

Flink源码解析(九)——ExecutionGraph生成过程解析
一、ExecutionGraph介绍介绍
ExecutionGraph是调度Flink作业执行的核心数据结构,包含了作业中所有并行执行的Task信息、Task之间的关联关系、数据流转关系。相比于StreamGraph、JobGraph,ExecutionGraph加入了并行度的概念,成为真正可调度的图结构。下图是一个ExecutionGraph的简单示例。

二、ExecutionGraph核心对象介绍
ExecutionGraph核心对象包含ExecutionJobVertex、ExecutionVertex、IntermediateResult、IntermediateResultPartition、ExecutionEdge、Execution等。在较新版本中,ExecutionEdge已被EdgeManager替换。
1、ExecutionJobVertex:该对象与JobGraph中的JobVertex一一对应。它包含一组ExecutionVertex,数量是该节点所对应的并行度。
2、ExecutionVertex:ExecutionJobVertex会对Flink应用中执行节点并行化处理,构造可并行执行的ExecutionVertex实例。
3、IntermediateResult:该对象与JobGraph中的IntermediateDataSet一一对应,表示ExecutionJobVertex的输出。一个IntermediateResult包含多个IntermediateResultPartition,数据取决于算子的并行度。
4、IntermediateResultPartition:表示1个ExecutionVertex输出结果,与ExecutionEdge相关联。
