Golang高级语法:反射 + 并发
反射
变量内置 Pair 结构

var a string
a = "aceld"
var allType interface{}
allType = a
str, _ := allType.(string)
类型断言其实就是根据 pair 中的 type 获取到 value
tty, err := os.OpenFile("/dev/tty", os.O_RDWR, 0)
if err != nil {
fmt.Println("open file error", err)
return
}
var r io.Reader
r = tty
var w io.Writer
w = r.(io.Writer)
w.Write([]byte("HELLO THIS IS A TEST!!\n"))
仔细分析下面的代码:
- 由于 pair 在传递过程中是不变的,所以不管 r 还是 w,pair 中的 tpye 始终是 Book
- 又因为 Book 实现了 Reader、Wrtier 接口,所以 type 为 Book 可以调用 ReadBook() 和 WriteBook()
type Reader interface {
ReadBook()
}
type Writer interface {
WriteBook()
}
type Book struct {
}
func (b *Book) ReadBook() {
fmt.Println("Read a Book")
}
func (b *Book) WriteBook() {
fmt.Println("Write a Book")
}
func main() {
b := &Book{}
var r Reader
r = b
r.ReadBook()
var w Writer
w = r.(Writer)
w.WriteBook()
}
reflect
reflect 包中的两个重要方法:
func ValueOf(i interface{}) Value {...}
func TypeOf(i interface{}) Type {...}
反射的应用:
- 获取简单变量的类型和值:
func reflectNum(arg interface{}) {
fmt.Println("type : ", reflect.TypeOf(arg))
fmt.Println("value : ", reflect.ValueOf(arg))
}
func main() {
var num float64 = 1.2345
reflectNum(num)
}
type : float64 value : 1.2345
- 获取结构体变量的字段方法:
type User struct {
Id int
Name string
Age int
}
func (u User) Call() {
fmt.Println("user ius called..")
fmt.Printf("%v\n", u)
}
func main() {
user := User{1, "AceId", 18}
DoFieldAndMethod(user)
}
func DoFieldAndMethod(input interface{}) {
inputType := reflect.TypeOf(input)
fmt.Println("inputType is :", inputType.Name())
inputValue := reflect.ValueOf(input)
fmt.Println("inputValue is :", inputValue)
for i := 0; i < inputType.NumField(); i++ {
field := inputType.Field(i)
value := inputValue.Field(i).Interface()
