
Flink源码解析(八)——JobGraph生成过程解析
一、JobGraph介绍
上一篇随笔中解析了StreamGraph的生成过程,Flink应用转换成StreamGraph后紧接着向JobGraph转换。在转换过程中1个或多个符合条件的StreamNode会生成一个JobVertex,每一个JobVertex就是JobGraph的节点。JobVertex节点计算输出结果为中间结果集IntermediateDataSet,而JobVertex的数据输入为JobEdge。JobEdge主要作用是连接上游IntermediateDataSet和下游的JobVertex。下图是一个StreamGraph到JobGraph的简单示例。

二、JobGraph核心对象介绍
由上图可知JobGraph主要包含3个核心对象,JobVertex、IntermediateDataSet、JobEdge。
1、JobVertex:经算子融合后将1个或多个StreamNode转换为JobVertex,即JobVertex包含一个或多个算子。JobVertex.results成员变量代表该节点被几个下游节点所消费,JobVertex.inputs代表该节点消费了几个上游节点。
2、IntermediateDataSet:JobVertex计算输出结果为中间结果集IntermediateDataSet,它是一种逻辑结构,用来描述JobVertex的输出。
3、JobEdge:用来连接JobVertex和IntermediateDataSet的边,表示JobGraph中的一个数据流转通道。
JobVertex的IntermediateDataSet个数可以是一个或多个,取决于对应的StreamNode出边数量。