5、EdgeManager:负责存储ExecutionGraph中所有的tasks并行度之间的关联关系。
6、Execution:ExecutionVertex相当于Task的模板,真正执行的时候Flink系统会从ExecutionVertex封装出一个Execution实例,代表一个实际的运行尝试。一个Execution通过一个ExecutionAttempID来唯一标识。
三、ExecutionGraph生成过程解析
1、ExecutionGraph生成入口:
DefaultExecutionGraphBuilder.buildGraph()即为ExecutionGraph生成入口。该方法入参包括之前生成的JobGraph实例及其他一些重要组件,方法实现中首先会生成一些必要信息,然后经过以下几个关键步骤生成一个DefaultExecutionGraph实例并构造以上核心对象,最后返回DefaultExecutionGraph实例。以下为几个关键步骤的简述,后面会详细讲解。
final DefaultExecutionGraph executionGraph = new DefaultExecutionGraph(); 初始化一个空DefaultExecutionGraph实例,设置一些成员变量。
List<JobVertex> sortedTopology = jobGraph.getVerticesSortedTopologicallyFromSources(); 获取JobGraph中JobVertex拓扑排序后的线性序列。
executionGraph.attachJobGraph(sortedTopology, jobManagerJobMetricGroup); ExecutionGraph核心对象生成的主要方法