fmt.Printf("%s: %v = %v\n", field.Name, field.Type, value)
}
for i := 0; i < inputType.NumMethod(); i++ {
m := inputType.Method(i)
fmt.Printf("%s: %v\n", m.Name, m.Type)
}
}
inputType is : User
inputValue is : {1 AceId 18}
Id: int = 1
Name: string = AceId
Age: int = 18
Call: func(main.User)
结构体标签
结构体标签的定义:
type resume struct {
Name string `info:"name" doc:"我的名字"`
Sex string `info:"sex"`
}
func findTag(str interface{}) {
t := reflect.TypeOf(str).Elem()
for i := 0; i < t.NumField(); i++ {
taginfo := t.Field(i).Tag.Get("info")
tagdoc := t.Field(i).Tag.Get("doc")
fmt.Println("info: ", taginfo, " doc: ", tagdoc)
}
}
func main() {
var re resume
findTag(&re)
}
info: name doc: 我的名字 info: sex doc:
结构体标签的应用:JSON 编码与解码
import (
"encoding/json"
"fmt"
)
type Movie struct {
Title string `json:"title"`
Year int `json:"year"`
Price int `json:"price"`
Actors []string `json:"actors"`
Test string `json:"-"`
}
func main() {
movie := Movie{"喜剧之王", 2000, 10, []string{"xingye", "zhangbozhi"}, "hhh"}
jsonStr, err := json.Marshal(movie)
if err != nil {
fmt.Println("json marshal error", err)
return
}
fmt.Printf("jsonStr = %s\n", jsonStr)
myMovie := Movie{}
err = json.Unmarshal(jsonStr, &myMovie)
if err != nil {
fmt.Println("json unmarshal error", err)
return
}
fmt.Printf("%v\n", myMovie)
}
jsonStr = {"title":"喜剧之王","year":2000,"price":10,"actors":["xingye","zhangbozhi"]}
{喜剧之王 2000 10 [xingye zhangbozhi] }
其他应用:orm 映射关系 …
并发知识
基础知识
早期的操作系统是单进程的,存在两个问题:
1、单一执行流程、计算机只能一个任务一个任务的处理
2、进程阻塞所带来的 CPU 浪费时间

多线程 / 多进程 解决了阻塞问题:
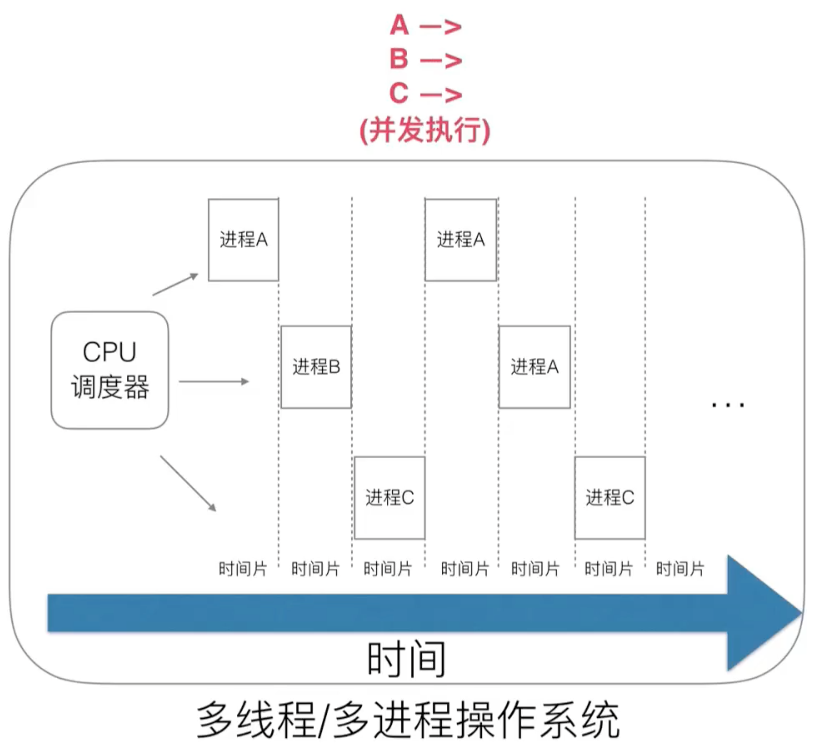
但是多线程又面临新的问题:上下文切换所耗费的开销很大。
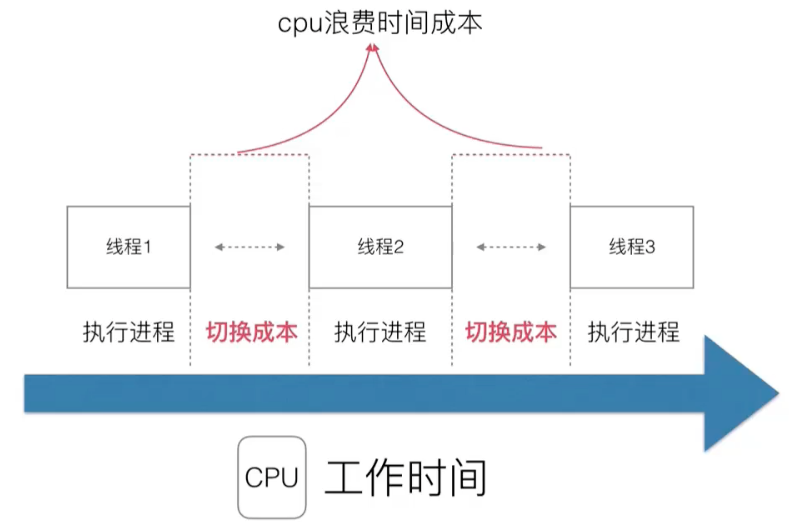
进程 / 线程的数量越多,切换成本就越大,也就越浪费。
