

Flink源码解析(四)——算子和UDF自定义函数解析
一、数据流元素前置介绍
数据流元素在Flink中叫做StreamElement,主要有4种实现类。在执行层面上这4种数据流元素都被序列化成二进制混合数据流,在算子中将混合数据流中的数据流元素反序列化出来,根据其类型分别进行处理。4种实现类如下:
1、数据记录StreamRecord,代表数据流中的业务数据记录,主要包含数据值本身value字段和时间戳timestamp字段。
2、延迟标记LatencyMarker,延迟评估标记。在数据源中创建并在Dataflow中流向DataSink,根据整个流动时间近似评估数据处理延迟。该元素包含创建时间markedTime、算子编号operatorId、子Task编号等字段。
3、水印Watermark,其本质代表一个时间戳,用来表示所有时间早于该Watermark的事件或数据均已到达,可以触发窗口计算等。该元素只包含一个timestamp字段。
4、流状态标记WatermarkStatus,用来通知Task是否会继续接收到上游的记录或者Watermark。该元素包含有2个状态值,空闲状态IDLE和活动状态ACTIVE。
二、算子概述
1、Transformation概念表达上下游关系,将各个步骤的业务逻辑组织成一个流水线。但Transformation不关心数据执行时刻的物理来源、序列化、转发等行为,运行时刻的行为交由Flink算子概念去处理。Flink算子负责从上游获取数据、交给UDF执行、转发UDF结果数据给下游等行为,并负责容错方面的支持。Flink作业运行时由Task组成一个Dataflow,每个Task中包含一个或多个算子,1个算子就是一个计算步骤,具体计算由算子类AbstractUdfStreamOperator中的userFunction字段来执行。