isCheckpointingEnabled(jobGraph);为true时,设置ExecutionGraph的checkpoint相关信息。
2、jobGraph.getVerticesSortedTopologicallyFromSources()方法详解,在该方法中首先收集没有上游输入JobEdge的JobVertex,即数据源节点。其次循环判断JobGraph剩余节点是否还有剩余,遍历每一个数据源节点,将其下游所有的节点依次加入到拓扑排序序列中。
3、executionGraph.attachJobGraph(sortedTopology, jobManagerJobMetricGroup)方法详解,在attachJobGraph()方法实现中,主要包含两步重要操作,一是新建初始化的ExecutionJobVertex实例,二是初始化其他核心对象实例。
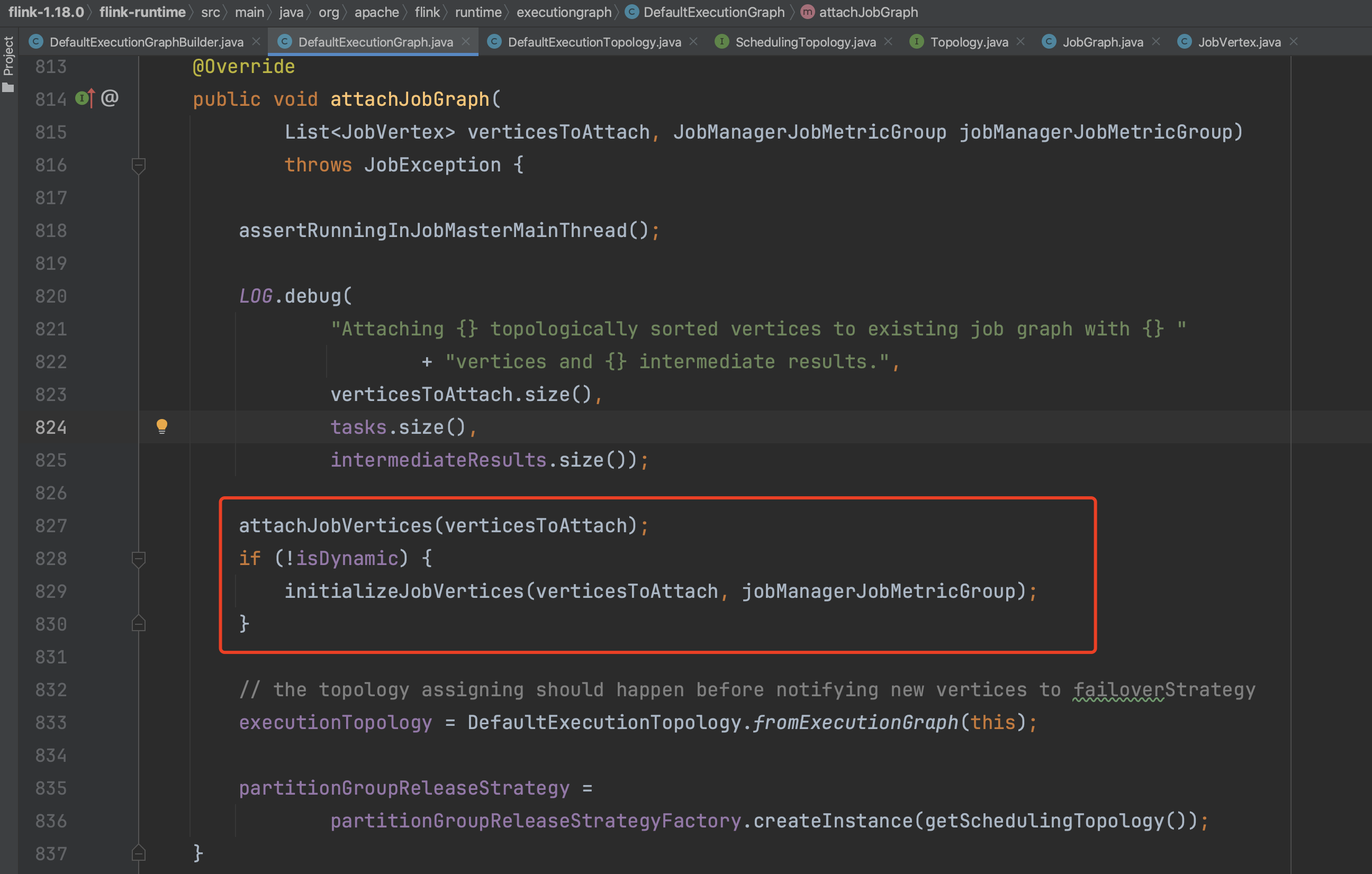
(1).方法attachJobVertices()主要作用是新建初始化的ExecutionJobVertex实例,由代码可知遍历拓扑序列中的每个JobVertex,利用JobVertex实例构建ExecutionJobVertex实例。
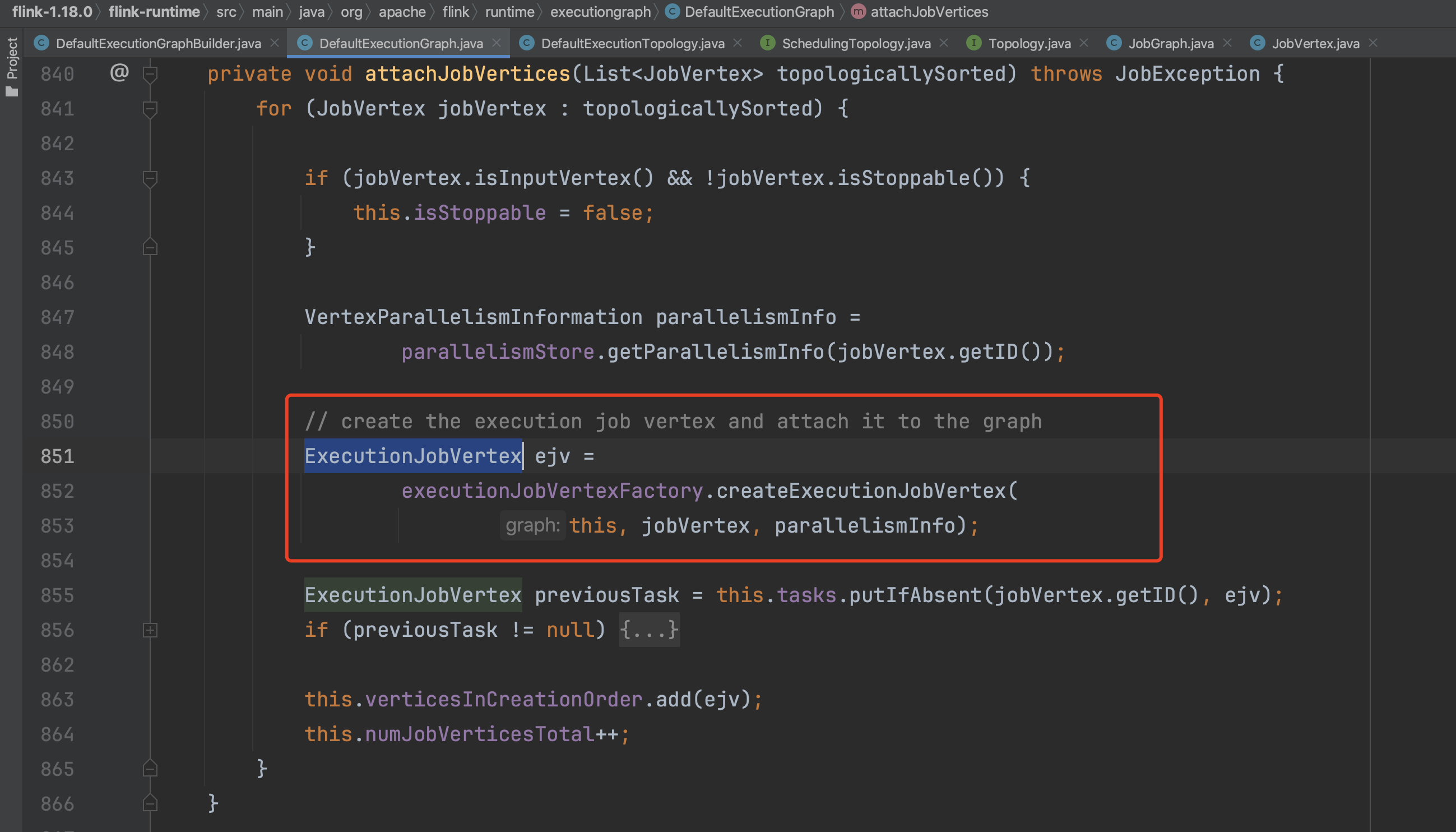
(2).方法initializeJobVertices()主要作用是构建其他核心对象,调用链路如下:
DefaultExecutionGraph.initializeJobVertices():遍历每个ExecutionJobVertex节点,初始化与之相关联的其他核心对象。
-> ExecutionGraph.initializeJobVertex():根据当前ExecutionJobVertex并行度和上游ExecutionJobVertex并行度,获取上游ExecutionJobVertex实例IntermediateResult成员对应下游的分区范围。