三、JobGraph生成过程解析
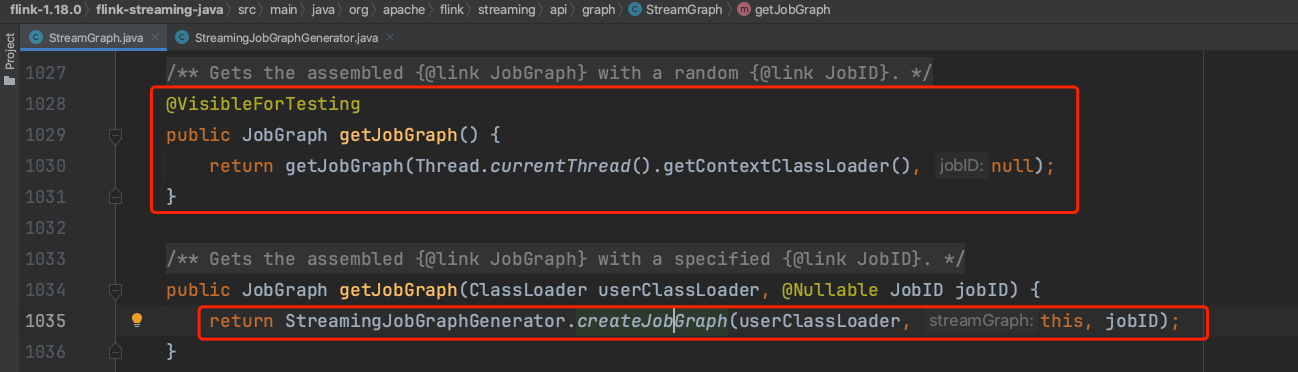
1、JobGraph生成入口:StreamGraph类的getJobGraph()方法是JobGraph生成入口方法。它会先初始化一个StreamingJobGraphGenerator实例并调用createJobGraph()方法正式开始JobGraph生成过程。在初始化StreamingJobGraphGenerator实例时会生成一系列的成员变量来共同完成JobGraph生成工作。
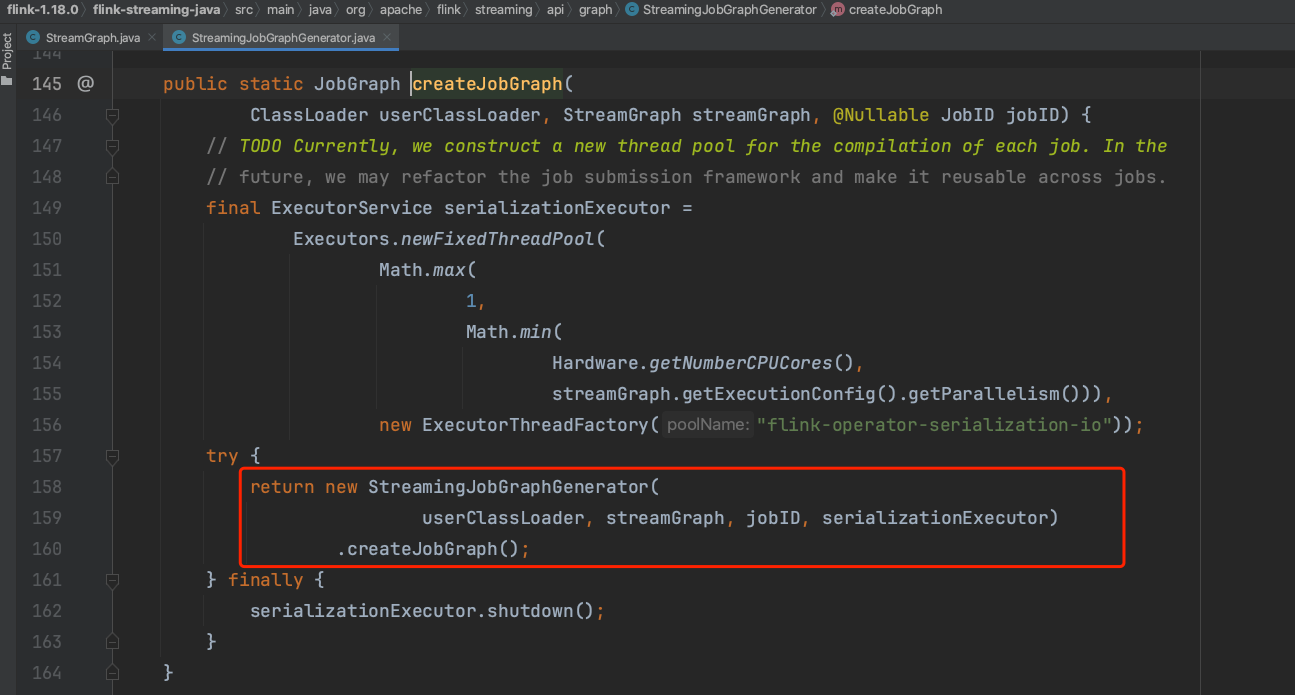
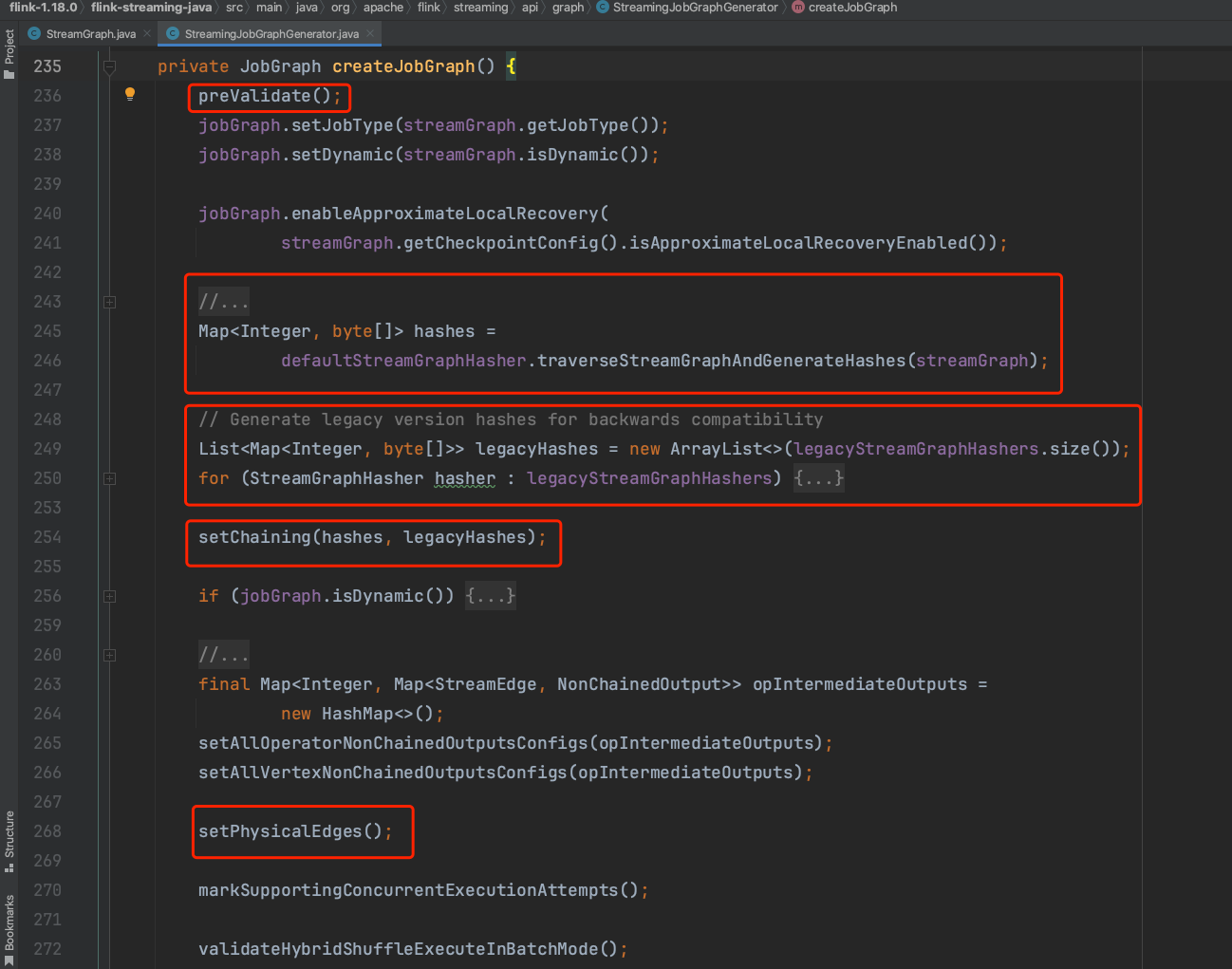
2、下图createJobGraph()方法实现中会有几步比较重要的工作,简单的工作会在此讲解,复杂的工作会有单独小节讲解。
(1). preValidate();负责前置检查工作,当前checkpoint的某些配置不适用于Flink特定使用场景。
(2). defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);遍历所有数据源组成的StreamNode,从数据源StreamNode开始为每一个StreamNode生成一个不可变的16字节大小的byte数组,填充Map<Integer, byte[]> hashes。key为StreamNode.id成员,value为16字节大小不可变的byte数组值。