2、Flink算子类的主要继承体系如下,其中(I)代表接口、(A)代表抽象类、(C)代表普通类、->代表类或接口之间implements或extends关系。
StreamOperator(I) -> AbstractStreamOperator(A) -> AbstractUdfStreamOperator(A)
StreamOperator(I) -> OneInputStreamOperator(I)
StreamOperator(I) -> TwoInputStreamOperator(I)
3、DataStream api方法几乎与DataStream算子一一对应。
其中StreamMap、StreamFlatMap、StreamFilter、StreamSink、StreamSource继承或实现抽象类AbstractUdfStreamOperator和接口OneInputStreamOperator,StreamProject继承或实现抽象类AbstractStreamOperator和接口OneInputStreamOperator。
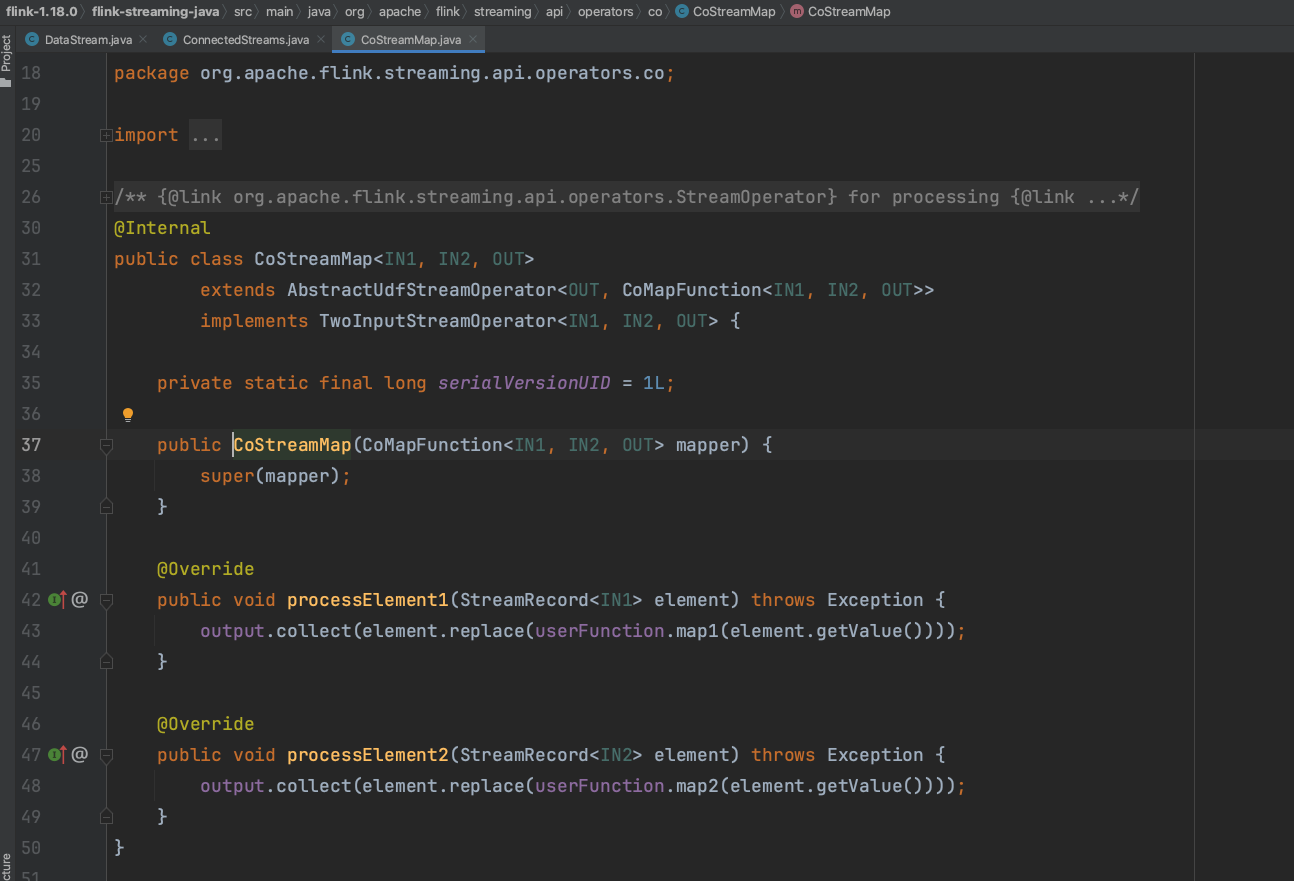