-> DefaultExecutionGraph.initializeJobVertex():调用方法ExecutionJobVertex.initialize()生成IntermediateResult、ExecutionVertex。调用方法ExecutionJobVertex.connectToPredecessors()生成ExecutionVertex、IntermediateResultPartition的关联关系,关联关系存放与EdgeManager.partitionConsumers、EdgeManager.vertexConsumedPartitions成员变量中。
1).方法ExecutionGraph.initializeJobVertex()中,227行代码生成一个Map<IntermediateDataSetID, JobVertexInputInfo>结构,代表下游每个并行度ExecutionVertex的消费上游IntermediateResultPartition并行度的范围。下图以点对点类型为例,说明其划分逻辑。
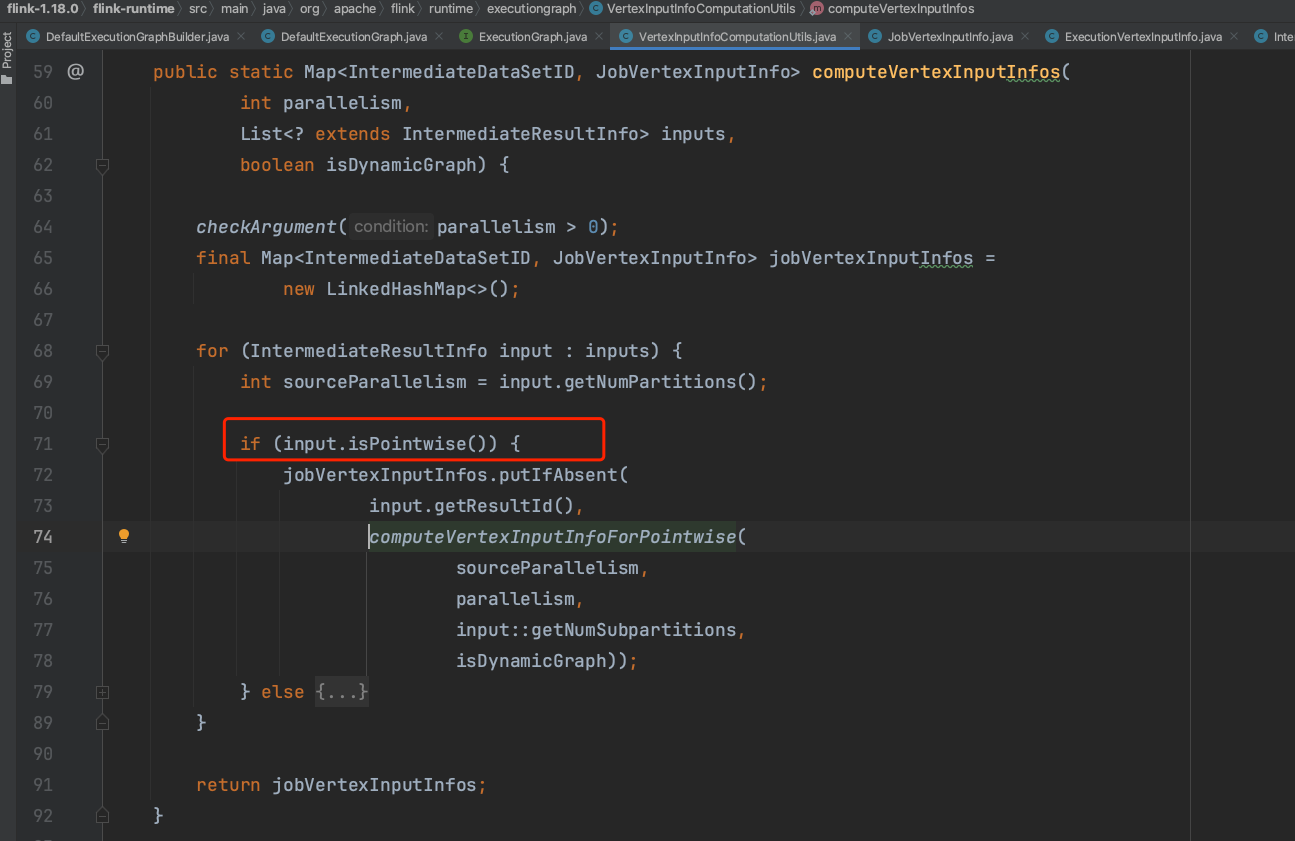
当上游IntermediateDataSet并行度>=下游ExecutionJobVertex并行度时,如2=2时,一个ExecutionVertex对应一个IntermediateResultPartition。如4>2时,第1个ExecutionVertex对应前2个IntermediateResultPartition,第2个ExecutionVertex对应后2个IntermediateResultPartition。如3>2时,第1个ExecutionVertex对应前2个IntermediateResultPartition,第2个ExecutionVertex对应第3个IntermediateResultPartition。
