详解 SVM 对偶问题与 KKT 条件--以《统计学习方法,第二版》为例
《统计学习方法,第二版》第七章 支持向量机的原问题
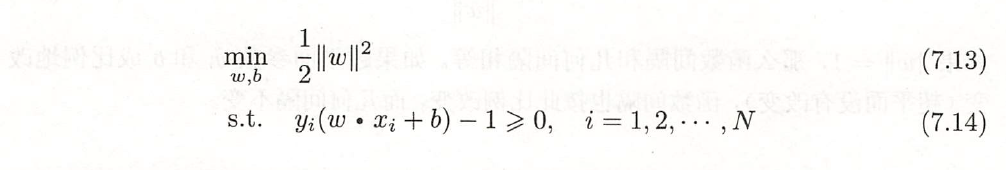
李航老师在书上对 SVM 的原问题推导出其对应的对偶问题的推导过程有些简略, 其直接令导数为 0, 得到公式 (7.19)+(7.20)。虽然最终结果正确,但内在的分析没有揭示出来。
推导对偶问题的过程涉及到 Lagrange 函数,Lagrange 对偶函数,Lagrange 对偶问题,直接令梯度为 \(0\), 其实是省略了中间过程。
下面针对于上面图片中的不带松弛变量的原问题来具体展示对偶问题的推导过程。
如果理解了下面的对偶问题的推导过程,相信对加了松弛变量的 SVM 原问题 (7.32) + (7.33) + (7.34) 的对偶问题的推导也会比较容易,有兴趣的读者可以作为习题尝试一下以加深理解。
以下是个人的一些浅显理解,如果有错误欢迎指出。
原问题 (7.13 + 7.14):
记 (7.13)+(7.14)解为 \(p^*\) .
我们先来引入Lagrange 乘子 \(\alpha_i\), 构造 Lagrange 函数(Lagrange function):
注意到, 设 \((w,b)\) 满足(7.14)中的条件,则当 \(\alpha_i\ge 0, i=1,2,\dots, N\) 时,有:
于是我们有:
当 \(\alpha_i\ge 0\,\) 时,\(\quad \min_{w, b}L(w,b,\alpha)\le\min_{w, b \,\text{满足(7.14)}}\quad\quad L(w,b,\alpha) \le \min_{w, b \,\text{满足(7.14)}}\quad\quad \frac{1}{2}\|w\|^2 = p^*\)
注意到,这里丢弃了条件(7.14)使得 \((w, b)\) 的取值范围更大,所以取 \(\min\) 后值更小。
到了这里就可以定义 Lagrange 对偶函数 \(F(\alpha) \triangleq \min_{w, b} L(w, b, \alpha)\) , 注意到这一函数中自由变元只有 \(\alpha\) , 而 \(w\) 和 \(b\) 是我们需要通过 \(\min\) 来消去的。
我们下面先来重写一下 \(L(w, b, \alpha)\)
可以看到中括号里的前两项是关于 \(w\) 的二次凸函数,有下界; 第三项是关于 \(b\) 的一次函数,没有下界。现在 \(w\) 的取值范围是 \(\mathbb R^n\), \(b\) 的取值范围是 \(\mathbb R\), 先考虑消去变元 \(b\) :
注意到 \(\sum_{i=1}^N\alpha_iy_i = 0\) 碰巧对应了:令对 \(b\) 的偏导数为 \(0\)。
进一步,消去变元 \(w\),这一消去依赖于二次可微凸函数取极小值的必要条件(也是充分条件), 偏导数为 \(0\),将对 \(w\) 的偏导数为 \(0\) 对应的等式代入化简,可得:
于是我们有 Lagrange 对偶函数可以写为如下形式:
我们知道,当 $\alpha_i \ge 0 $时, \(F(\alpha) \le p^*\) , 也即, \(F(\alpha)\) 是 \(p^*\) 的一个下界。最松的下界当然是 \(-\infty\), 我们通常想要找一个最紧的下界,这就引出了 Lagrange 对偶问题:
$$ \max_{\alpha \ge 0} F(\alpha) $$
由于已经求出了 \(F(\alpha)\) 的表达形式, \(-\infty\) 不是我们期望的结果,也不是 \(\max_{\alpha \ge 0}\) 所对应的值,因此我们可以进一步化简,得到如下形式的对偶问题 (下面将 \(\alpha\ge 0\) 放到了约束条件里):