(3).legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));为向后兼容,根据Flink用户为每个Transformation配置的uidHash,生成List<Map<Integer, byte[]>> legacyHashes。key为StreamNode.id成员,value为uidHash生成的byte数组。
(4).setChaining(hashes, legacyHashes);执行Chaining操作生成JobVertex,后续会详细讲解。
(5).setAllVertexNonChainedOutputsConfigs(opIntermediateOutputs);生成JobEdge、IntermediateDataSet,后续会详细介绍。
(6).设置下游节点的物理入边并序列化。后续会详细讲解。
(7).JobGraph的其他设置。

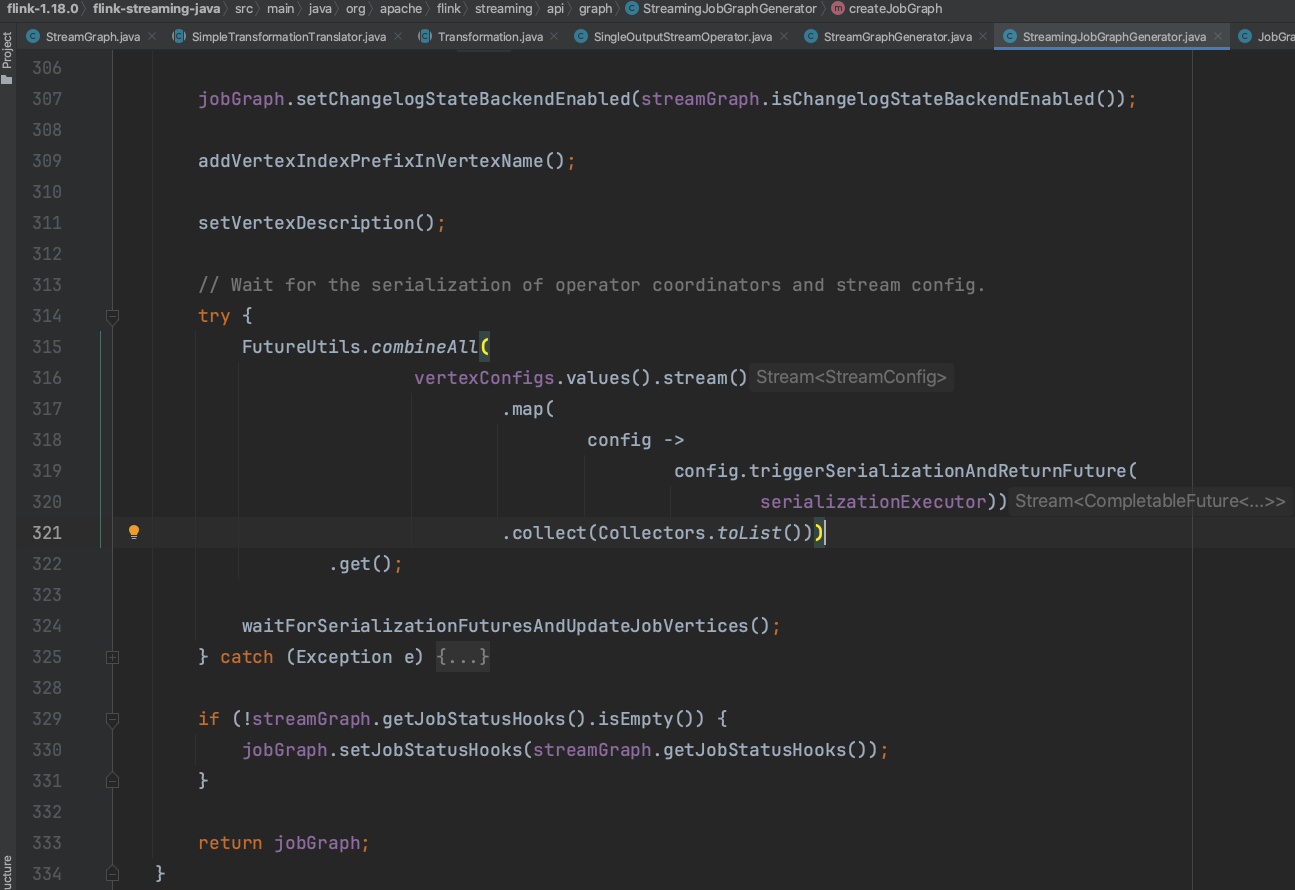
3、StreamGraphHasherV2.traverseStreamGraphAndGenerateHashes(streamGraph)方法详解:
该方法的调用路径如下:
StreamGraphHasherV2.traverseStreamGraphAndGenerateHashes(streamGraph):遍历数据源节点集合,依次生成节点的hash值,生成后遍历该节点的下游节点,添加到待生成hash的节点集合中。
->StreamGraphHasherV2.generateNodeHash():如果用户未指定hash值,则由系统生成。确保当前节点的上游节点都生成hash值后,执行生成节点hash值的操作。
->StreamGraphHasherV2.generateDeterministicHash():根据当前已生成hash值的节点数量,设置hash值生成信息。
->StreamGraphHasherV2.generateNodeLocalHash():设置hash值生成信息。
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));方法主要作用是根据用户传入的hash值信息生成hash值。该方法主要是为了是向后兼容。
hash值主要应用于JobVertex ID的生成过程,主要目的是Flink应用在checkpoint恢复状态时用JobVertex ID定位对应的状态节点。
4、setChaining()方法详解:
(1).setChaining()方法根据上面生成的hash值信息开始构造JobVertex节点。该方法第一步功能是区分可被chain的source节点和不可被chain的source节点。

(2).在buildChainedInputsAndGetHeadInputs()方法中chainedSources中存储可被chain的sourceId对应的配置信息、source节点输出边信息,chainEntryPoints变量存储的是所有source节点信息及可被chain的source节点的紧邻下游节点信息。如下图代码中,1中存的是可被chain的source节点及配置信息,2中chainEntryPoints存储可被chain的source节点的紧邻下游节点信息,3中存储的是所有source节点信息。可被chain的source节点在operatorConfig中的chainIndex为0.