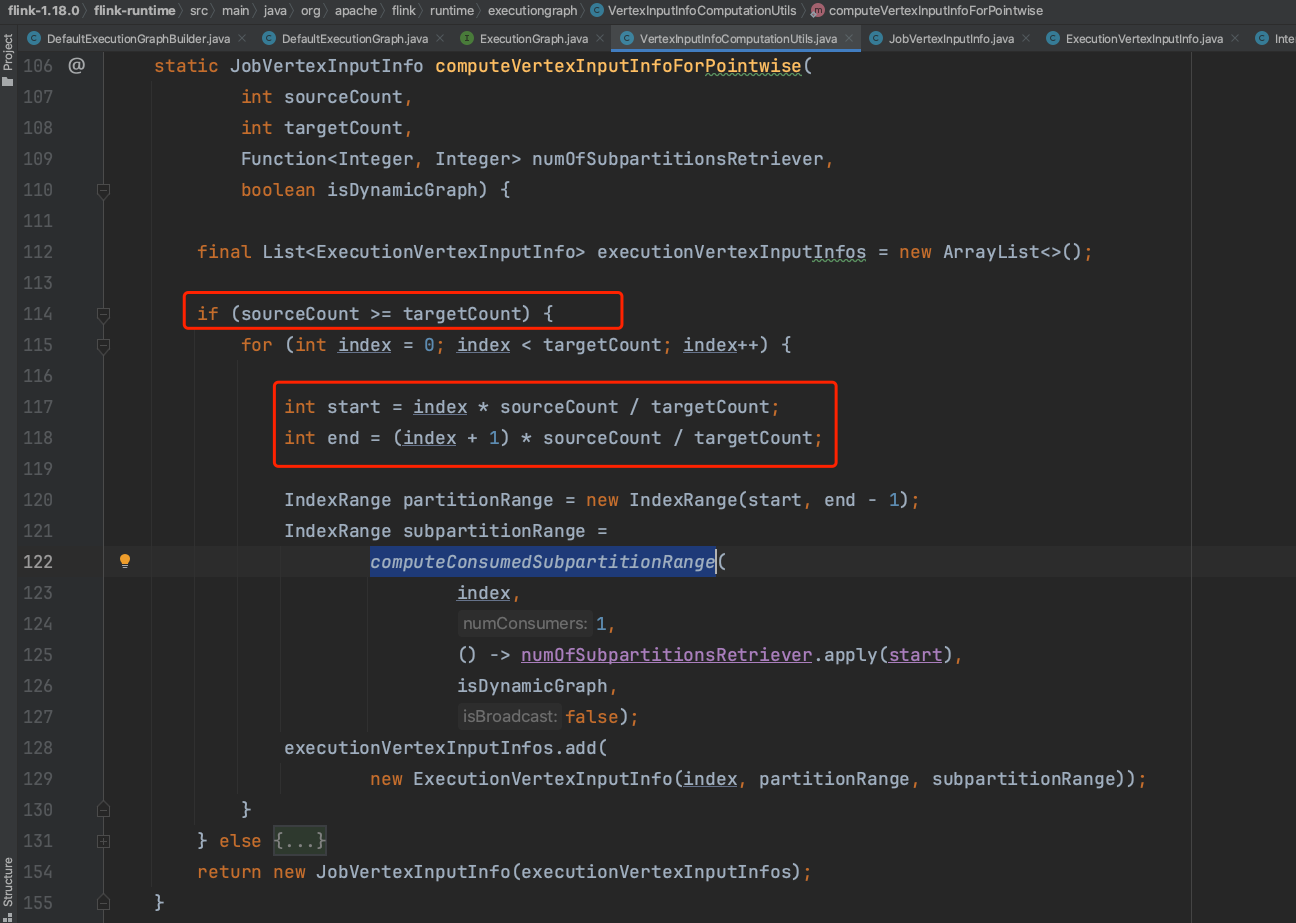
当上游IntermediateDataSet并行度<下游ExecutionJobVertex并行度时,如2<4时,前2个ExecutionVertex对应第1个IntermediateResultPartition,后2个ExecutionVertex对应第2个IntermediateResultPartition。如2<3时,前2个ExecutionVertex对应第1个IntermediateResultPartition,第3个ExecutionVertex对应第2个IntermediateResultPartition。
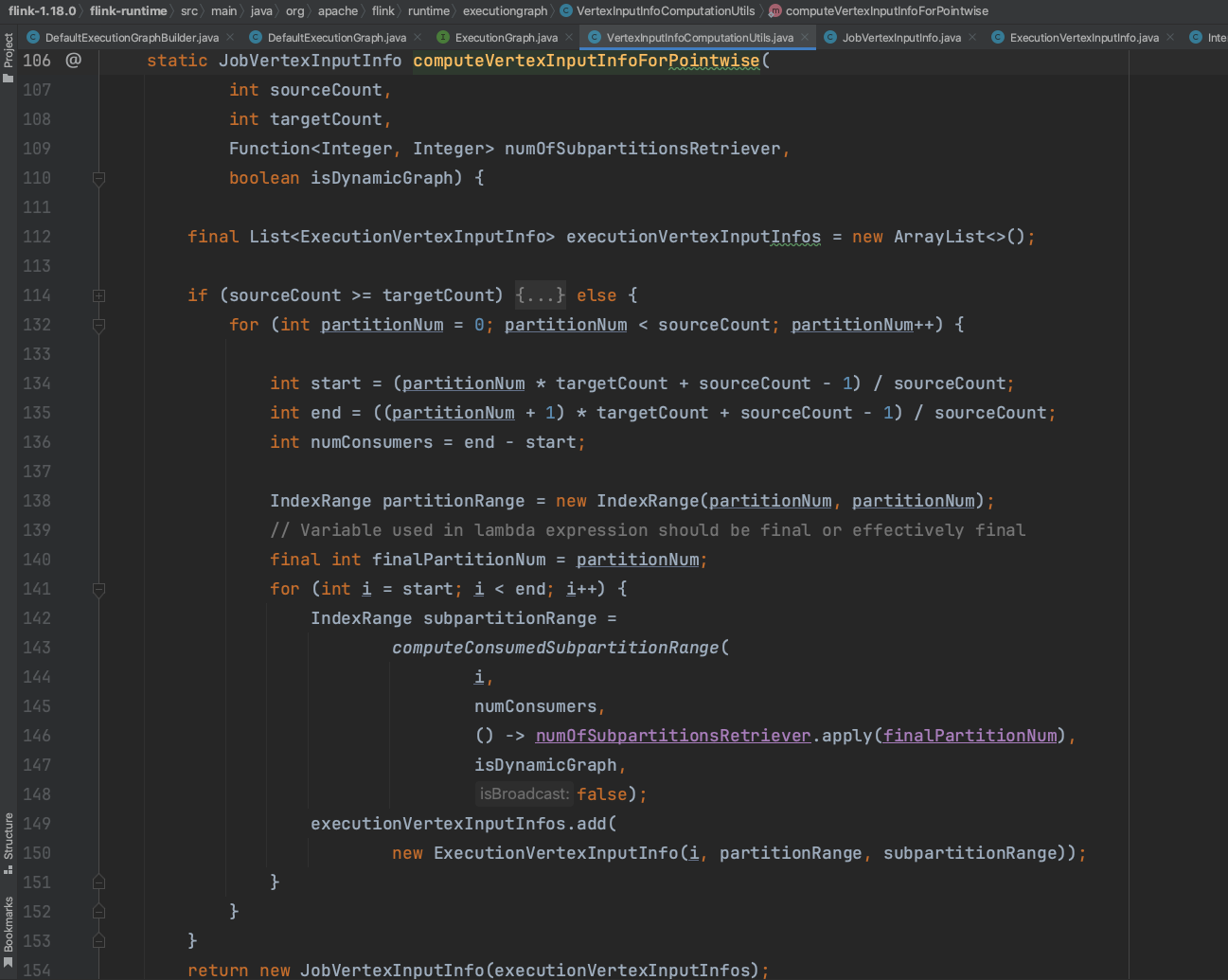
下图以all_to_all为例,即下图else分支逻辑。
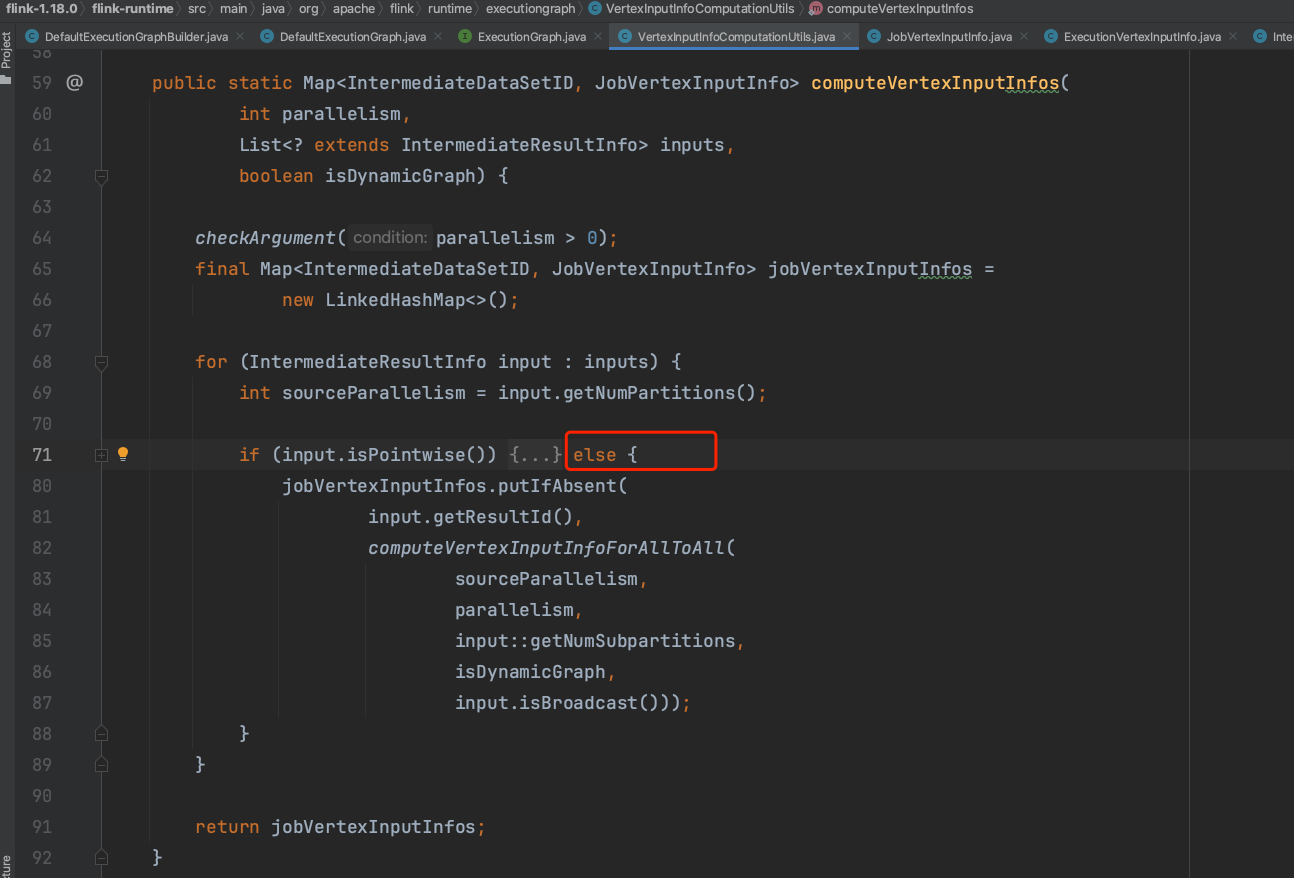
上游IntermediateDataSet并行度和下游ExecutionJobVertex并行度是笛卡尔积的关系。即下游每个ExecutionVertex都消费上游所有的IntermediateResultPartition。
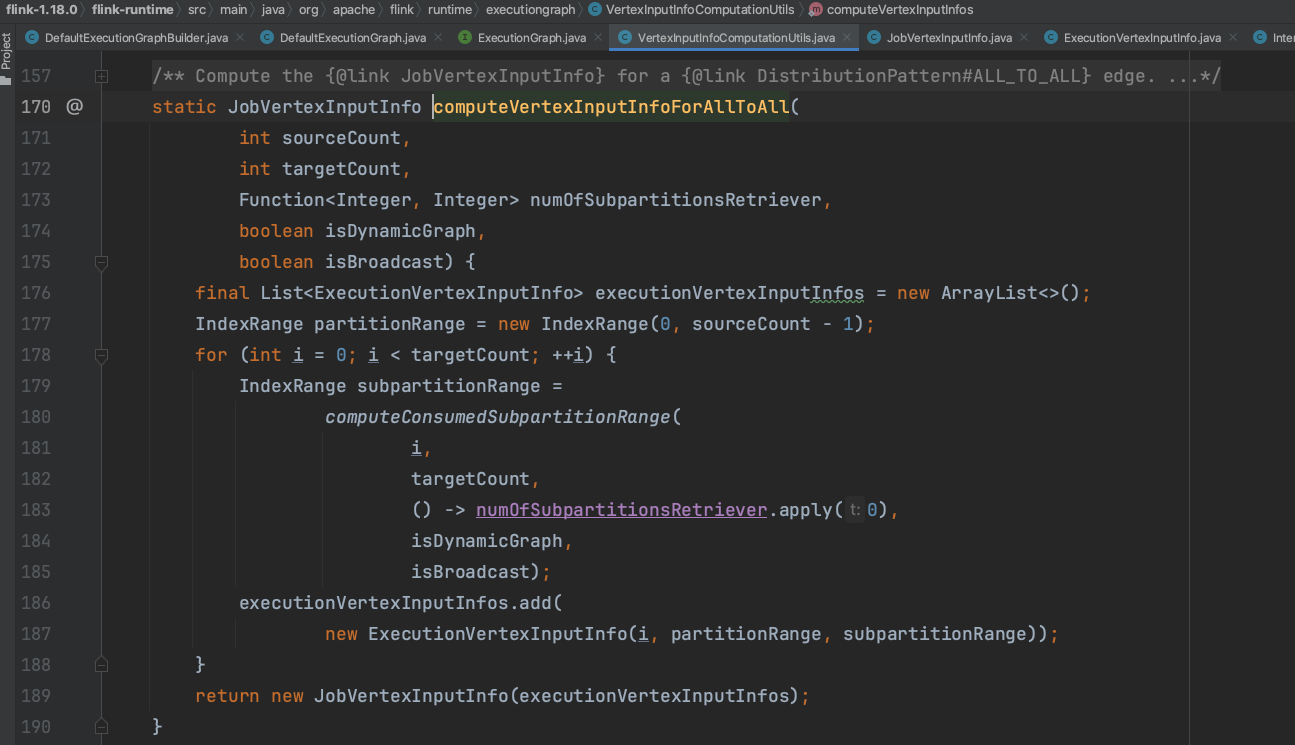
2).方法DefaultExecutionGraph.initializeJobVertex()开始生成IntermediateResult、ExecutionVertex实例,并设置ExecutionVertex、IntermediateResultPartition的关联关系。
