软件工程第二次作业-个人项目:论文查重
| 作业课程 | 班级的链接 |
|---|---|
| 作业要求 | 个人项目 |
| 作业目标 | 学习PSP表的使用以及独立完成一个项目 |
1、作业github链接
2、PSP表格
| PSP2.1 | 个人软件流程阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 45 |
| Estimate | 估计这个任务需要多少时间 | 840 | 1290 |
| Development | 开发 | 300 | 300 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 45 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 120 | 150 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 60 | 120 |
| Test Repor | 测试报告 | 60 | 45 |
| Size Measurement | 计算工作量 | 30 | 45 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 810 | 1290 |
3、计算模块接口的设计与实现过程
-
查询相关资料,发现检测文本相似度的有几种方法,选择使用余弦相似度,可以使用词向量(如Word2Vec、GloVe)或TF-IDF(Term Frequency-Inverse Document Frequency)来构建文本向量,然后计算向量之间的余弦相似度。余弦相似度是一种用于衡量两个向量之间夹角的余弦值,其值范围在[-1, 1]之间。余弦相似度越接近1,表示两个向量越相似;越接近-1,表示两个向量越不相似。
![]()
-
代码一共有四个函数,分别是,
read_text_file函数,读取文本文件,main函数,执行主要逻辑,calculate_cosine_similarity函数用于计算余弦相似度,text_to_vector函数用于将文本转换为词频向量。它的作用是统计文本中每个词语出现的频次,将这些词语及其频次构成一个词频向量。 -
关键函数:计算余弦相似度函数
def calculate_cosine_similarity(vec1, vec2): """ 计算余弦相似度 """ # 相同的词语 common_words = set(vec1.keys()) & set(vec2.keys()) # 计算点积 dot_product = sum(vec1[word] * vec2[word] for word in common_words) # 计算2-范数 norm1 = math.sqrt(sum(vec1[word] ** 2 for word in vec1)) norm2 = math.sqrt(sum(vec2[word] ** 2 for word in vec2)) # 计算查重率 similarity = dot_product / (norm1 * norm2) if (norm1 * norm2) != 0 else 0 print(similarity) return similarity
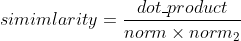
4、计算模块接口部分的性能改进
- 一开始使用的是编辑距离(一个文本要进行多少次操作变成另外一个文本)计算查重率,由于IO速度以及使用二维矩阵处理几千字的文本使用的时间过于长。