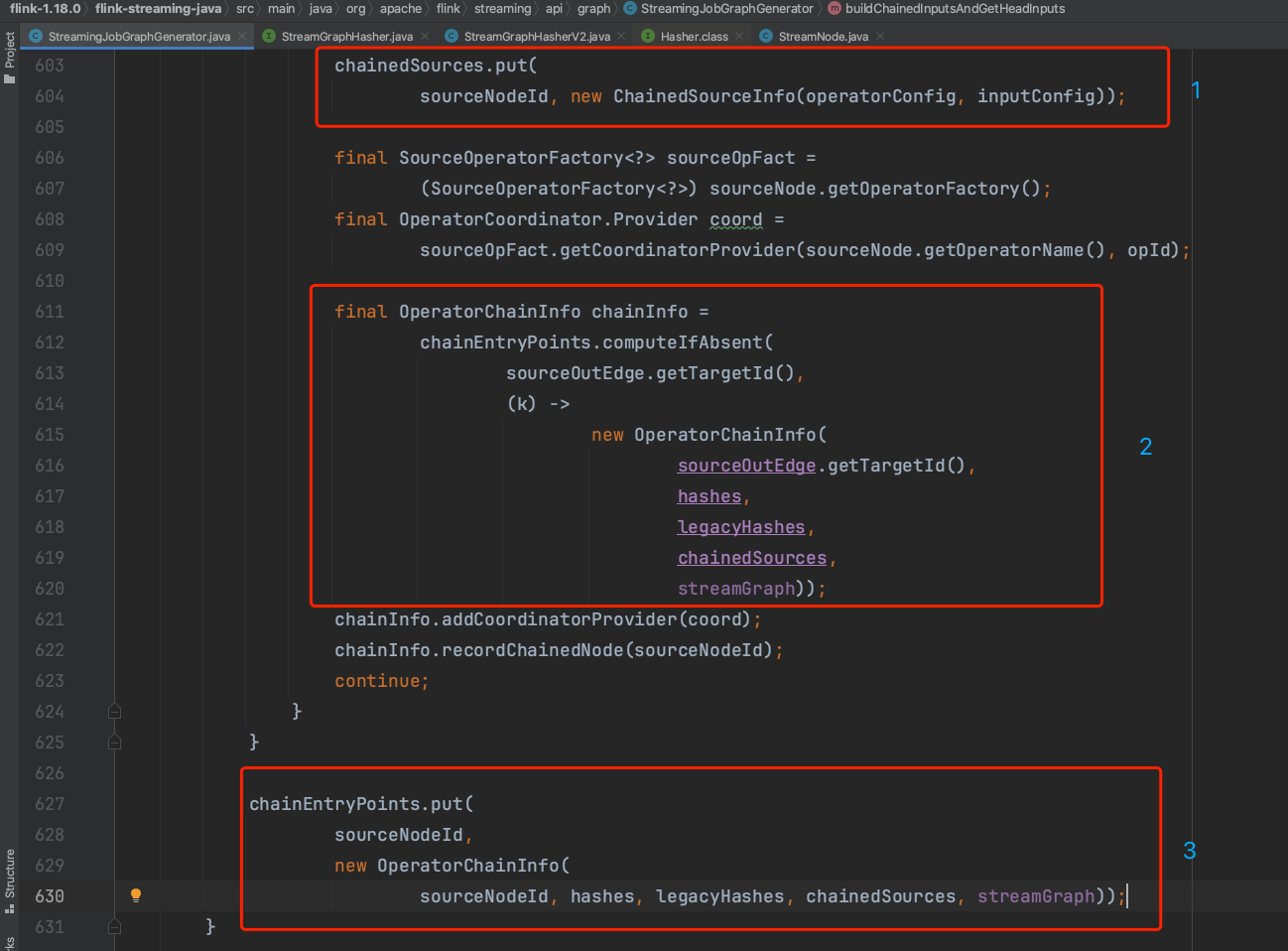
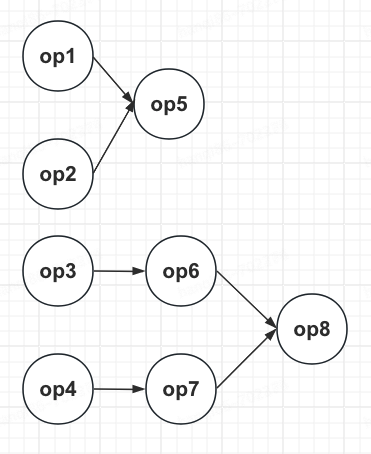
以下图为例,直观来看chainedSources存储的是可被chain的op3、op4节点及配置信息。chainEntryPoints存储op1、op2、op3、op4、op6、op7节点信息。
代码速记简写为以下形式:
chainedSources.put(sourceNodeId, new ChainedSourceInfo(operatorConfig, inputConfig));
OperatorChainInfo(startNodeId,hashes,chainedSources,streamGraph)
final Map<Integer, OperatorChainInfo> chainEntryPoints = {
sourceNodeId1 <-> OperatorChainInfo(sourceNodeId1, hashes, chainedSources, streamgraph);
sourceNodeId2 <-> OperatorChainInfo(sourceNodeId2, hashes, chainedSources, streamgraph);
sourceNodeId3 <-> OperatorChainInfo(sourceNodeId3, hashes, chainedSources, streamgraph);
sourceNodeId4 <-> OperatorChainInfo(sourceNodeId4, hashes, chainedSources, streamgraph);
s3下游节点 <-> OperatorChainInfo(s3下游节点, hashes, chainedSources, streamgraph);
s4下游节点 <-> OperatorChainInfo(s4下游节点, hashes, chainedSources, streamgraph);
}