在IntermediateResult构造函数中,会设置IntermediateResultPartition数组。在createExecutionVertex方法中会新建ExecutionVertex实例并初始化相关信息。
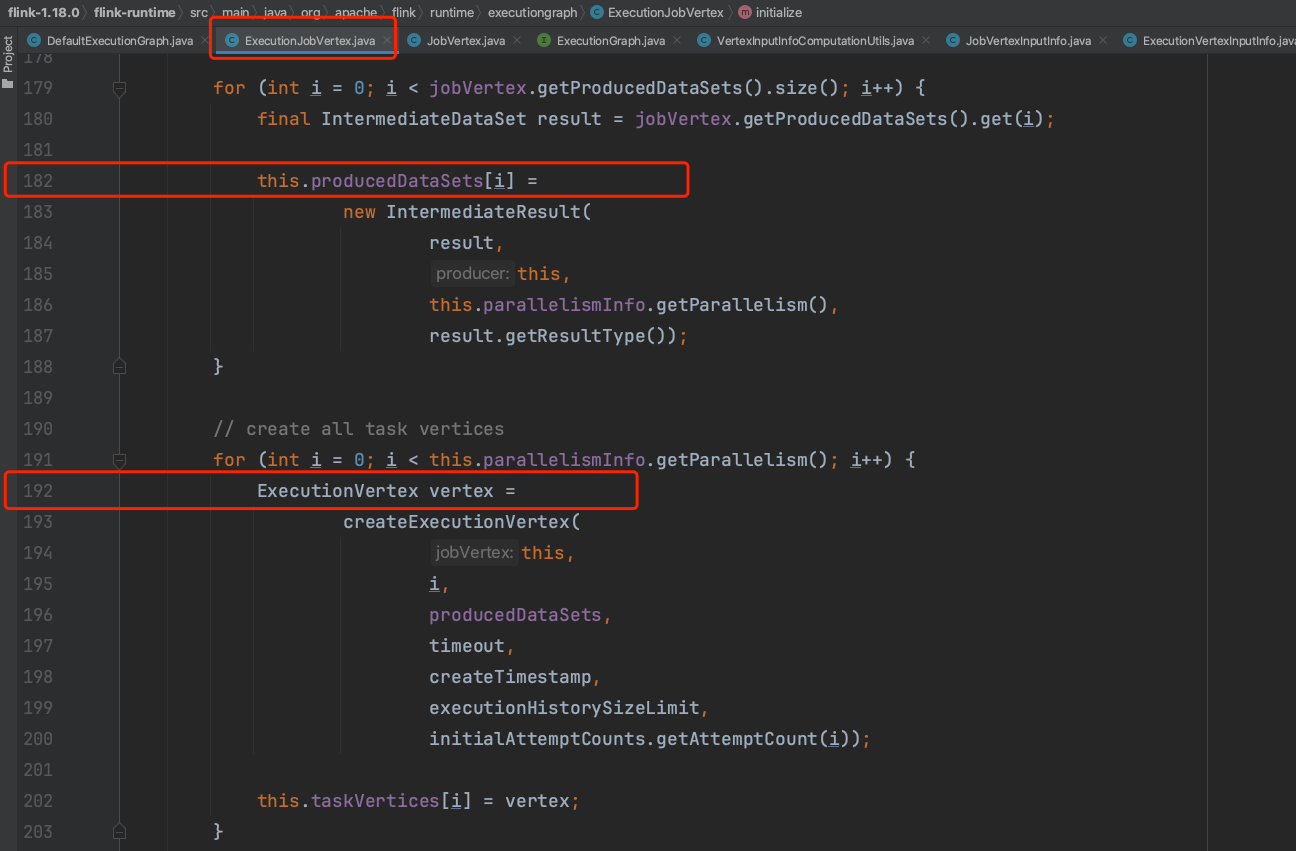
在ExecutionVertex初始化过程中,以下for循环只负责设置(该节点IntermediateResultPartition并行度*下游消费该节点的节点个数)个IntermediateResultPartition对象。至此initialize()方法执行完毕。
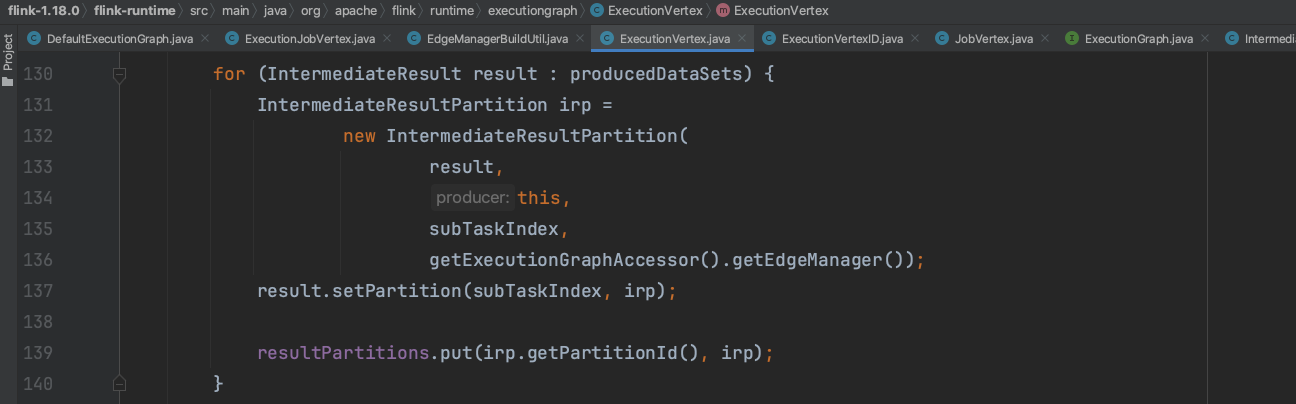
ExecutionJobVertex.connectToPredecessors()方法生成ExecutionVertex、IntermediateResultPartition的关联关系,关联关系存放到EdgeManager.partitionConsumers、EdgeManager.vertexConsumedPartitions成员变量中。遍历当前节点的输入边,获取输入边源节点对应的IntermediateResult实例。
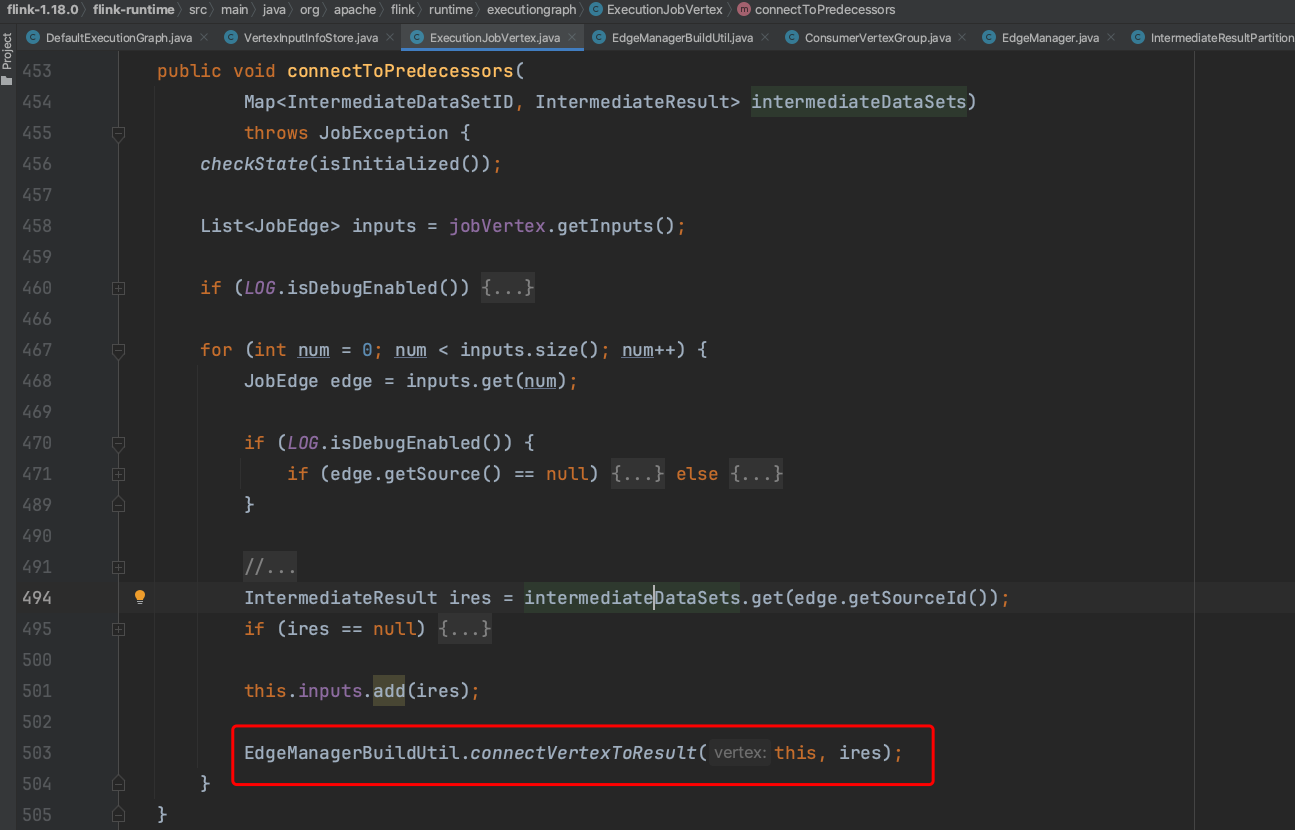
根据当前ExecutionJobVertex实例和IntermediateResult实例,开始构建ExecutionGraph中的边关联信息。
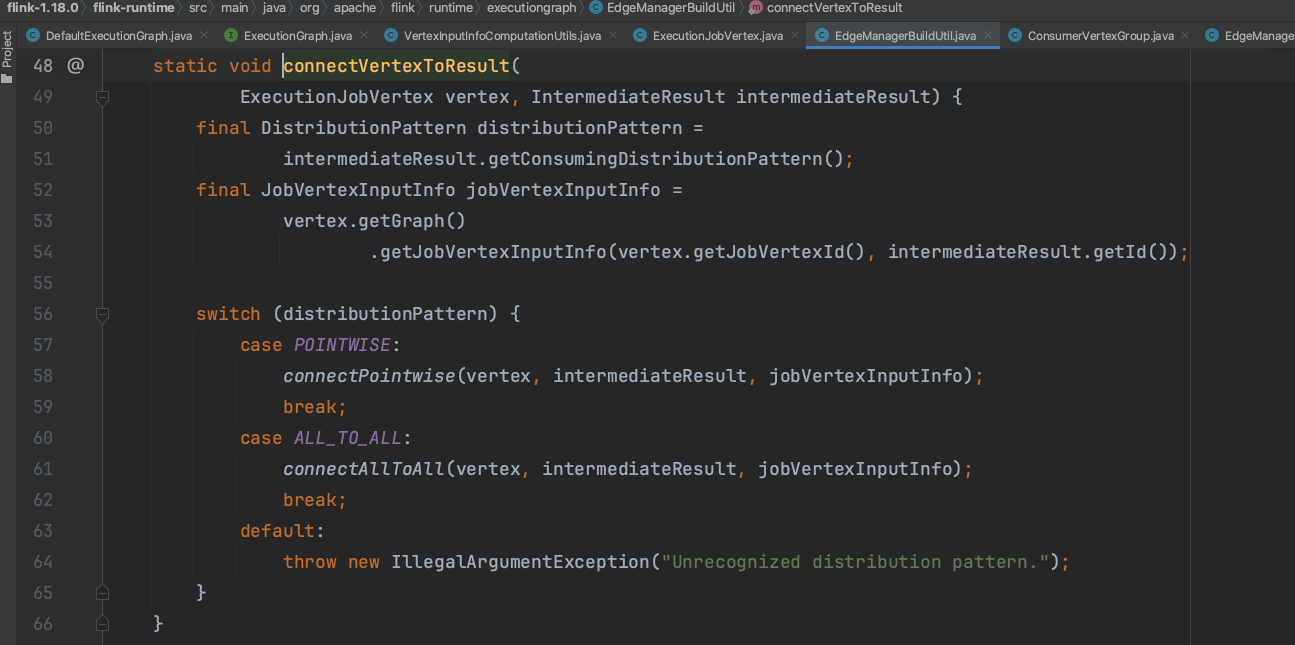