有可能 CPU 使用率 100%,其中 60% 在执行程序,40% 在执行切换…
多线程 随着 同步竞争(如 锁、竞争资源冲突等),开发设计变的越来越复杂。
多线程存在 高消耗调度 CPU、高内存占用 的问题:
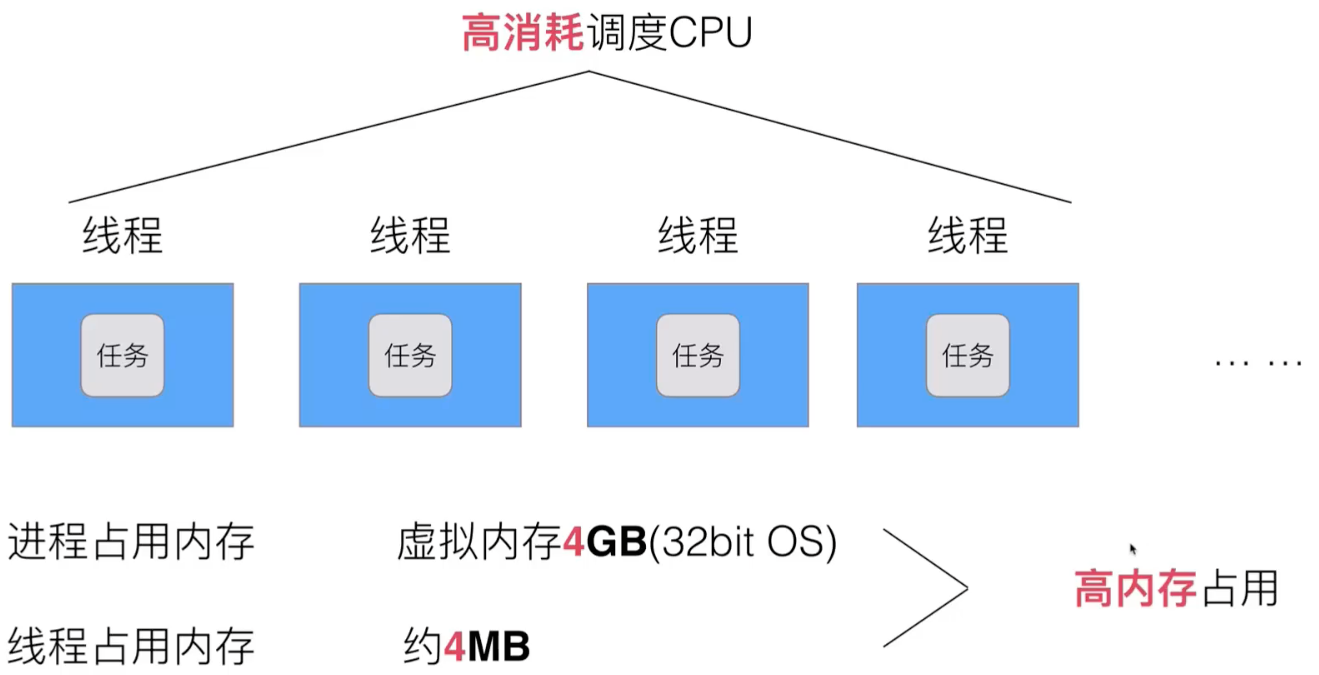
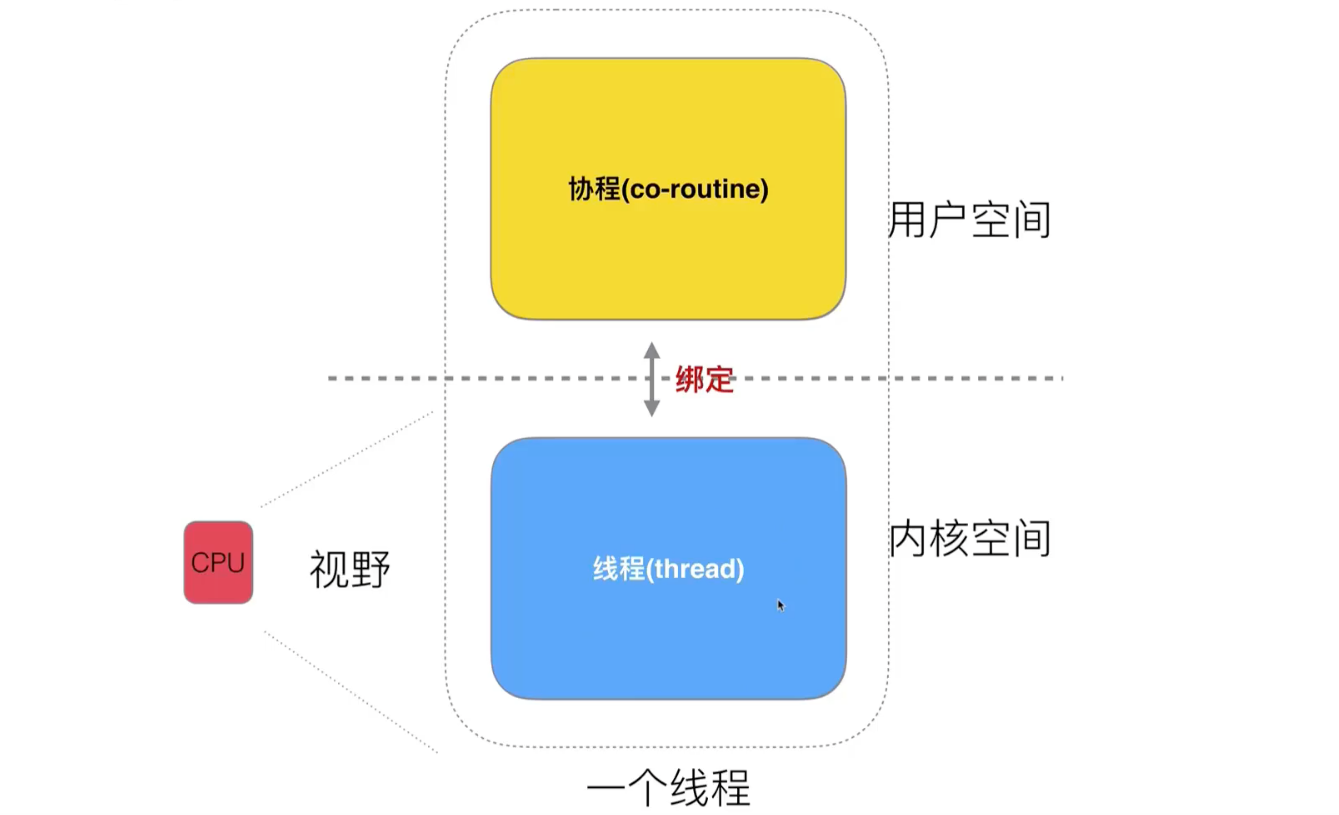
如果将内核空间和用户空间的线程拆开,也就出现了协程(其实就是用户空间的线程)
内核空间的线程由 CPU 调度,协程是由开发者来进行调度。
用户线程,就是协程。内核线程,就是真的线程。
然后在内核线程与协程之间,再加入一个协程调度器:实现线程与协程的一对多模型
- 弊端:如果一个协程阻塞,会影响下一个的调用(轮询的方式)
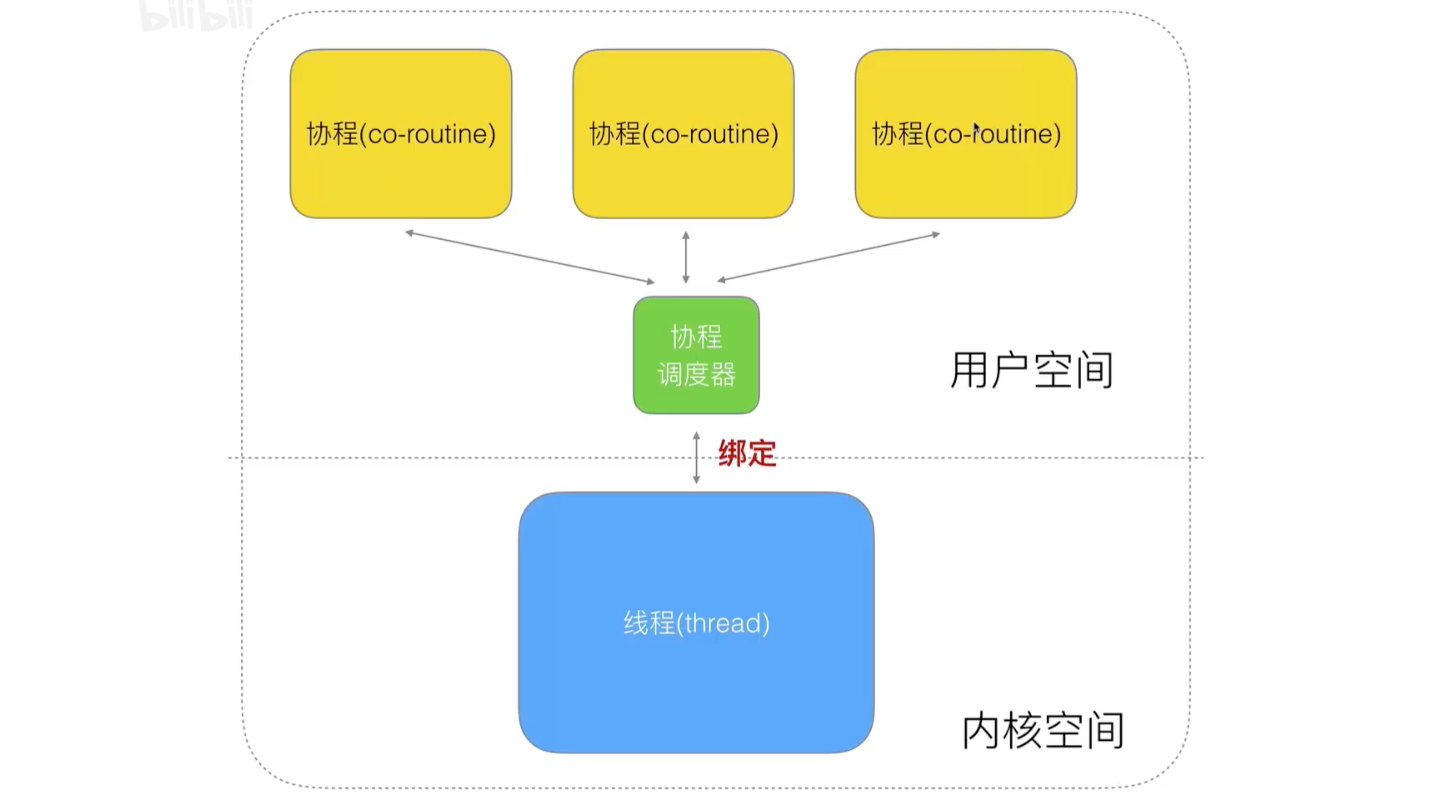
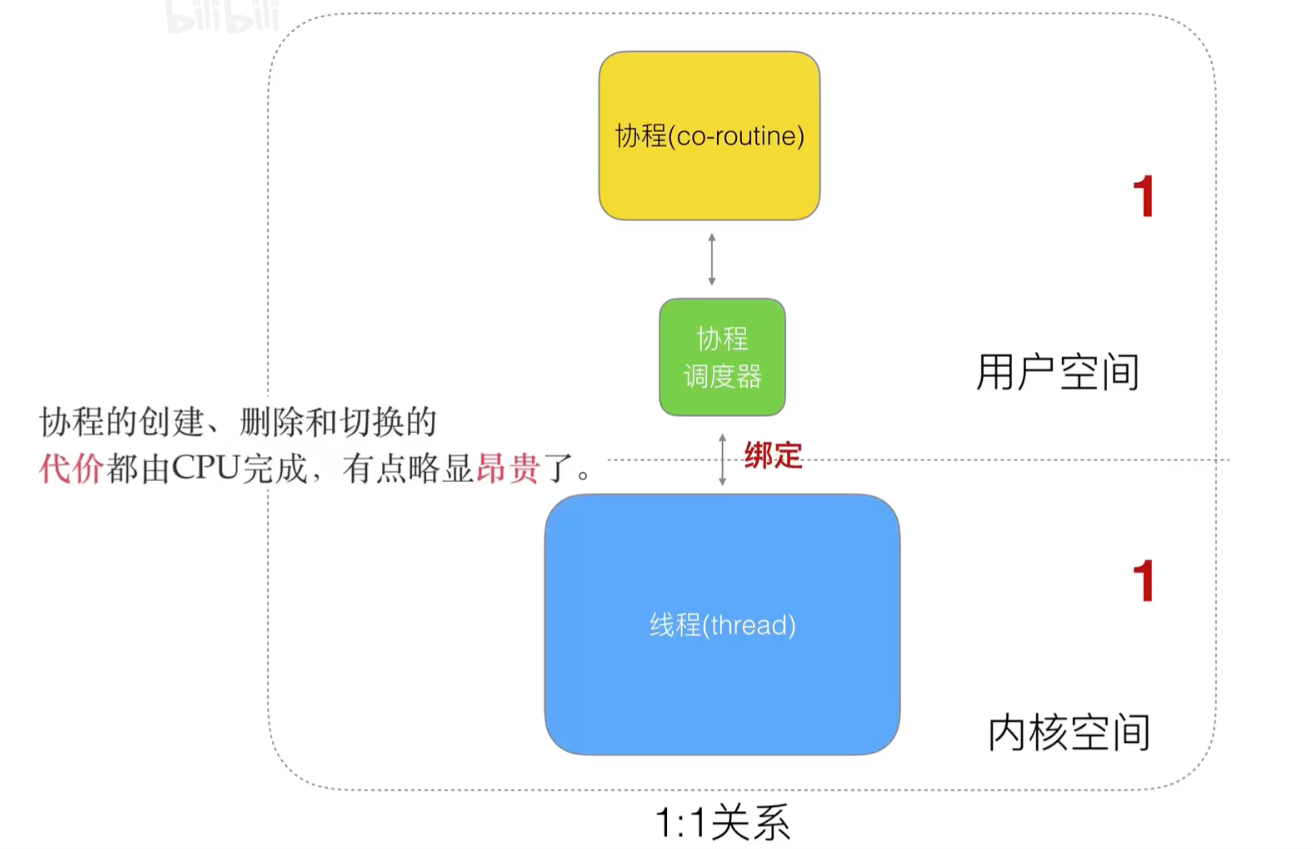
如果将上面的模型改成一对一的模型,虽然没有阻塞,但是和以前的线程模型没有区别了…
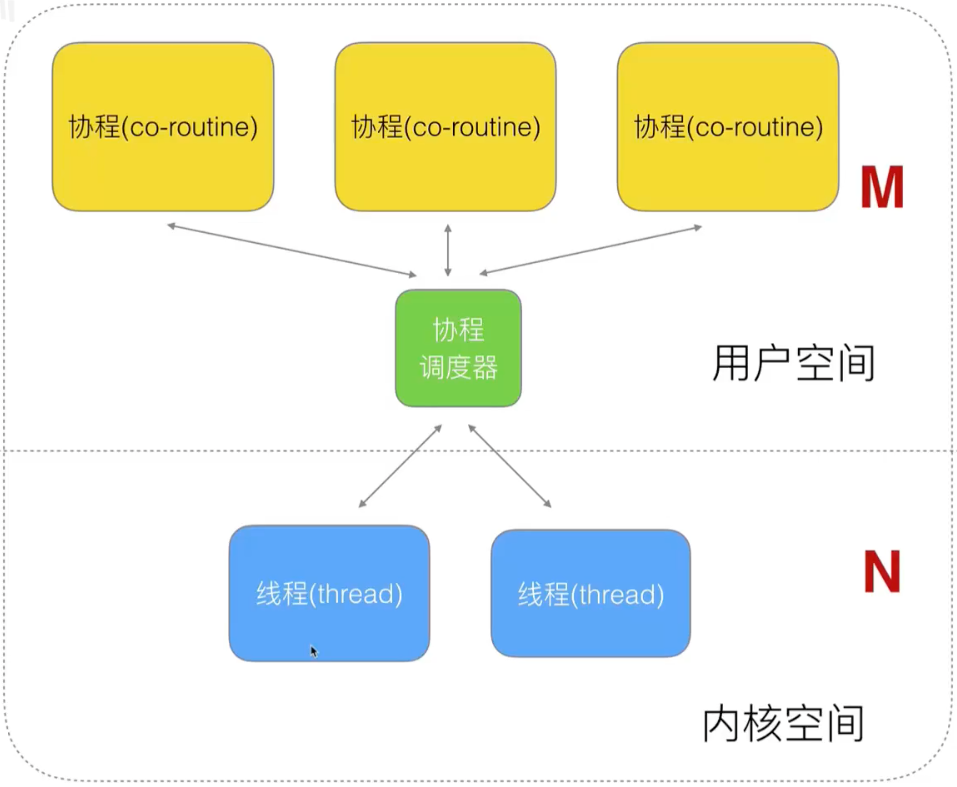
再继续优化成多对多的模型,则将主要精力放在优化协程调度器上:
内核空间是 CPU 地盘,我们无法进行太多优化。
不同的语言想要支持协程的操作,都是在用户空间优化其协程处理器。
Go 对协程的处理:

早期调度器的处理

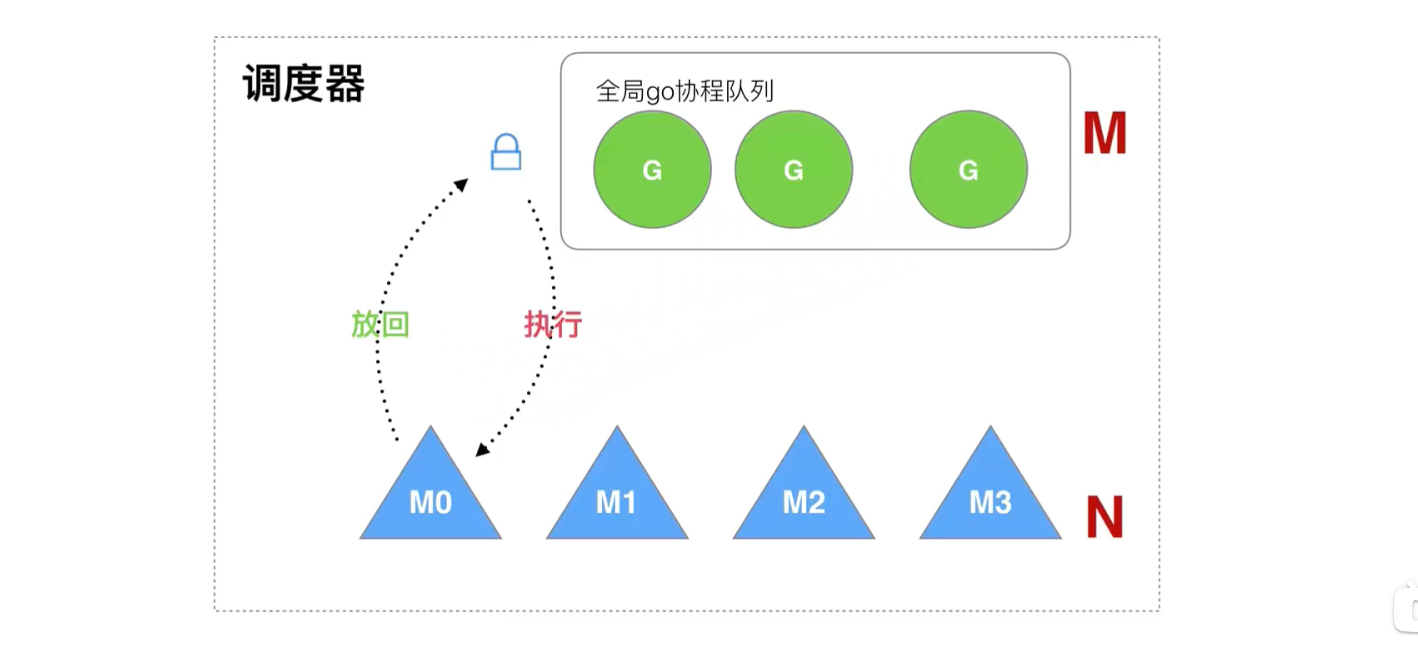
老调度器有几个缺点:
- 创建、销毁、调度 G 都需要每个 M 获取锁,形成了激烈的锁竞争。
- M 转移 G 会造成延迟和额外的系统负载。
- 系统调用(CPU 在 M 之前的切换)导致频繁的线程阻塞和取消阻塞操作,增加了系统开销。
GMP 模型
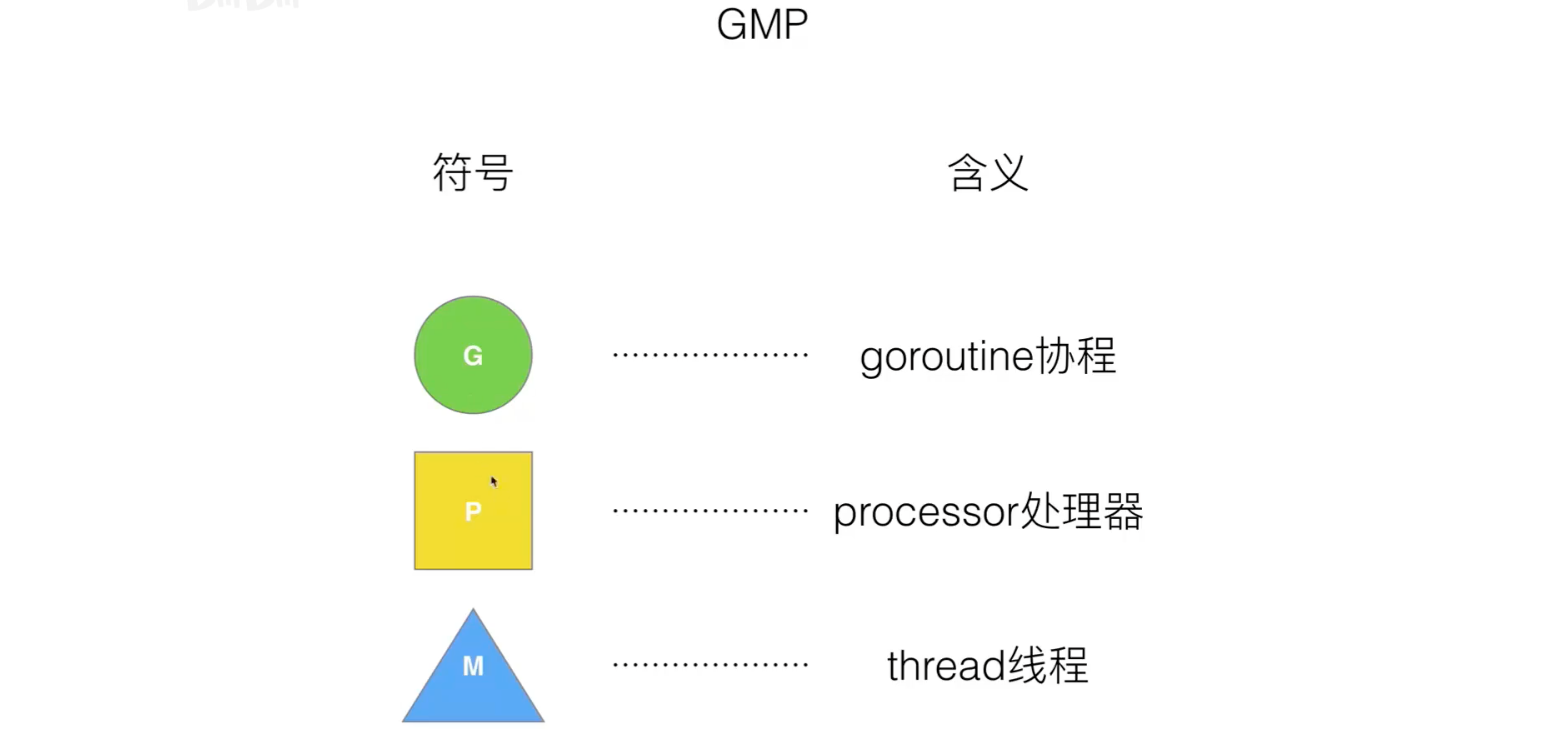
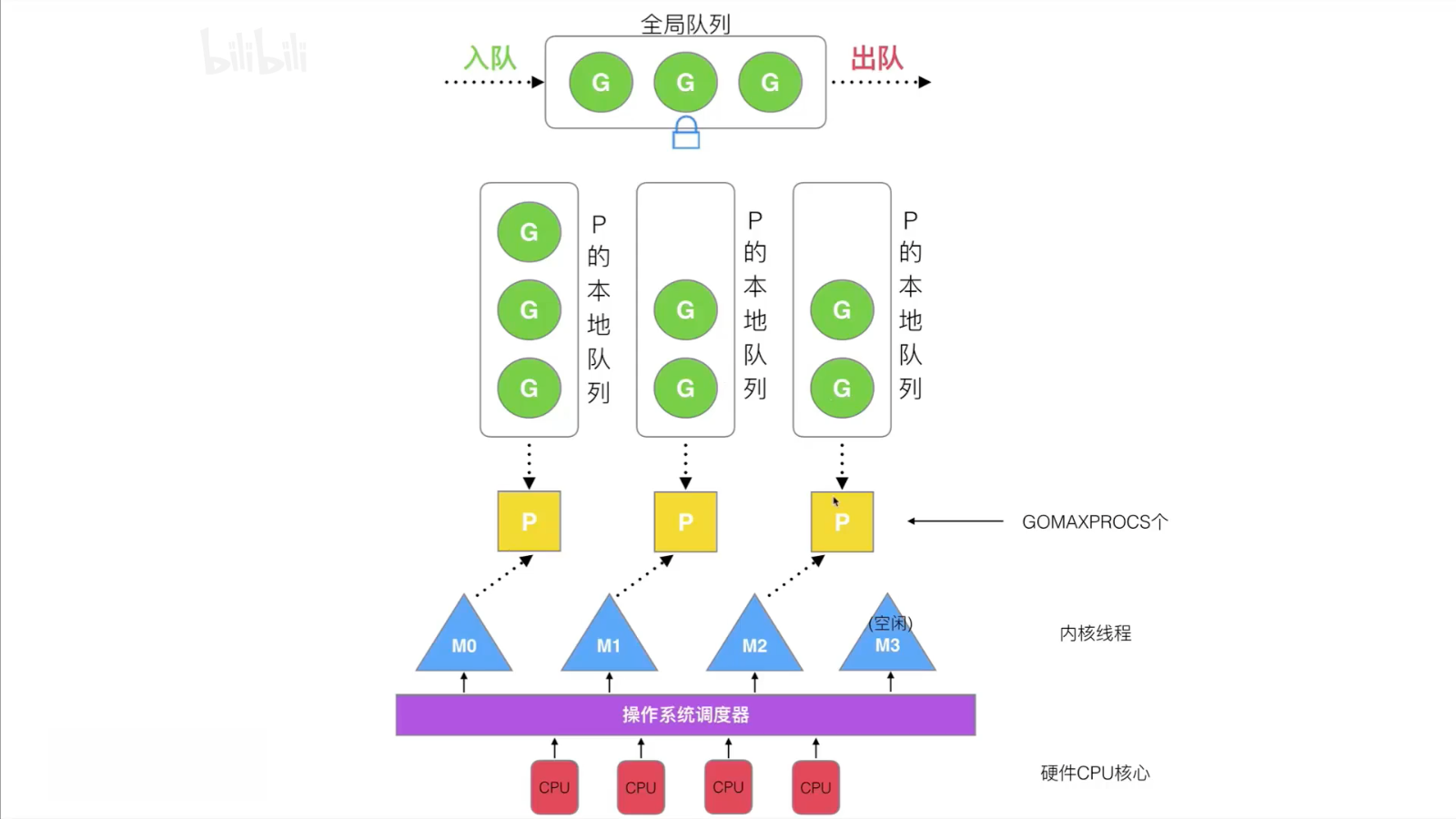