- 然后考虑分块处理文字,分成一千块处理文字然后计算重复率

- 但是运行时间并不达标,决定换一种方式计算,使用余弦相似度计算相似度

- 性能分析图
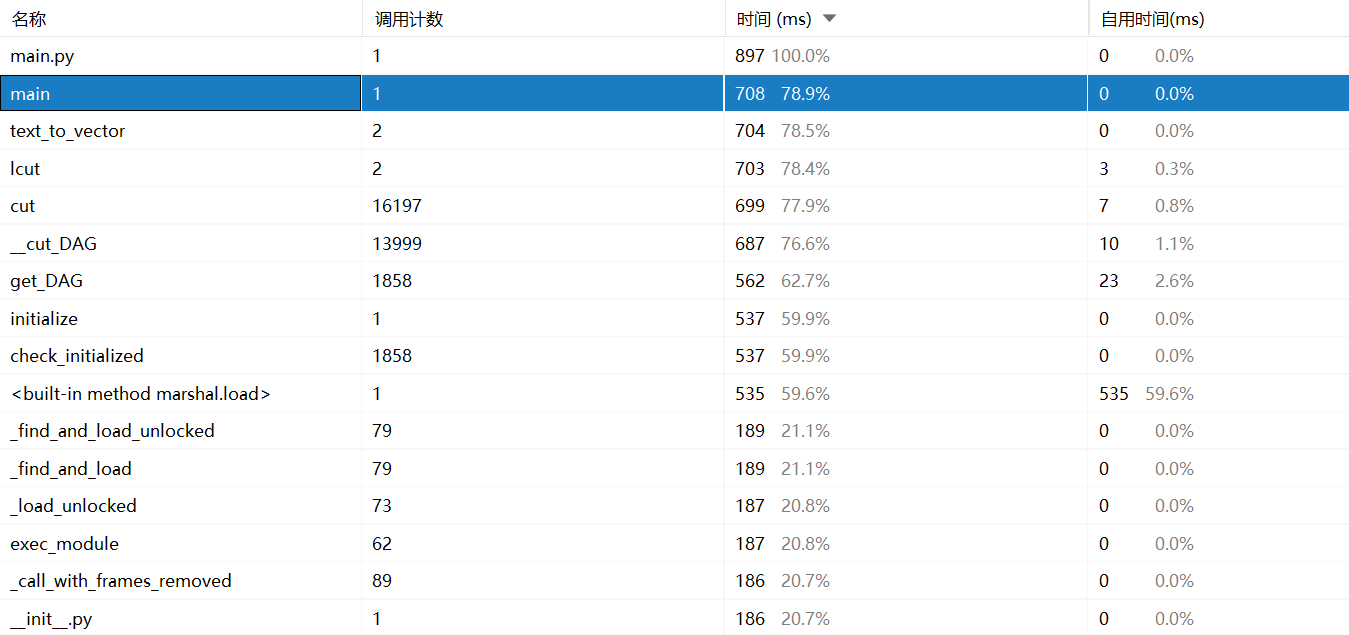
消耗最大多的函数为main函数
5、计算模块部分单元测试展示
-
test_open_failure测试了读取文件的函数def test_open_failure(self): # 模拟一个文件路径 file_path = 'some_file.txt' # 使用unittest.mock.patch模拟open函数,返回一个抛出异常的文件对象 with patch('builtins.open', mock_open()) as mock_file: mock_file.side_effect = Exception("File open failed") # 尝试读取文件 result = read_text_file(file_path) self.assertIsNone(result) # 期望返回None -
test_open_notfound测试了读取文件的函数def test_open_notfound(self): # 模拟一个文件路径 file_path = 'some_file.txt' # 尝试读取文件 result = read_text_file(file_path) self.assertIsNone(result) # 期望返回None -
test_cosine_similarity测试了计算余弦相似度的函数。def test_open_notfound(self): # 模拟一个文件路径 file_path = 'some_file.txt' # 尝试读取文件 result = read_text_file(file_path) self.assertIsNone(result) # 期望返回None -
test_text_to_vector测试了将文本转换为词频向量的函数。def test_text_to_vector(self): text = "一位真正的作家永远只为内心写作,只有内心才会真实地告诉他,他的自私、他的高尚是多么突出。" expected_vector = {'的': 3, '他': 3, '内心': 2, '一位': 1, '真正': 1, '作家': 1, '永远': 1, '只': 1, '为': 1, '写作': 1, '只有': 1, '才': 1, '会': 1, '真实': 1, '地': 1, '告诉': 1, '自私': 1, '高尚': 1, '是': 1, '多么': 1, '突出': 1} vector = text_to_vector(text) self.assertDictEqual(vector, expected_vector) # 断言词频向量正确
构造测试数据的思路:
-
对于
test_open_failure,使用unittest.mock.patch来模拟文件打开函数,测试文件打开失败的情况。 -
对于
test_open_notfound,使用不存在的文件路径执行,测试文件不存在的情况。 -
对于
test_cosine_similarity,构造两个词频向量,然后计算它们的余弦相似度。预期相似度为0.8,这个值是事先计算好的。 -
对于
test_text_to_vector,构造一个文本,手工计算其词频向量,然后用函数计算得到词频向量。最后检查两者是否相等。
单元测试得到的测试覆盖率截图

6、计算模块部分异常处理说明
-
输入路径错误:
- 设计目标:捕获输入路径不合法的情况,例如输入为空或者输入文件不存在的路径的词频向量。
- 单元测试样例:输入为空或者输入文件不存在的路径的情况。
- 错误对应的场景:如果用户提供的文本为空者输入文件不存在的路径,程序应该捕获这种情况并给出相应的错误提示。
-
数学计算异常:
-
设计目标:捕获数学计算过程中可能出现的异常,例如除零错误。
-
单元测试样例:模拟除零错误的情况。
-
错误对应的场景:如果词频向量长度为零,计算余弦相似度时会发生除零错误,程序应该能够正确捕获并处理这种情况。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号