至此,对偶问题推导完毕。
总结一下:
- 在上述推导中,对 \(w\) 的偏导数为 \(0\) 和 对 \(b\) 的偏导数为 \(0\) 的内在逻辑是不一样的。
- 在推导对偶问题时,我们需要求出 Lagrange 对偶函数 \(\min_{w, b} L(w, b, \alpha)\) 。在 SVM 问题以及机器学习中一些其他常见的问题中,这恰好等价于令对 \(w\) 的偏导数为 \(0\),令对 \(b\) 的偏导数为 \(0\)。但是对于其他问题,我们需要细致分析 \(L(w, b, \alpha)\) 对于 \(w\) 和 \(b\) 的函数关系,才能得到 \(F(\alpha) = \min_{w, b} L(w, b, \alpha)\) 的简化过程,并且在复杂问题中,这一简化过程可能很困难。
- 上述推导只针对于原问题中出现不等式约束,如果还有等式约束,对应于等式约束的对偶变量对应的限制条件稍微有些不同,具体可参见参考文献 [1].
为了完整性,下面再来介绍一下 KKT 条件及其意义:
KKT 点指满足下面 KKT 条件的点 \((w^*, b^*, \alpha^*)\):
- primal variable feasibility 对应于原问题变量可行,也就是原变量所需满足的约束条件
- dual variable feasibility 对应对偶问题变量可行,也就是对偶变量所需满足的条件。其中条件 \((w^*, b^*) = \min_{w, b} L(w, b, \alpha^*)\) 是在推导 Lagrange 对偶函数时引入的,常常可以简化为 \(\nabla_w L(w^*, b^*, \alpha^*) = 0\) 和 \(\nabla_b L(w^*, b^*, \alpha^*) = 0\)。但若是碰到了不能简化的情况,需要保留这一原始条件。
- complementary slackness 对应于互补松弛条件,也就是 Lagrange 函数中,由于对偶变量所引入的那一部分。这一部分需要全部等于 \(0\) 可以这样理解, 对于最优解,必然有: \(F(\alpha^*) = L(w^*, b^*, \alpha^*) = p^* = \frac{1}{2}\|w^*\|^2\), 这就要求 \(\sum_{i=1}^N \alpha_i^*(y_i(w^*\cdot x_i+b^*)-1)) = 0\) ,又由于每一项都有 \(\alpha_i^*(y_i(w^*\cdot x_i+b^*)-1))\ge 0\) , 故必须每一项都为 \(0\).
KKT 点的意义:
- 一般来说,当问题没有凸性保证时,KKT点通常是能够获得的最接近于最优解点的结果。而当问题为凸优化问题且满足 Slater 条件时,KKT点即为最优解点。
- 由于此问题中 primal problem 为凸优化问题且满足Slater条件,故其 KKT 点恰为原问题和对偶问题的最优解点。
- KKT 条件无法用来直接求解问题,但是如果猜出来一个解,可以 check 其是否满足 KKT 条件,进一步可以观察其某些变量违反 KKT 条件的程度,来进一步迭代更新这个解,例如 SMO 算法。
参考文献:
[1]《Convex Optimization》Ch4-Ch5, Boyd
[2]《Foundations of Machine Learning, 2nd》Appendix B, Mohri
[3]《 Linear and Nonlinear Programming, 3rd》Luenberger

 浙公网安备 33010602011771号
浙公网安备 33010602011771号