以点对点为例分析ExecutionGraph边构建过程,JobVertexInputInfo存的是当前ExecutionJobVertex各个并行度ExecutionVertex对应的IntermediateResultPartition index范围。consumersByPartition负责翻转ExecutionJobVertex和IntermediateResultPartition下标映射关系。以上游并行度2、下游并行度4为例,JobVertexInputInfo里存储的4个ExecutionVertex及其对应的IntermediateResultPartition index。consumersByPartition翻转后存的是2个IntermediateResultPartition IndexRange对应ExecutionVertex列表。利用consumersByPartition变量,生成taskVertices、partitions 2个列表集合,开始边构建过程。
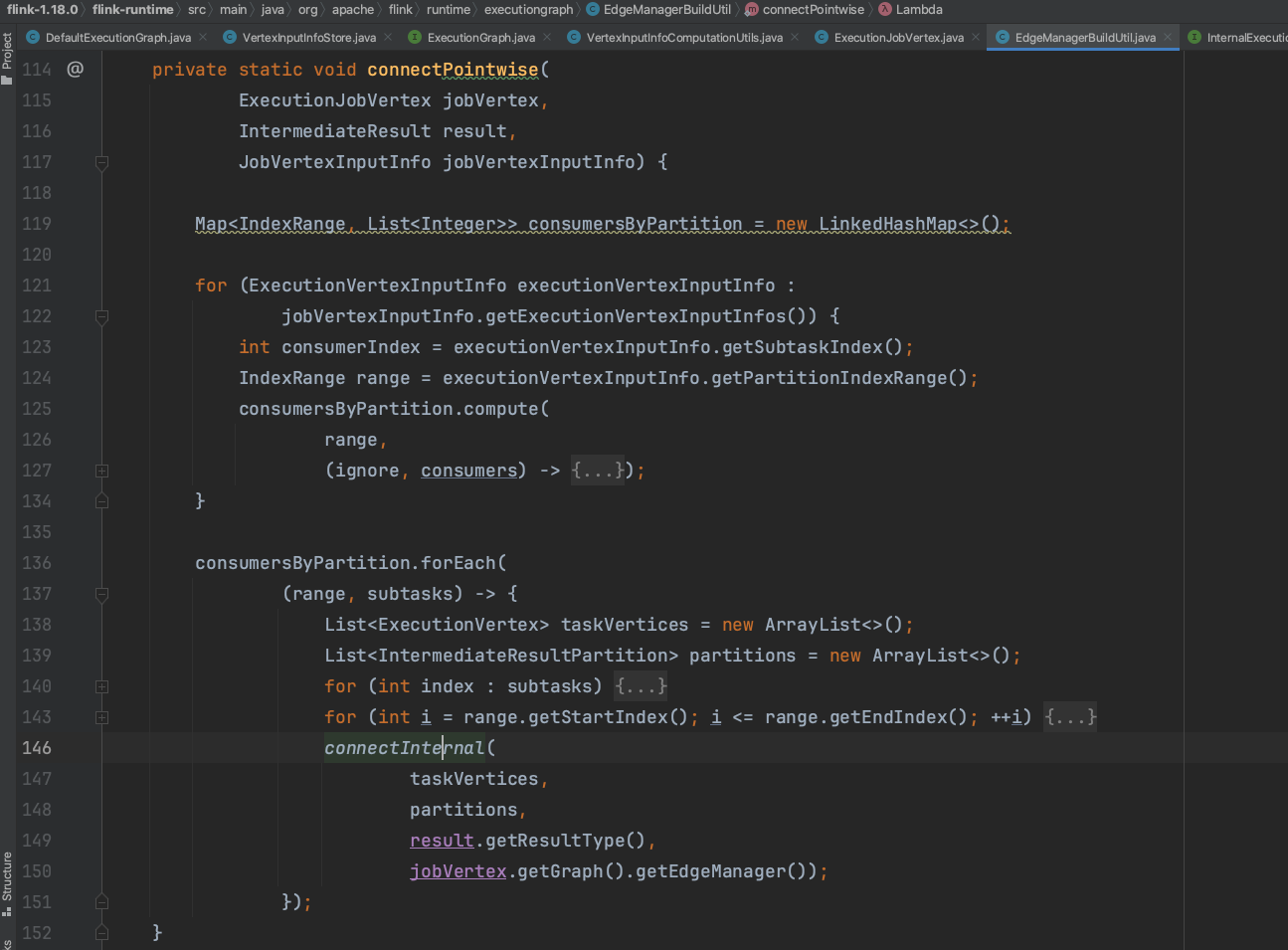
边关联关系设置,生成ConsumedPartitionGroup实例,ev.addConsumedPartitionGroup(consumedPartitionGroup);负责设置EdgeManager.vertexConsumedPartitions。partition.addConsumers(consumerVertexGroup);负责设置EdgeManager.partitionConsumers。
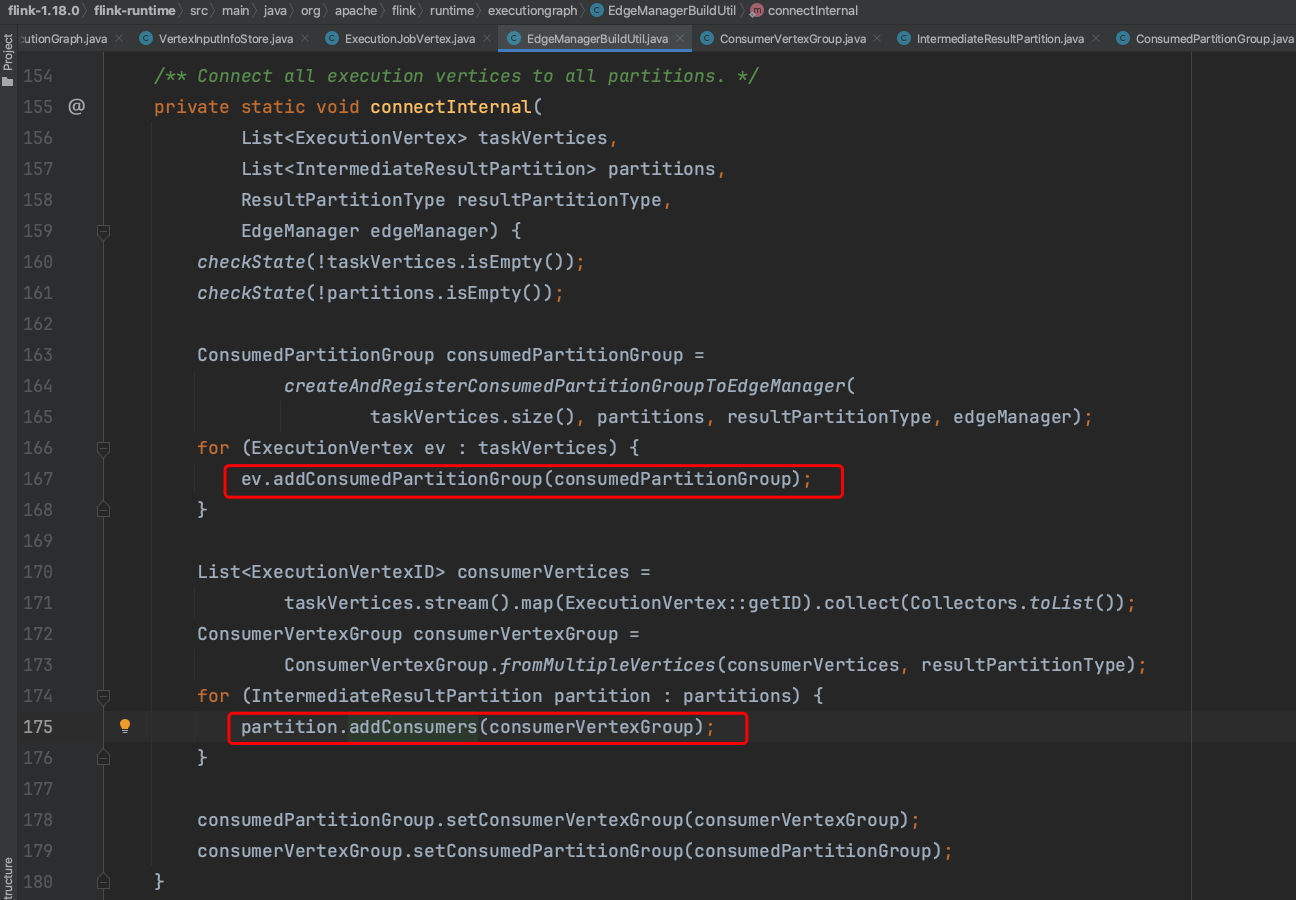
2个成员变量存储的实际内容如下:
Map<ExecutionVertexID, List<ConsumedPartitionGroup>> vertexConsumedPartitions;
{
ExecutionVertex1 -> [IntermediateResultPartitionID1]
ExecutionVertex2 -> [IntermediateResultPartitionID1]
ExecutionVertex3 -> [IntermediateResultPartitionID2]
ExecutionVertex4 -> [IntermediateResultPartitionID2]
}
Map<IntermediateResultPartitionID, List<ConsumerVertexGroup>> partitionConsumers;
{
IntermediateResultPartitionID1 -> [ExecutionVertex1、ExecutionVertex2]
IntermediateResultPartitionID2 -> [ExecutionVertex3、ExecutionVertex4]
}
至此,ExecutionGraph的构建工作结束。
最后留一个问题思考:VertexInputInfoComputationUtils.computeVertexInputInfos()方法中第47行代码IntermediateResult ires = intermediateResultRetriever.apply(edge.getSourceId());中的intermediateResultRetriever指得是DefaultExecutionGraph.getAllIntermediateResults()方法返回的intermediateResults map结构。它是啥时候初始化的?直接获取的IntermediateResult感觉为空?答案是从源头上开始生成的,后面能看到前面。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号