(3).从数据源开始遍历chainEntryPoints的values集合,对每个value值执行createChain()方法。在createChain()方法中chainableOutputs变量存的是可chain下游节点的当前节点的出边信息,如边<op3,op6>或<op4,op7>信息。nonChainableOutputs变量存的是不可chain下游节点的当前节点的出边信息,如边<op1,op5>或<op2,op5>或<op6,op8>或<op7,op8>信息。transitiveOutEdges变量存的是所有不可chain的边信息,如上图所示transitiveOutEdges存的是边<op1,op5>、<op2,op5>、<op6,op8>、<op7,op8>信息。由下图可知,createChain()方法执行过程中存在递归调用情况。以节点op3节点为例,<op3,op6>为可chain的边,所以到688行代码进入节点op6的递归调用中。<op6,op8>为不可chain的边,所以到697行代码进入节点op8的递归调用中。着重分析下688行代码和697行代码的第二、三个入参信息。688行代码为可chain的递归调用,所以op6的chainInex会加1并且chainInfo用的是op3的chainInfo。697行代码为不可chain的递归调用,所以chainIndex从1开始,0只为source节点所用,chainInfo为新建的op8的chainInfo。

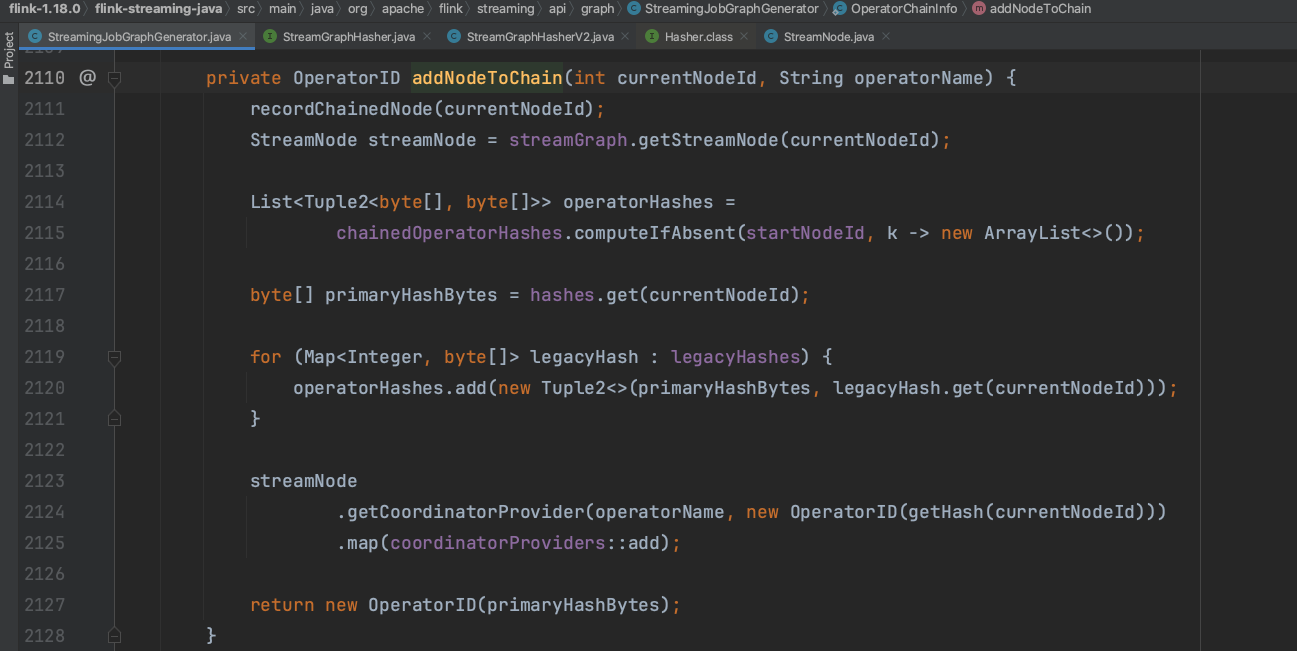
当节点op8的createChain()方法调用时,因为没有出边信息,所以跳过3个for循环及2个调用调用。开始设置OperatorChain名称、资源等信息。下图为添加chainInfo里的节点信息、hash信息等。
当前为op8节点调用,currentNodeId.equals(startNodeId)条件为true,开始创建JobVertex节点并设置节点的相关配置信息。创建完JobVertex后为动态图设置Partitioner信息。设置节点的配置信息等。
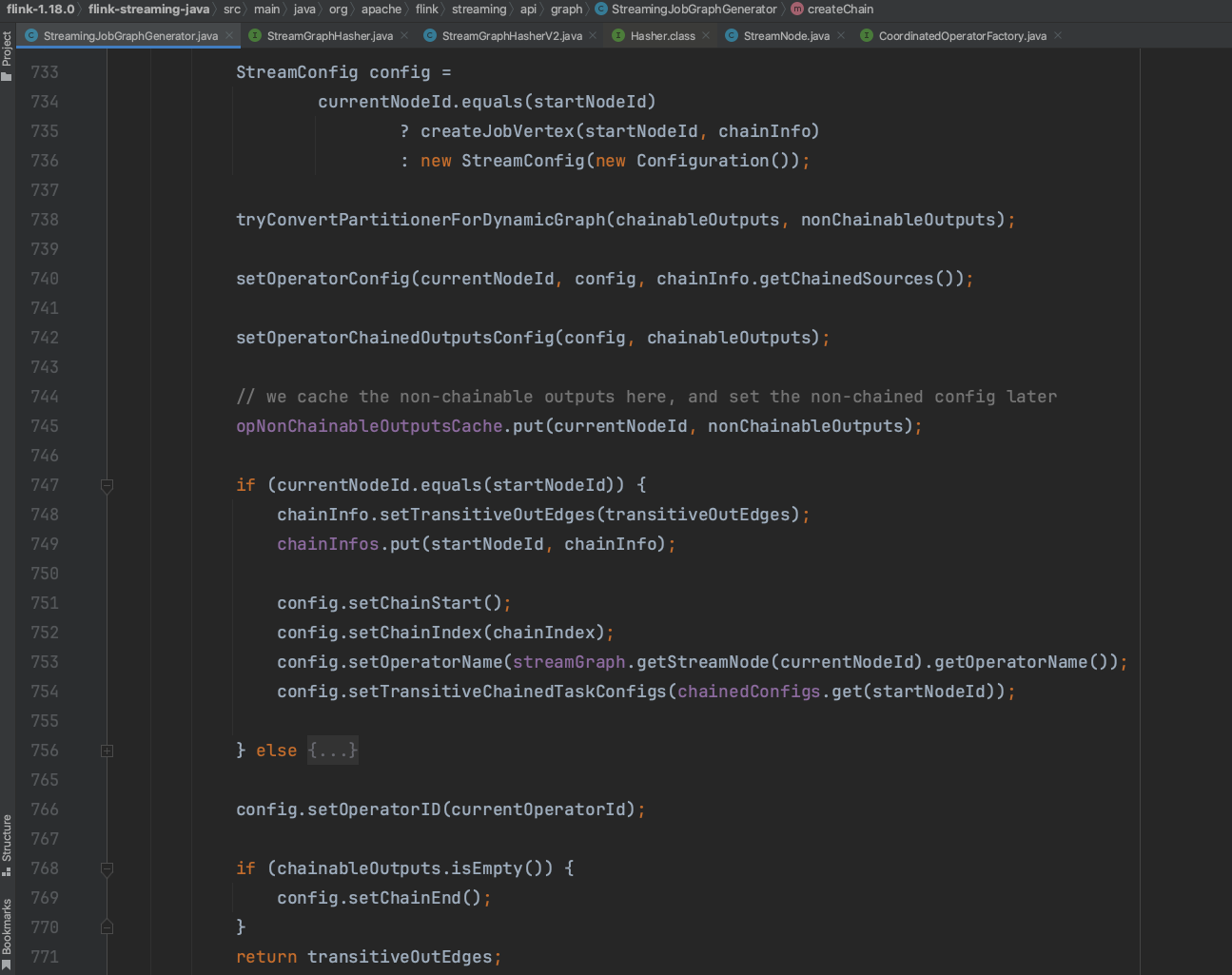