数据流ConnectedStreams的map(...)、flatMap(...)、process(...)等api方法产生CoStreamMap、CoStreamFlatMap、CoProcessOperator算子,这些算子继承或实现抽象类AbstractUdfStreamOperator和接口TwoInputStreamOperator。
4、所有算子都包含生命周期管理、状态与容错管理、数据处理三部分功能。其中生命周期管理、状态与容错管理主要由AbstractStreamOperator及其实现类负责,数据处理主要由OneInputStreamOperator和TwoInputStreamOperator及其实现类负责。
如下图可知AbstractUdfStreamOperator类在调用setup(...)、open()、close()等生命周期管理方法时,都是先处理算子相关过程,最后调用UDF函数setup(...)、open()、close()等方法。
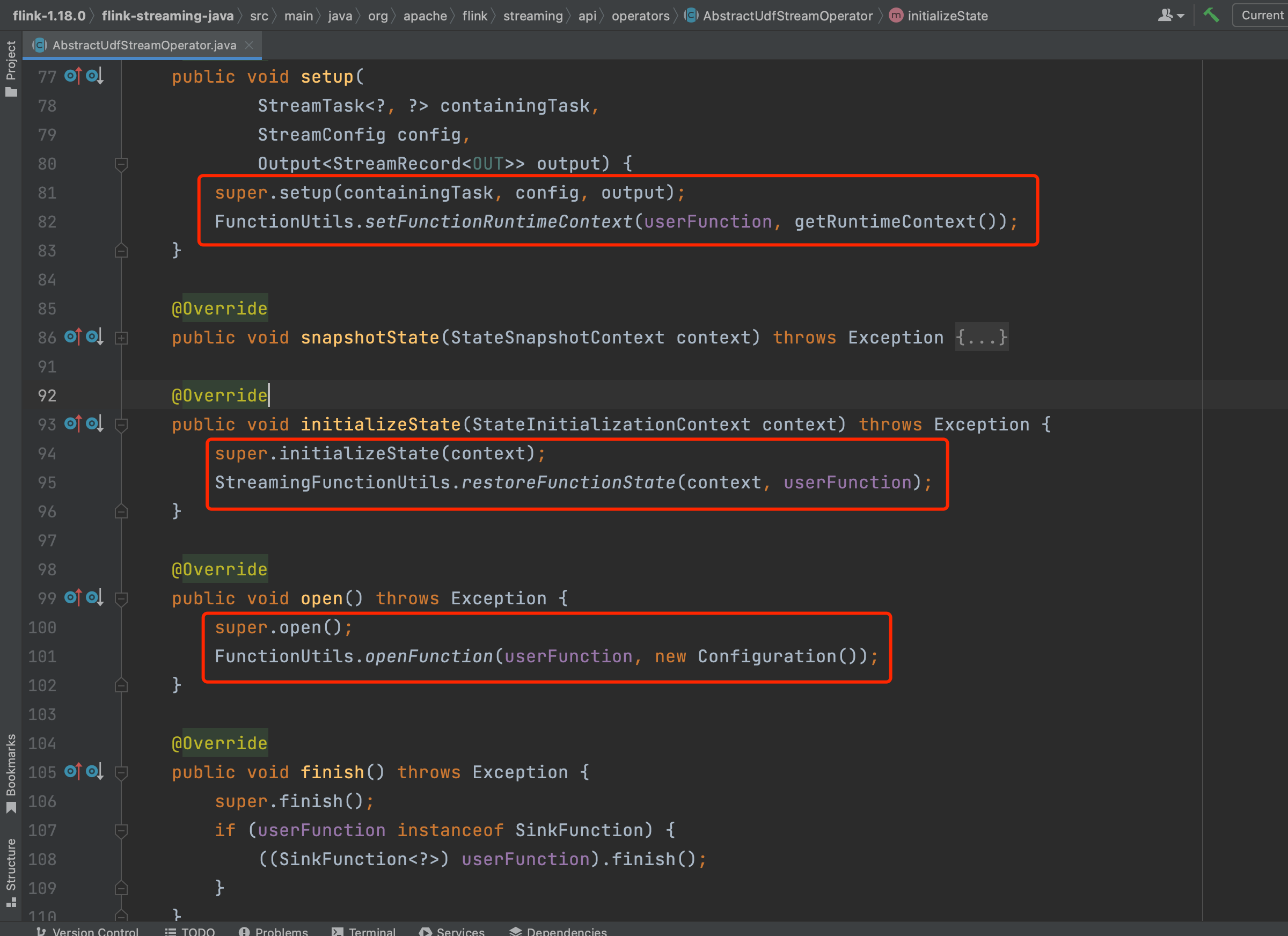
OneInputStreamOperator同时继承于2个接口StreamOperator和Input。其中Input接口定义数据流元素处理的相关方法,在具体算子实现类如StreamMap中有processElement(...)方法的实现。双输入流算子TwoInputStreamOperator对于两个输入流提供了8个关键处理方法分别处理两个输入流中的4种数据流元素。