调度器的设计策略
调度器的 4 个设计策略:复用线程、利用并行、抢占、全局 G 队列
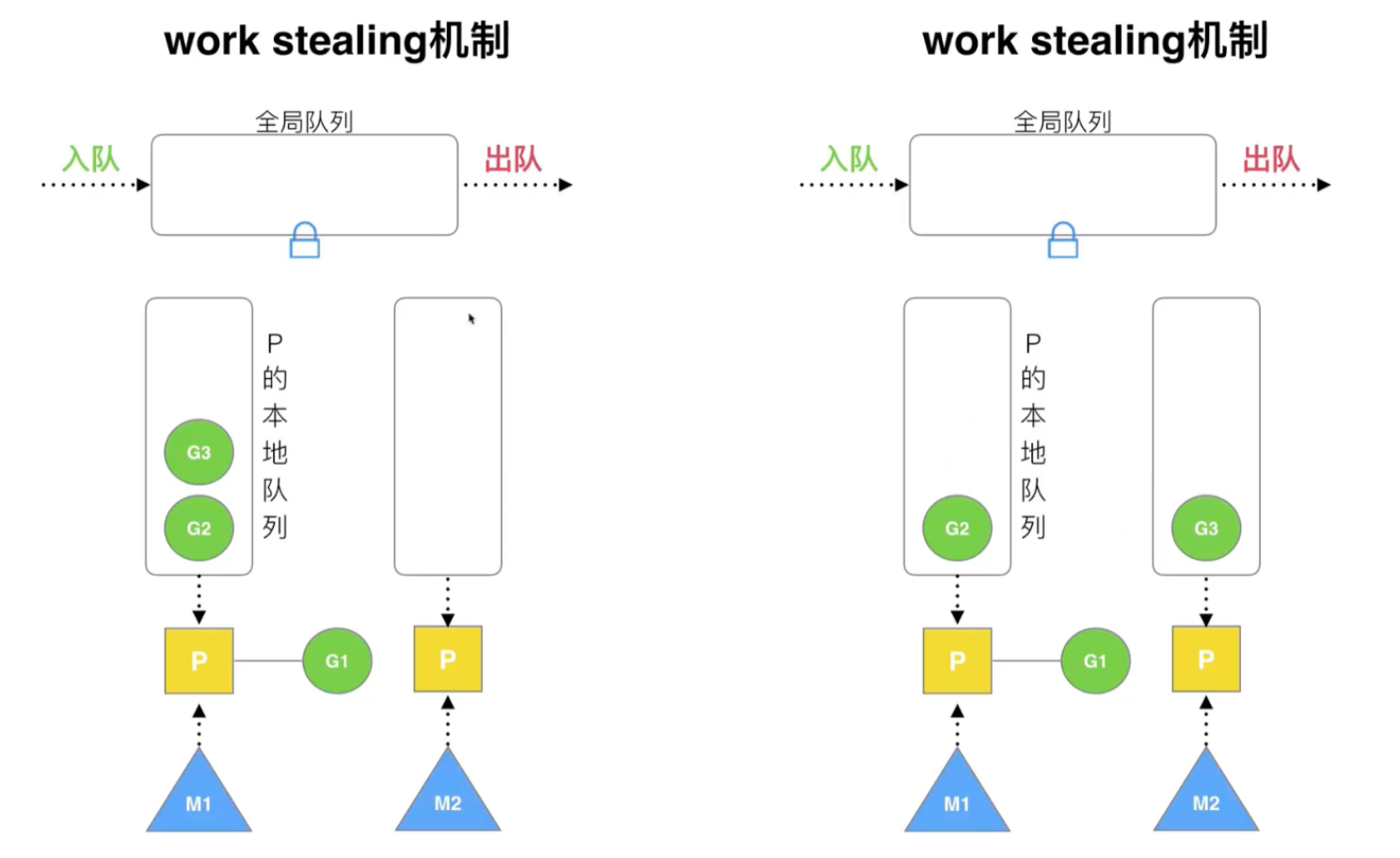
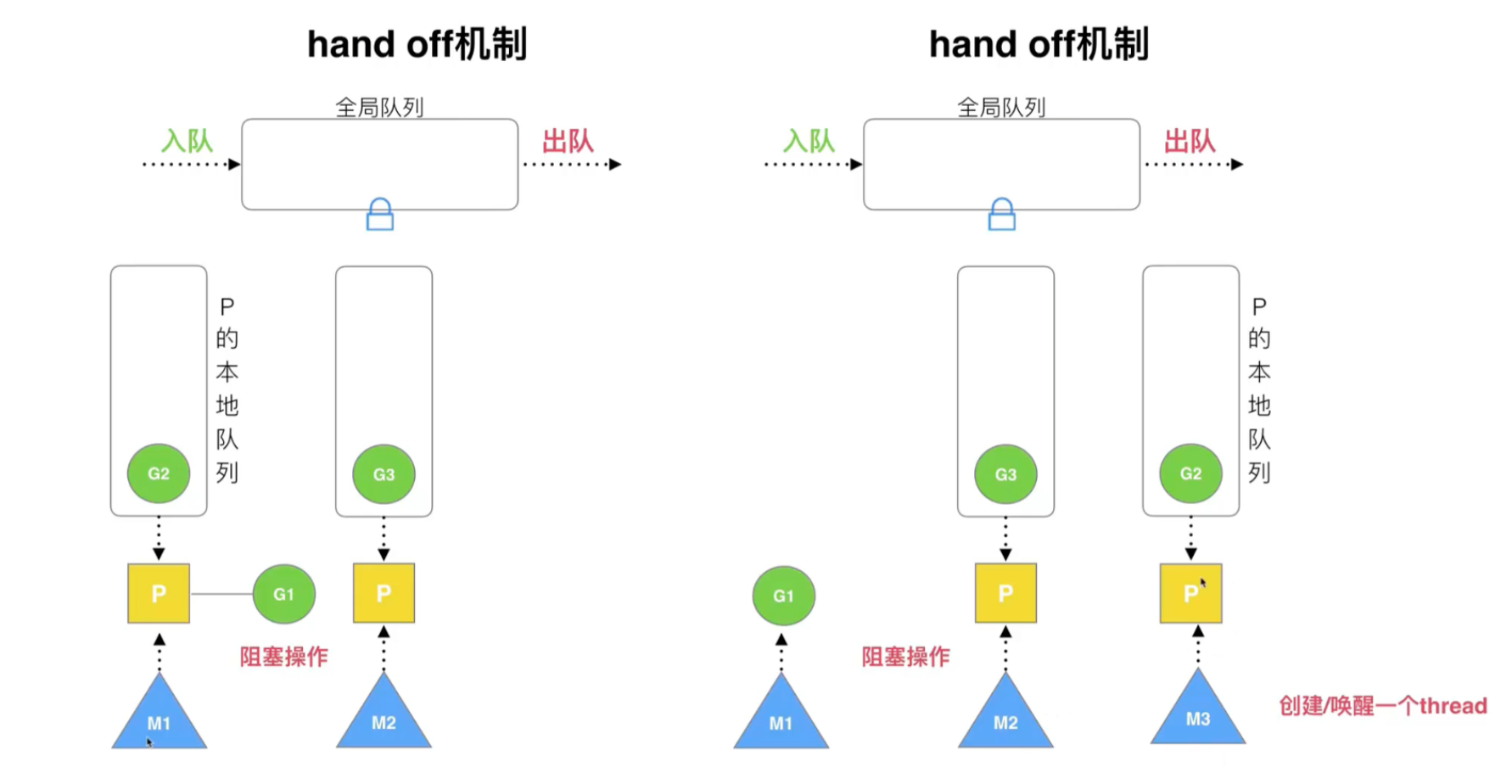
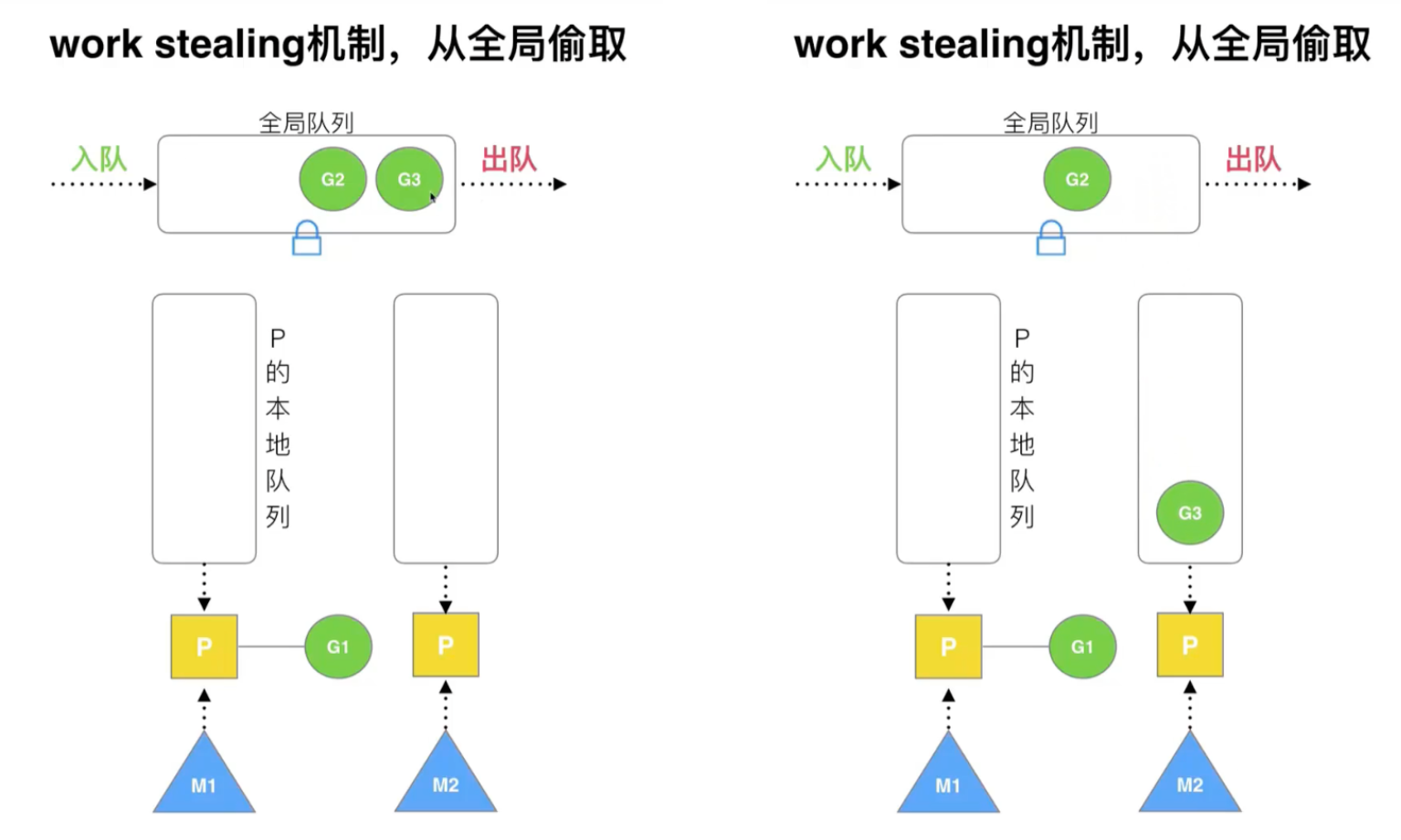
复用线程:work stealing、hand off
-
work stealing 机制:某个处理器的本地队列空余,从其他处理器中偷取协程来执行
注意,这里是从某个处理器的本地队列偷取,还有从全局队列中偷取的做法
- hand off 机制:如果某个线程阻塞,会将处理器资源让给其他线程。
利用并行:利用 GOMAXPROCS 限定 P 的个数 = CPU 核数 / 2
抢占:
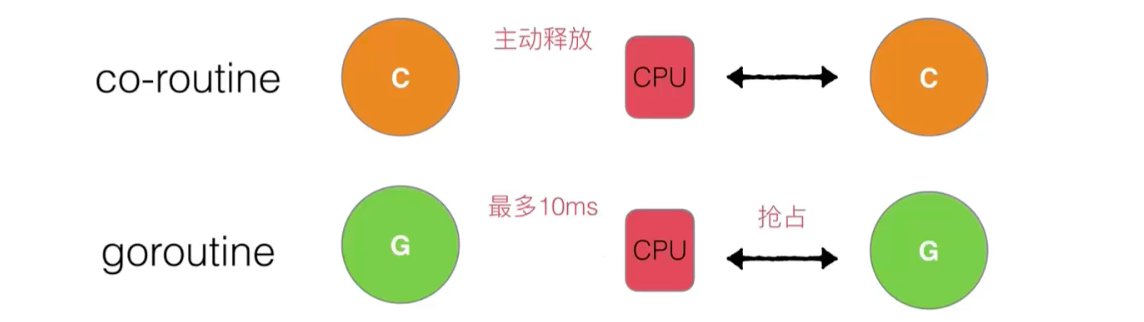
全局 G 队列:基于 warlk stealing 机制,如果所有处理器的本地队列都没有协程,则从全局获取。
并发编程
goroutine
创建 goroutine:
func newTask() {
i := 0
for {
i++
fmt.Printf("new Goroutie: i = %d\n", i)
time.Sleep(1 * time.Second)
}
}
func main() {
go newTask()
i := 0
for {
i++
fmt.Printf("main goroutine: i = %d\n", i)
time.Sleep(1 * time.Second)
}
}
main goroutine: i = 1 new Goroutie: i = 1 new Goroutie: i = 2 main goroutine: i = 2 main goroutine: i = 3 new Goroutie: i = 3 ...