当节点op8调用结束后返回到节点op6调用。chainInfo.addNodeToChain()方法调用中chainInfo为op3的chainInfo信息,这步操作会将op6加入到op3开头的OperatorChain信息中。紧接着创建一个空的StreamConfig实例并设置节点配置信息到该实例中。最后补充chainedConfigs信息。
当节点op6调用结束后返回到节点op3调用。chainInfo.addNodeToChain()方法调用中chainInfo为op3的chainInfo信息,将节点op3加入到OperatorChain信息中。紧接着创建一个JobVertex节点,设置该节点的配置信息等。
在createChain()方法中会判断上下游节点是否可chain,条件如下。

总结起来共9个条件:
1).下游节点只有一个输入边
2).StreamGraph图chaining设置为true,即图整体可chaining
3).上下游节点在一个槽位共享组内
4).下游算子节点不为null
5).上游算子节点不为null
6).上游节点的连接策略是ALWAYS或HEAD或HEAD_WITH_SOURCES
7).下游节点的连接策略是 ALWAYS或HEAD_WITH_SOURCES
8).上下游节点的并行度相等
9).edge 的分区函数是 ForwardPartitioner 实例
以上即为createChain()方法创建JobVertex的递归过程。
5、setAllVertexNonChainedOutputsConfigs();方法详解:
(1).setAllOperatorNonChainedOutputsConfigs()方法主要作用是对每一个不可chain的StreamEdge生成一个NonChainedOutput实例。
(2).setAllVertexNonChainedOutputsConfigs()方法的调用链路如下:
StreamingJobGraphGenerator.setAllVertexNonChainedOutputsConfigs():遍历之前生成的每个JobVertex,对每个JobVertex进行JobEdge、IntermediateDataSet的生成操作。
