mathbf v_i\}\) 中搜索与用户 embedding vector \(u_j\) 最接近的一些向量。考虑到 softmax 函数的计算方式,\(p(y_i|x) = \frac{\exp(v_i^\top f(x)+b_i)}{\sum_j\exp(v_j^\top f(x)+b_j)}\),当 \(p(y_i|x)\) 很大时,\(\exp(v_i^\top f(x)+b_i)\) 也很大, 忽略 \(b_i\) 项,则相当于内积 \(v_i^\top f(x)\) 很大,若限制模长几乎一致,则也相当于 \(\|v_i-f(x)\|_2\) 很小,因此可以使用近邻检索方法。使用近邻检索方法,主要是为了提高召回阶段的速度,近邻检索这个领域在学术界和工业界都有大量研究,可以把对近邻检索的优化都用上去,并行处理全库所有 item (\(O(\log n)\) 复杂度), 如此则比起逐个计算 \(p(y_i|x)\) 值(\(O(n)\) 复杂度)再进行排序要快上无数倍。
-
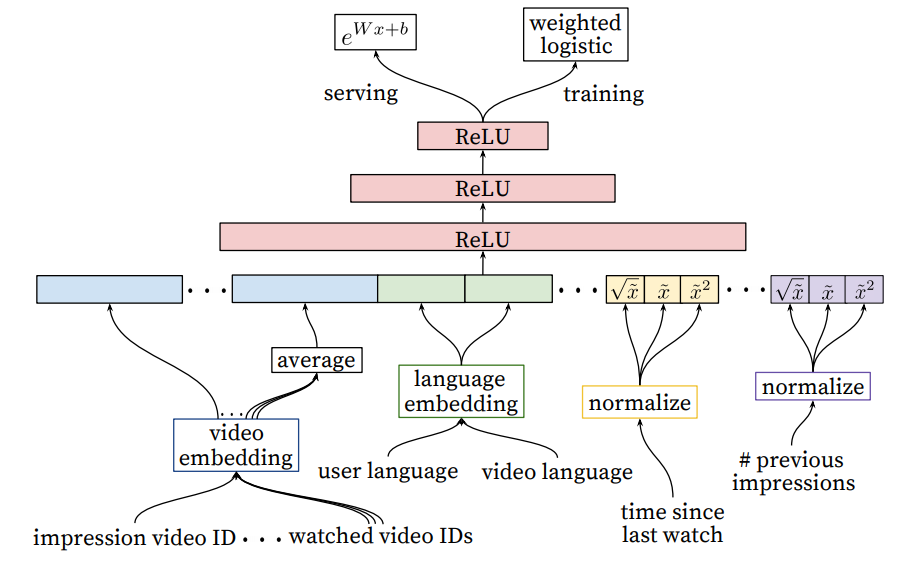
- Ranking Model(排序阶段)完成几百个候选视频的精排
- 排序模型较为简单常见,但对于训练数据和特征都做了一些结合业务场景的相应处理。
- 对模型的训练和服务过程进行了一些处理,以更加适合于视频推荐的业务场景。训练时使用 weighted LR 进行加权处理, 模型服务时使用 \(exp(Wx+b)\) 而并非 \(p(y|x)\) 来给出预测用户播放时长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号