5、算子其他方面补充。在新版本Flink实现中存在两套算子体系,Flink DataStream和Flink SQL算子体系、Blink SQL算子体系,本系列着重介绍DataStream算子体系。Blink SQL算子体系可参考flink-table-runtime项目实现。异步算子可参考flink-examples项目中AsyncIOExample实例去理解。
三、UDF自定义函数概述
Flink计算引擎通过提供各个api接口和业务逻辑打交道。实际开发时,Flink作业开发者实现诸如MapFunction等Function子接口来表达业务逻辑。
按输入输出特点来看,Flink中UDF大概分为3类,分别为SourceFunction、SinkFunction、MapFunction等一般Function。SourceFunction只有下游算子,无上游算子。SinkFunction只有上游算子,无下游算子。一般Function既有上游算子也有下游算子。SourceFunction和SinkFunction主要用在Flink连接器中,也会在自定义读取、写出数据的时候使用。
按接口的层级来看,UDF从高阶Function到低阶Function如下图所示。
待补充重要的Function案例(新Source类实现原理及应用)

四、Flink api方法、Transformation、StreamOperator、UDF生成过程汇总
上篇随笔叙述Transformation转换过程时未提及StreamOperator生成逻辑,下面补充下StreamOperator生成过程。DataStreamSource生成、map(...)、flatMap(...)调用、DataSink生成过程比较简单,下面简要叙述下简单api调用过程,后面会着重分析2个较复杂api的调用过程。