->StreamingJobGraphGenerator.setVertexNonChainedOutputsConfig():遍历每个JobVertex的不可chain的出边集合元素,调用connect()方法生成JobEdge、IntermediateDataSet。
->StreamingJobGraphGenerator.connect():如下图所示调用JobVertex.connectNewDataSetAsInput()方法,不可chain出边的源JobVertex生成IntermediateDataSet实例,不可chain出边的下游JobVertex生成JobEdge实例。IntermediateDataSet实例的consumers集合成员添加JobEdge实例。
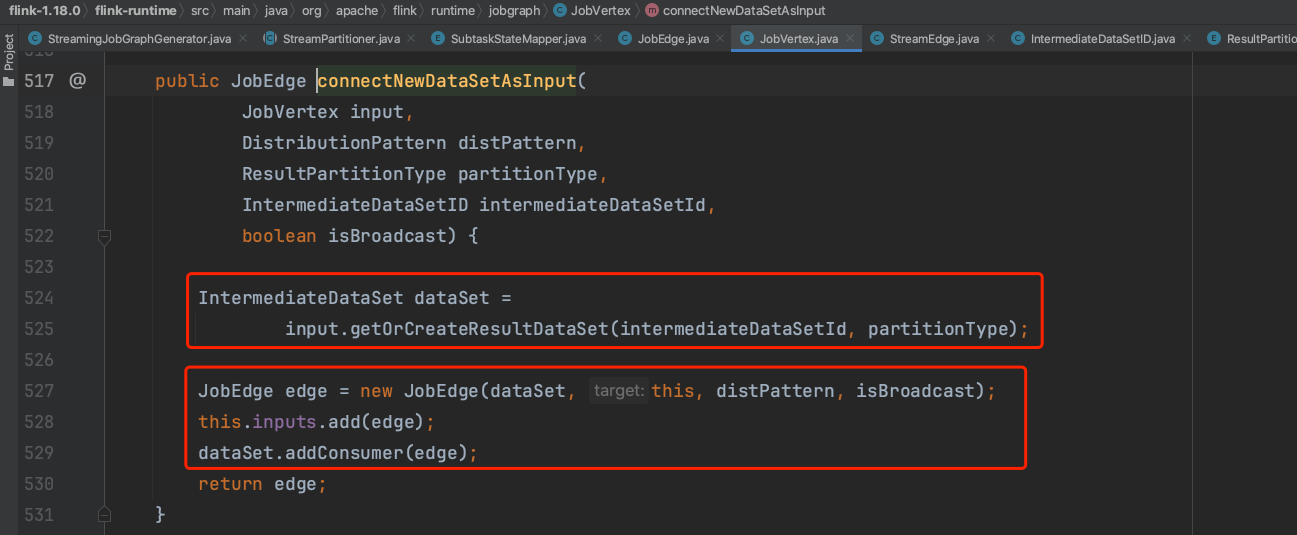
至此,JobGraph中涉及到的JobVertex、IntermediateDataSet、JobEdge核心对象均创建完毕。
6、setPhysicalEdges()方法主要作用是给每个节点对应的配置实例StreamConfig设置物理入边,意味着真实的跨线程间或网络输入。
7、其余代码皆为JobGraph实例的其他设置,比如节点的槽位共享组信息设置、资源设置、用户自定义文件设置等。最后返回JobGraph实例。
最后留一个问题思考:setChaining()方法第一步buildChainedInputsAndGetHeadInputs()调用中会为每个可chain的数据源的StreamConfig实例设置chainIndex为0,即类文件StreamingJobGraphGenerator第600行。但是在第二步遍历chainEntryPoints的values集合,对每个value值执行createChain()方法。createChain()方法调用中第二个入参chainIndex为1。存在同一个source节点在这两步操作种会设置不同的chainIndex的现象,待解释?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号