退出当前的 goroutine 的方法 runtime.Goexit(),比较以下两段代码:
func main() {
go func() {
defer fmt.Println("A.defer")
func() {
defer fmt.Println("B.defer")
fmt.Println("B")
}()
fmt.Println("A")
}()
for {
time.Sleep(1 * time.Second)
}
}
B B.defer A A.defer
执行了退出 goroutine 的方法:
func main() {
go func() {
defer fmt.Println("A.defer")
func() {
defer fmt.Println("B.defer")
runtime.Goexit()
fmt.Println("B")
}()
fmt.Println("A")
}()
for {
time.Sleep(1 * time.Second)
}
}
B.defer A.defer
channel
channel 用于在 goroutine 之间进行数据传递:
make(chan Type) make(chan Type, capacity)
channel <- value <-channel x := <-channel x, ok := <-channel
channel 的使用:
func main() {
c := make(chan int)
go func() {
defer fmt.Println("goroutine 结束")
fmt.Println("goroutine 正在运行")
c <- 666
}()
num := <-c
fmt.Println("num = ", num)
fmt.Println("main goroutine 结束...")
}
goroutine 正在运行... goroutine结束 num = 666 main goroutine 结束...
上面的代码(使用 channel 交换数据),sub goroutine 一定会在 main goroutine 之后运行
- 如果 main goroutine 运行的快,会进入等待,等待 sub goroutine 传递数据过来
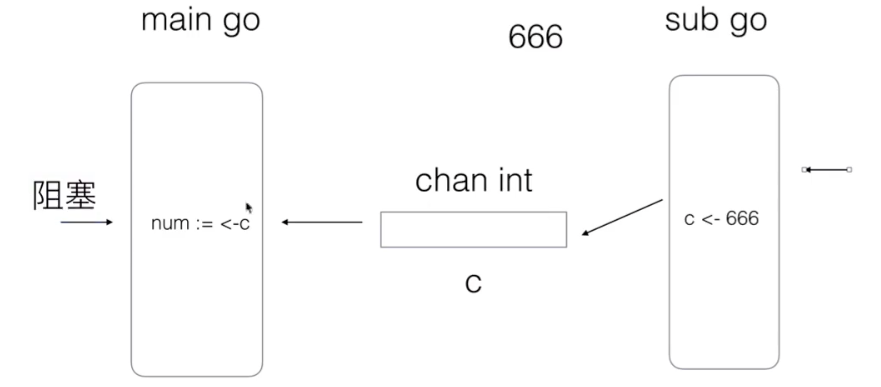
- 如果 sub goroutine 运行的快,也会进入等待,等待 main routine 运行到当前,然后再发送数据
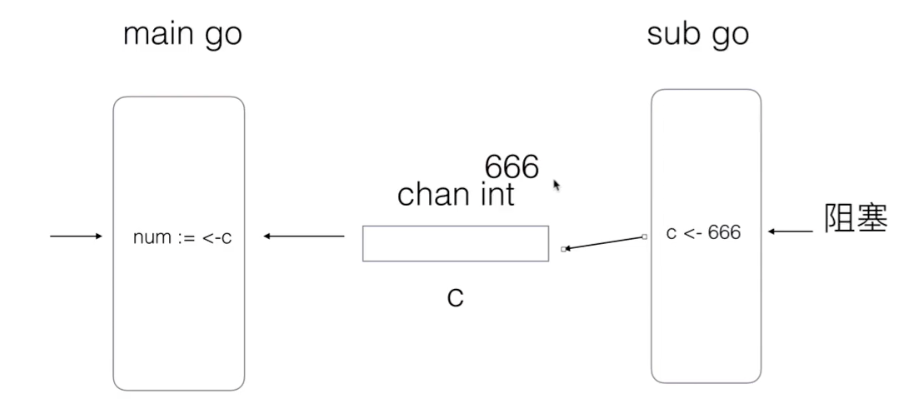
无缓冲的 channel
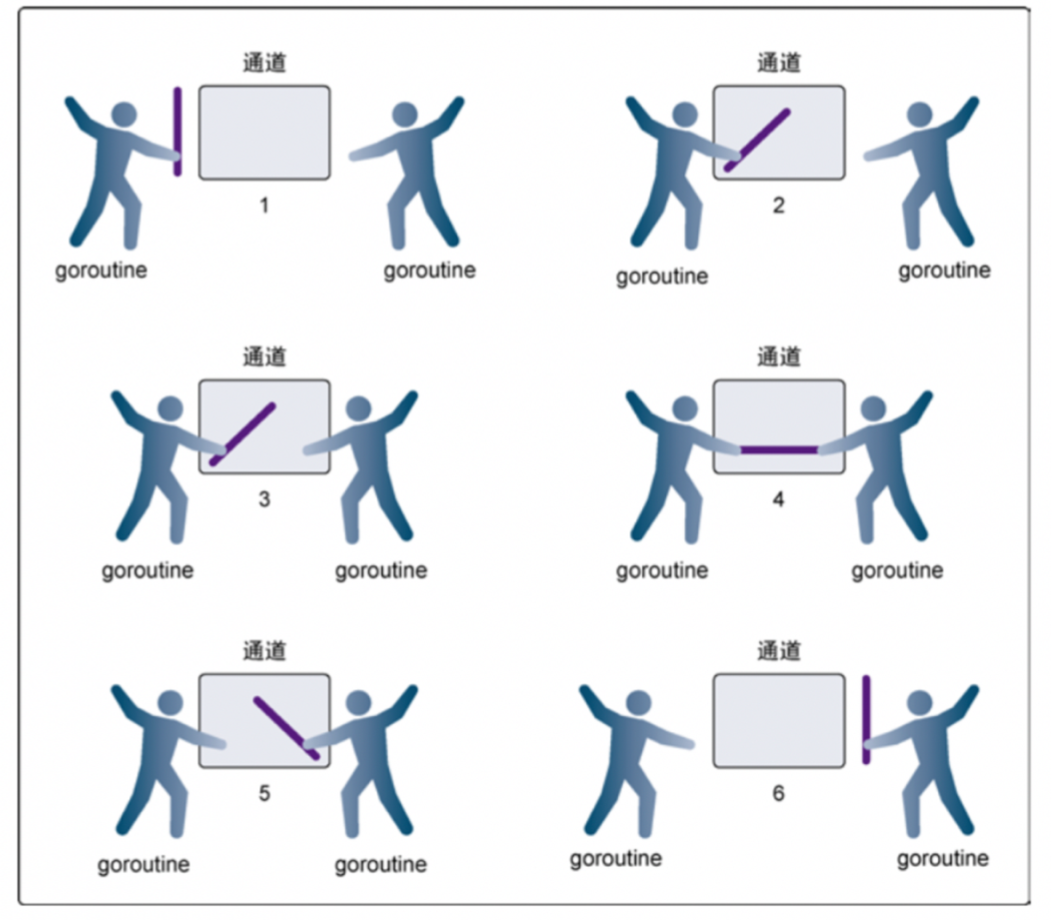
-
第 1 步,两个 goroutine 都到达通道,但哪个都没有开始执⾏发送或者接收。
-
第 2 步,左侧的 goroutine 将它的⼿伸进了通道,这模拟了向通道发送数据的⾏为。
这时,这个 goroutine 会在通道中被锁住,直到交换完成。
-
第 3 步,右侧的 goroutine 将它的手放⼊通道,这模拟了从通道⾥接收数据。
这个 goroutine ⼀样也会在通道中被锁住,直到交换完成。
-
第 4 步和第 5 步,进⾏交换。
-
第 6 步,两个 goroutine 都将它们的手从通道里拿出来,这模拟了被锁住的 goroutine 得到释放。
两个 goroutine 现在都可以去做其他事情了。
有缓冲的 channel
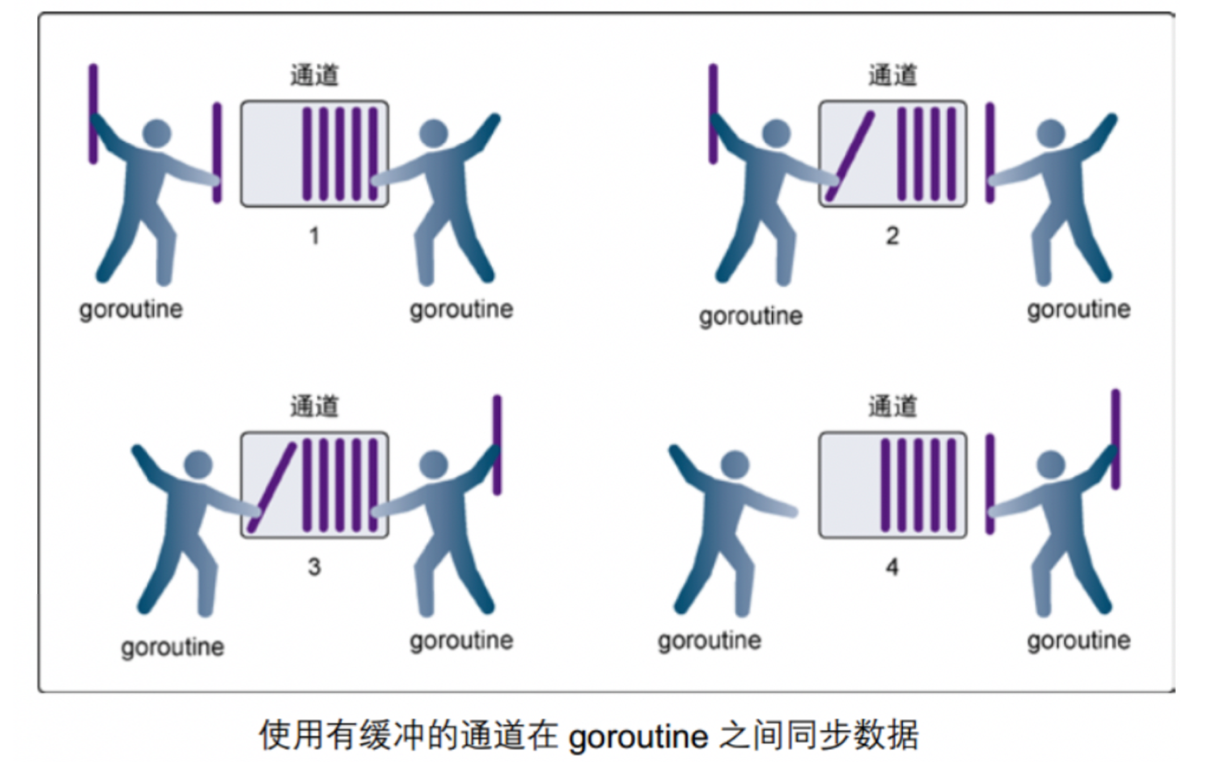
-
第 1 步,右侧的 goroutine 正在从通道接收一个值。
-
第 2 步,右侧的这个 goroutine 独立完成了接收值的动作,左侧的 goroutine 正在发送一个新值到通道里。
-
第 3 步,左侧的 goroutine 还在向通道发送新值,⽽右侧的 goroutine 正在从通道接收另外一个值。