1、简单api调用过程
(1)、DataStreamSource:在Flink作业开发中调用方法StreamExecutionEnvironment.addSource(SourceFunction<OUT> function)会生成DataStreamSource,方法实现中代码final StreamSource<OUT, ?> sourceOperator = new StreamSource<>(function)会将udf函数封装成AbstractUdfStreamOperator的子类StreamSource,并在DataStreamSource构造函数中利用sourceOperator生成PhysicalTransformation的子类LegacySourceTransformation实例。
(2)、map(...):在Flink作业开发中编写代表业务逻辑的MapFunction UDF函数,以入参形式传入到方法DataStream.map(...)里。map(...)方法执行时会生成OneInputStreamOperator的子类StreamMap实例并作为方法transform(...)入参参与到OneInputTransformation实例的构建过程中。再次体会下:每个DataStream的Transformation成员表示该DataStream从上游的DataStream使用该Transformation而来。
注: 在PhysicalTransformation子类中成员变量StreamOperatorFactory<T> operatorFactory以工厂类的形式包含StreamOperator算子。
2、connect(...)双流后map(...)等api调用过程
(1)、ds1.connnect(ds2)时,利用已有的environment,构建ConnectedStreams实例。
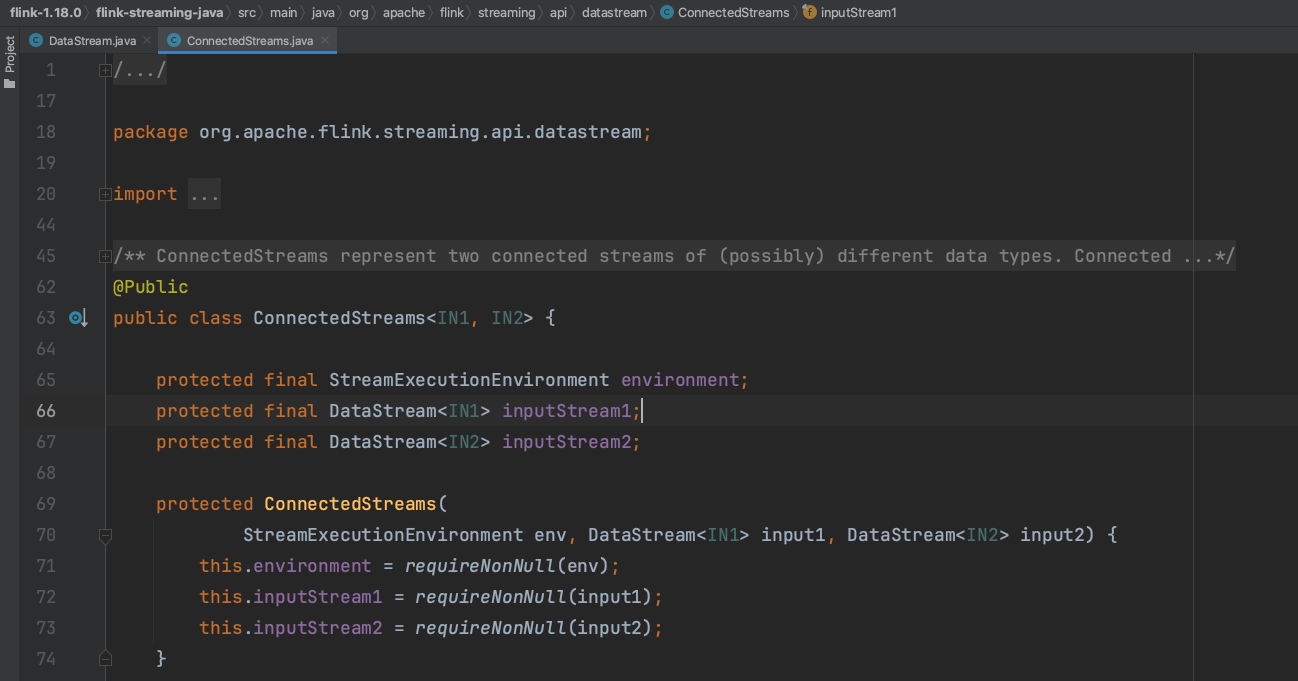
(2)、如下图可知,ConnectedStreams流包含3个关键成员实例environment、inputStream1、inputStream2。
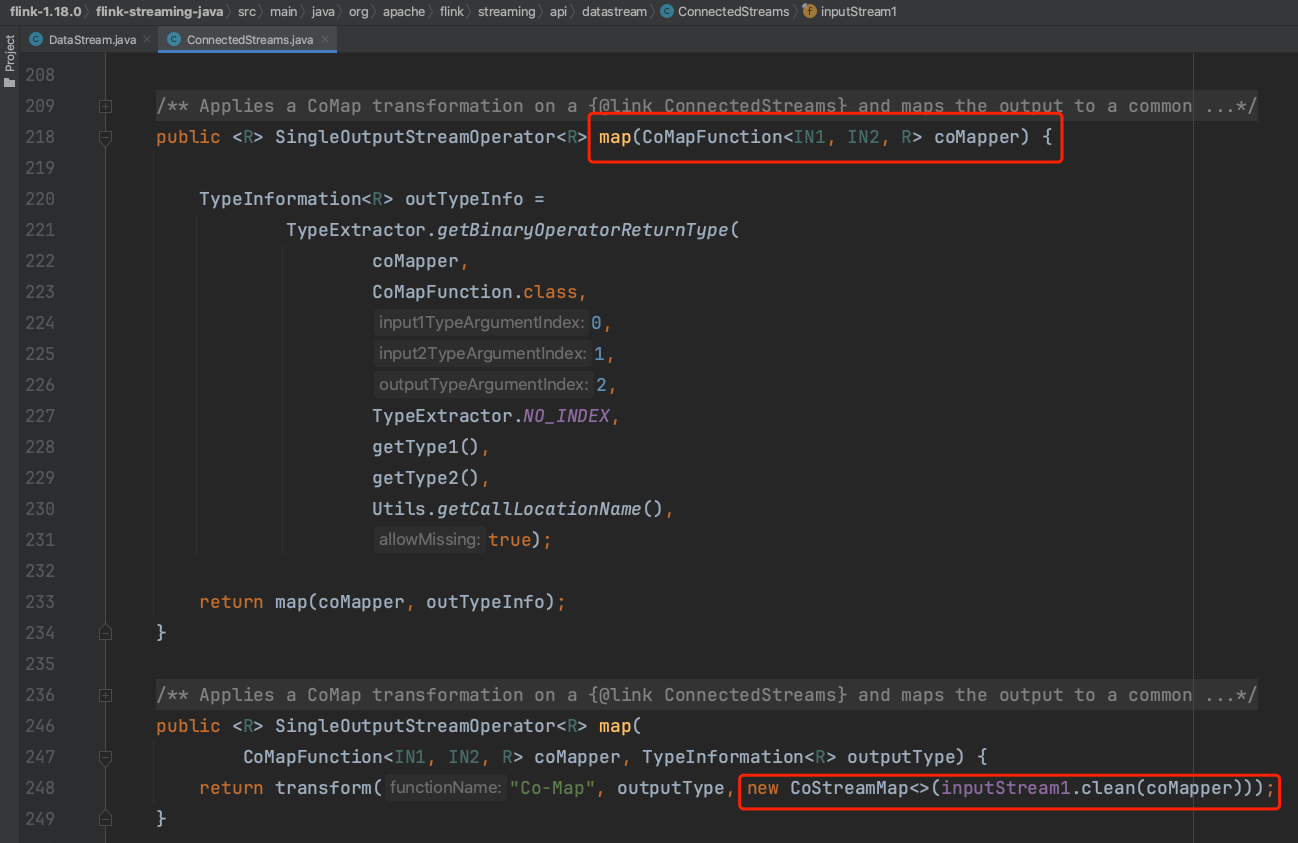
(3)、ConnectedStreams实例在调用方法map(...)时传入CoMapFunction实例,Flink框架使用UDF:CoMapFunction实例生成双输入流算子TwoInputStreamOperator子类CoStreamMap实例。最终调用方法doTransform(...)生成双输入流TwoInputTransformation进而生成DataStream实例returnStream并返回。UDF:CoMapFunction方法map1处理inputStream1流的数据,方法map2处理inputStream2流的数据。getExecutionEnvironment().addOperator(transform);//代码调用会将transform添加到StreamExecutionEnvironment的transformations集合列表中。


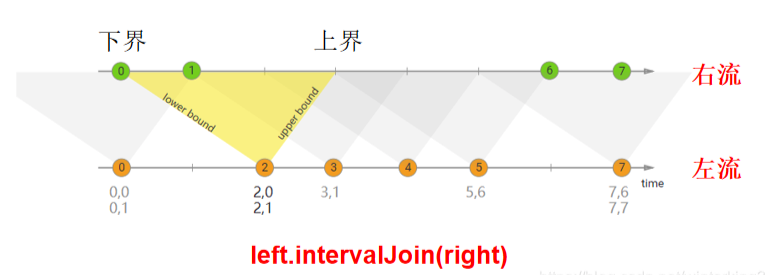
3、Interval Join调用过程
Interval Join的使用入口是KeyedStream流类型,输出结果为普通DataStream流类型。使用方法如下:
leftKeyedStream .intervalJoin(rightKeyedStream) .between(lowerBoundTime,upBoundTime) .lowerBoundExclusive() .upperBoundExclusive() .process(ProcessJoinFunction)
原理是指定一个作用在leftKeyedStream左流上的时间范围,按左右流相同的key进行关联。关联的数据范围如下:
{{leftKeyedStream.timestamp+lowerBoundTime}} <= rightKeyedStream.timestamp <= {{leftKeyedStream.timestamp+upBoundTime}}
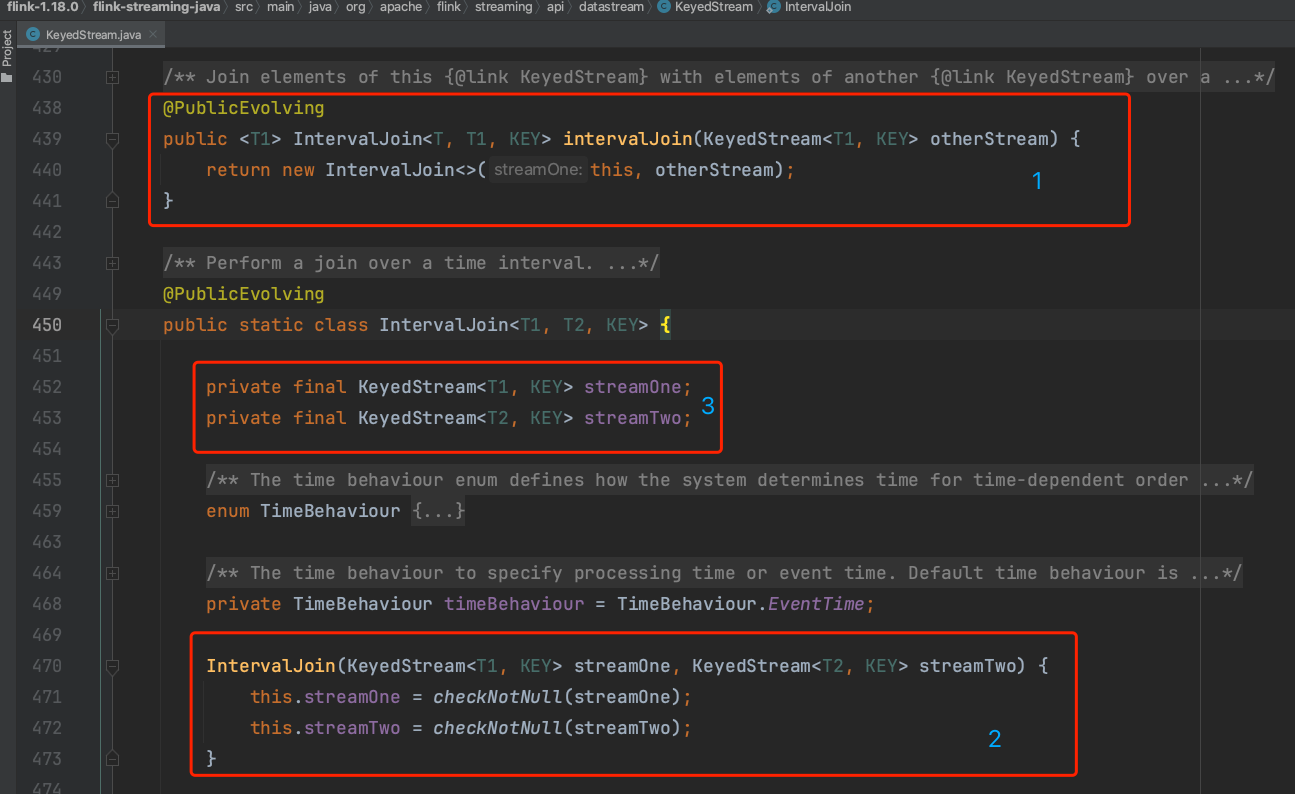
源码解析如下:
(1)、leftKeyedStream.intervalJoin(rightKeyedStream)时生成KeyedStream类的静态内部类IntervalJoin实例并设置成员变量。
(2)、调用方法between(...)设置作用于rightStream流实例数据的上下时间界限,生成IntervalJoined静态内部类实例。