这个步骤⾥的两个操作既不是同步的,也不会互相阻塞。
-
第 4 步,所有的发送和接收都完成,⽽通道里还有⼏个值,也有一些空间可以存更多的值。
特点:
- 当 channel 已经满,再向⾥面写数据,就会阻塞。
- 当 channel 为空,从⾥面取数据也会阻塞。
func main() {
c := make(chan int, 3)
fmt.Println("len(c) = ", len(c), "cap(c) = ", cap(c))
go func() {
defer fmt.Println("子go程结束")
for i := 0; i < 3; i++ {
c <- i
fmt.Println("子go程正在运行,发送的元素 =", i, "len(c) = ", len(c), " cap(c) = ", cap((c)))
}
}()
time.Sleep(2 * time.Second)
for i := 0; i < 3; i++ {
num := <-c
fmt.Println("num = ", num)
}
fmt.Println("main 结束")
}
len(c) = 0 cap(c) = 3 子go程正在运行,发送的元素 = 0 len(c) = 1 cap(c) = 3 子go程正在运行,发送的元素 = 1 len(c) = 2 cap(c) = 3 子go程正在运行,发送的元素 = 2 len(c) = 3 cap(c) = 3 子go程结束 num = 0 num = 1 num = 2 main 结束
上例中,可以尝试分别改变 2 个 for 的循环次数进行学习。
关闭 channel
func main() {
c := make(chan int)
go func() {
for i := 0; i < 5; i++ {
c <- i
}
close(c)
}()
for {
if data, ok := <-c; ok {
fmt.Println(data)
} else {
break
}
}
fmt.Println("Main Finished..")
}
0 1 2 3 4 Main Finished..
channel 不像文件一样需要经常去关闭,只有当确实没有任何发送数据了,或者想显式的结束 range 循环之类的,才去关闭 channel,注意:
- 关闭 channel 后,无法向 channel 再发送数据(引发 panic 错误后导致接收立即返回零值)
- 关闭 channel 后,可以继续从 channel 接收数据
- 对于 nil channel,⽆论收发都会被阻塞
channel 与 range
func main() {
c := make(chan int)
go func() {
defer close(c)
for i := 0; i < 5; i++ {
c <- i
}
}()
for data := range c {
fmt.Println(data)
}
fmt.Println("Main Finished..")
}
channel 与 select
select 可以用来监控多路 channel 的状态:
func fibonacii(c, quit chan int) {
x, y := 1, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 6; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacii(c, quit)
}
1 1 2 3 5 8 quit
本文来自博客园,作者:游走De提莫,转载请注明原文链接:https://www.cnblogs.com/Gaimo/p/16110153.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号