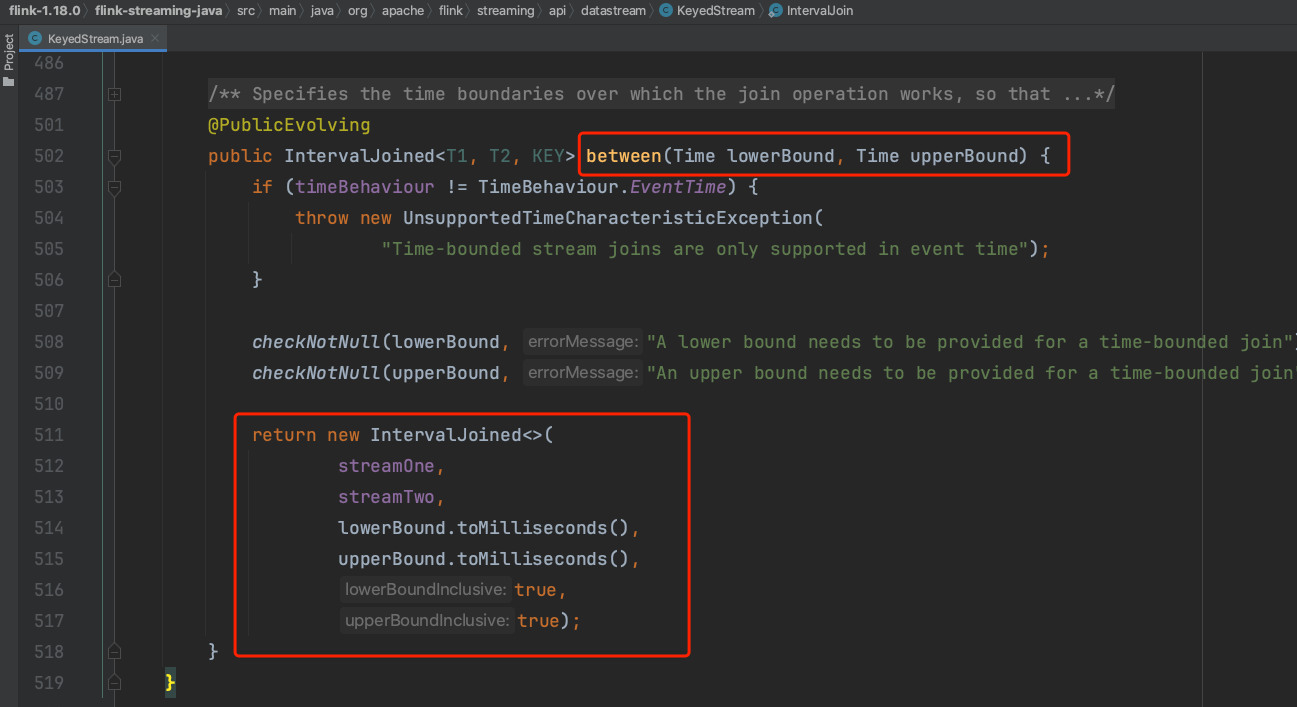
(3)、可选调用lowerBoundExclusive和upperBoundExclusive,设置上下时间界限的开闭区间。
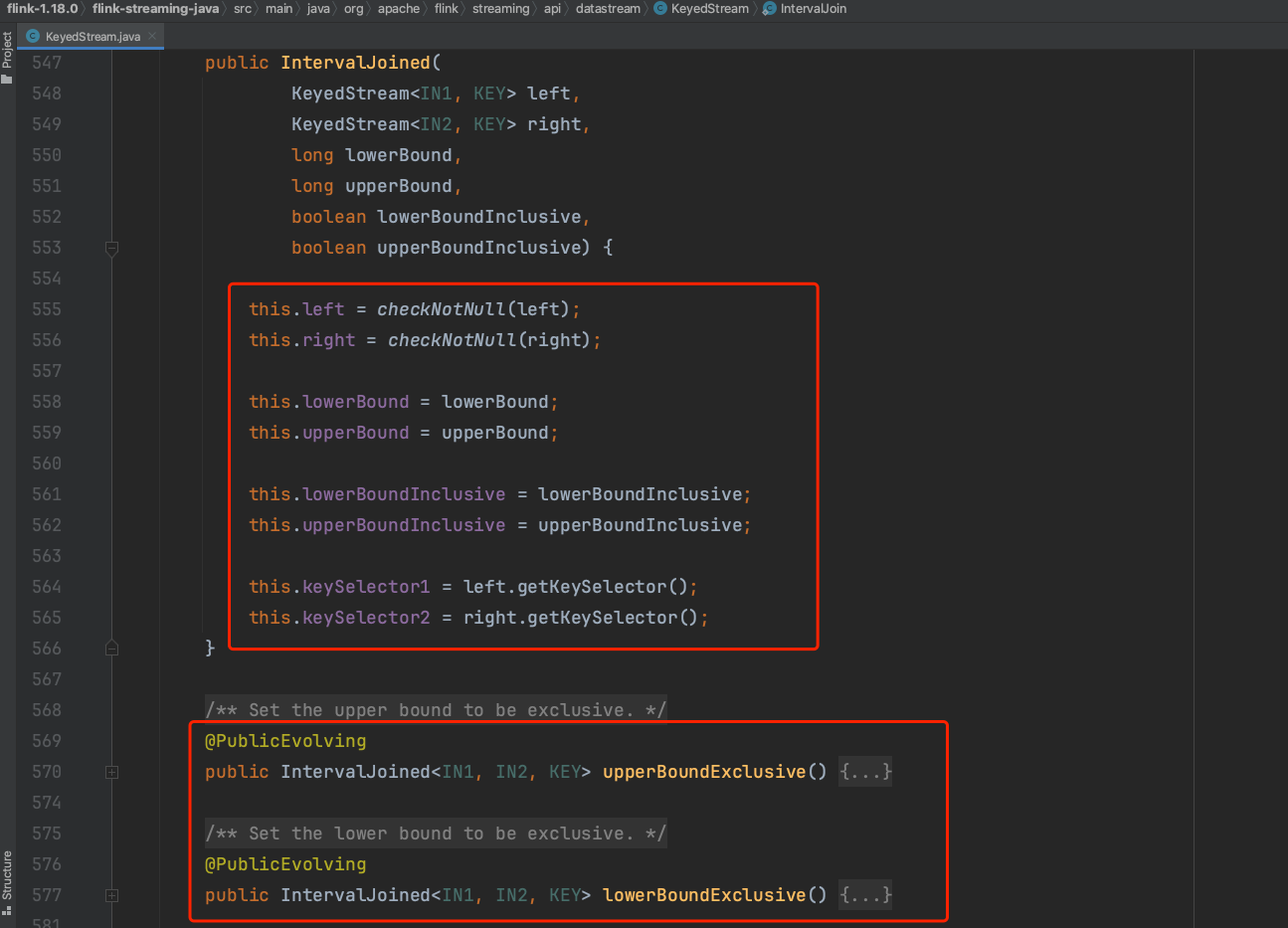
(4)、Flink应用开发人员实现ProcessJoinFunction实例所代表的业务逻辑,调用方法IntervalJoined.process(...)生成双输入流TwoInputStreamOperator类的子类IntervalJoinOperator实例,最后可知借用方法connect(...)生成transformation并返回结果DataStream实例。

(5)、详解下IntervalJoinOperator实现原理,在算子处理数据时分别调用方法processElement1(...)、processElement2,第二个形参区别当前处理的流实例,用最后形参区分左右流。
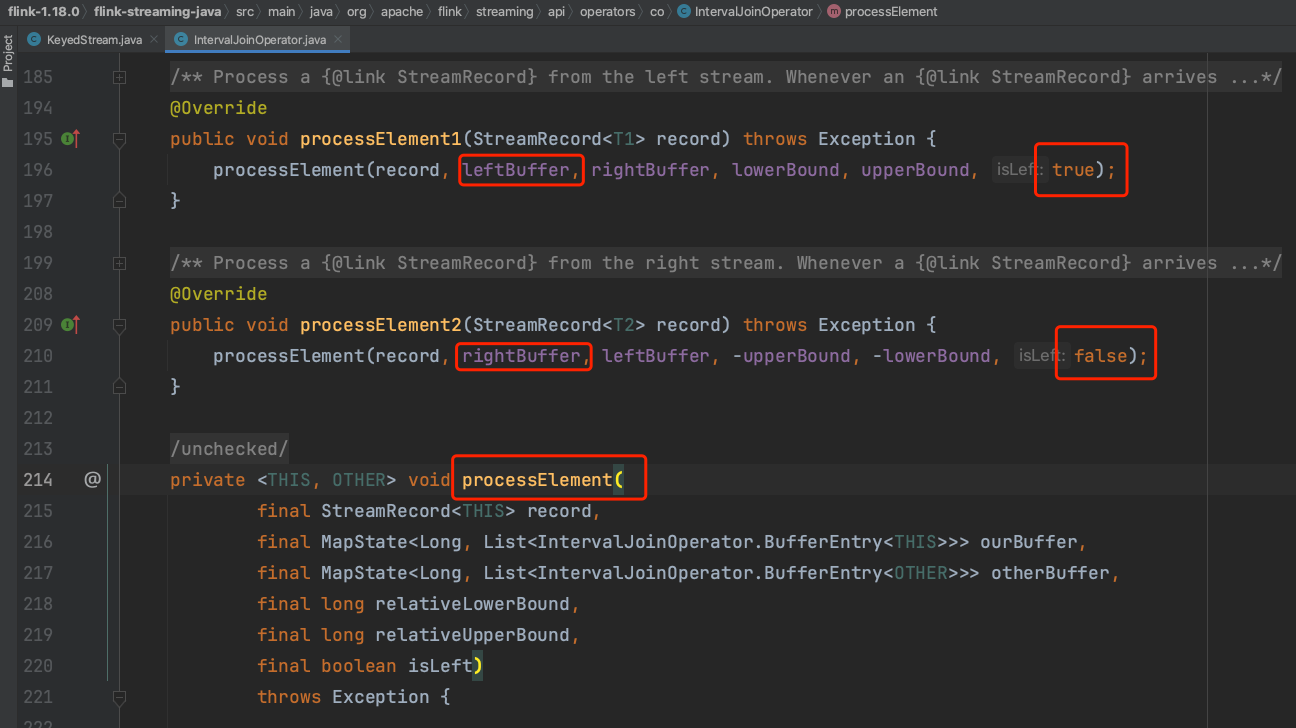
(6)、在方法processElement(...)实现中,根据rightStream流中每个数据的时间戳和上下时间位移,生成一个时间区间。将leftStream中每个数据时间戳和时间区间做比对,不在时间区间内的左流数据丢掉,在时间区间内的左流数据调用ProcessJoinFunction业务逻辑处理。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号