学习Java必备的前置知识!!!
一.数制
也称为 计数制或者计数系统 是一种计数方法 通过一组固定的符号和统一的规则来表示数值的方法,在计数过程中采用仅为的方法「进位计数制(进制)」,包括数位,基数和位权三个要素。
- 数位:指数字符号在一个数中所在的位置
- 基数:指在某种进位计数制中数位上能使用的数字符号的个数,如:十进制的基数是十
- 位权:数制中的某一位上所表示的数值大小(价值),规则:从右向左
汇编语言中常用的进制 分别是 二进制 八进制 和 十进制
二进制(Brinary)
二进制是以 遵循逢二进一为原则,由于计算机的硬件基础是基于电子元件的两种状态,即电平信号 高位(1) 和 低位(0),由于只有 0和1 因此二进制在计算机领域中是最基本的数制
优点:
- 技术上容易实现:二进制只使用0和1两个数字,非常适合电子设备的开关状态(如晶体管的导通和截止)。
- 可靠性高:由于只使用两个状态,传输和处理时不易出错,提高了计算机的可靠性。
- 运算规则简单:二进制数的运算规则比十进制简单,有利于简化运算器的结构,提高运算速度。
缺点:
- 可读性较差:二进制数与十进制数相比,很难被人类直接读取和理解。 这就使得人们在处理和调试二进制数据时需要花费更多的时间和精力。
- 长度较长:使用二进制表示大量数据时,往往需要使用更多的位数。 例如,表示数字 1000 需要使用十进制的四位数,但是在二进制中则需要至少十位二进制数才能表示。 这导致了数据在存储和传输时需要更多的存储空间和带宽。
- 精度有限:二进制数的精度受到计算机硬件的限制,只能表示一定范围内的数值。 例如,在单精度浮点数中,只能精确表示小数点后 7 位数字。
- 运算复杂:二进制数的运算比十进制数的运算更为复杂,需要使用更多的逻辑门和位运算。 例如,在二进制中实现加法和乘法需要使用逻辑门和移位运算,而十进制则可以直接使用加法器和乘法器。
转换规则
由于在计算机之中 最小的存储 单位就是 Byte 而1 byte = 8bit 正好对应了 1111 1111所以在二进制中每八个位进行一个分割(详细了解去看《计算机组成原理》这里就不深入了)
二进制转换成十进制:位权展开法
- 案例 :
十进制转换成二进制:除 2 取余法
- 案例:
得出的余数 从下向上排列 就得出了188 = 1011 1100
小技巧
对比上面的计算过程 我们发现一些取巧的计算方式
我们不妨直接将他二进制每一位与其相对应和的十进制数相对应 :

只要形成了肌肉记忆 不管是十进制转换成二进制还是二进制转十进制 都可以快速在脑中得出
原码、反码 与 补码
根据冯·诺依曼提出的经典计算机体系结构框架,一台计算机由运算器、控制器、存储器、输入和输出设备组成。其中运算器只有加法运算器,没有减法运算器。所以计算机中没办法直接做减法的,它的减法是通过加法实现的。现实世界中所有的减法也理解成加法的,减去一个数可以看作加上这个数的相反数,但前提是要先有负数的概念,这就是为什么不得不引入一个符号位。符号位在内存中存放的最左边一位,如果该位为0,则说明该数为正;若为1,则说明该数为负。
而且从硬件的角度上看,只有正数加负数才算减法,正数与正数相加,负数与负数相加,其实都是通过加法器直接相加。
原码、反码、补码的产生过程就是为了解决计算机做减法和引入符号位的问题。
(1)无符号数
非负整数,机器的字长的全部位数均用来表示数值大小
(2)带符号数
符号位(机器数): 一组二进制数的最高位 用来表示符号位 "0"为正 "1"为负
原码
规则: 符号位+绝对值(+ 0 ,- 1)
范围 :-127 ~ +127
举个例子:
原码: 123 和 -3
转换成二进制:
反码
规则:
正数:反码=原码
负数:反码=符号位+绝对值各位取反
反码的反码 == 原码
范围 :-127 ~ +127
举个例子:
原码: 123 和 -3
转换成二进制反码:
补码
规则:
正数:补码=原码
负数:补码=反码+1
补码的补码 == 原码
两数的补码之和 == 两数和的补码
范围:-128 ~ +127
举个例子:
原码: 123 和 -3
我们来验证一下 -3 的补码是否正确对其再次取补码:
反码 (符号位 + 绝对值各位取反)+1
偏移码
也叫移码是一种机器数的表示方法。它主要用于表示浮点数的阶码,
八进制(octal)
一种以8为基数的计数法,采用0,1,2,3,4,5,6,7。这八个数字,逢八进1。一些编程语言中常常以数字0开始表明该数字是八进制。八进制的数和二进制数可以按位对应(八进制一位对应二进制三位)
优点
- 转换方便:三位二进制数可以方便地转换为一位八进制数,反之亦然,这在处理二进制数据时非常有用。
- 易于解析:八进制数在字符串解析和转换方面比二进制更直观,比十进制计算简便。
缺点
应用局限性:虽然转换方便,但在日常生活中不如十进制直观,且应用场景相对较少。
转换规则
图示(转十进制):

十进制(decimal)
以10 为基数
十进制计数法是日常使用最多的计数方法,每相邻的两个计数单位之间的进率都为十的计数法则,就是十进制计数法
优点:
- 直观易读:十进制数符合人类的日常计数习惯,易于理解和记忆。
- 应用广泛:在日常生活和科学计算中广泛使用。
缺点:
- 对于计算机来说计算复杂:计算机内部采用二进制进行计算,十进制数需要转换后才能处理。
转换规则
十六进制 (Hexadechimal)
基数是16
有十六种数字符号,除了在十进制中的0至9外,还另外用6个英文字母A、B、C、D、E、F来表示十进制数的10至15,一些编程语言中 以0x 开始表面该数是16进制
优点:
- 表达紧凑:一位十六进制数可以表示四位二进制数,因此在表示计算机中的数据时更为紧凑。
- 易于转换:十六进制与二进制之间的转换非常方便,四位二进制数恰好对应一位十六进制数。
- 便于阅读:对于人类来说,十六进制数比二进制数更易于阅读和书写。
缺点:
- 对于非专业人士来说可能不太直观:虽然比二进制易读,但对于不熟悉的人来说可能不如十进制直观。、
运算规则(转十进制)

一些二进制的转换
1. 二进制 转 八进制
每三个 二进制 从右向左分一组 不足时 补零

2. 二进制 转 十六进制
每四个 二进制 从左向右分一组 不足时 补零
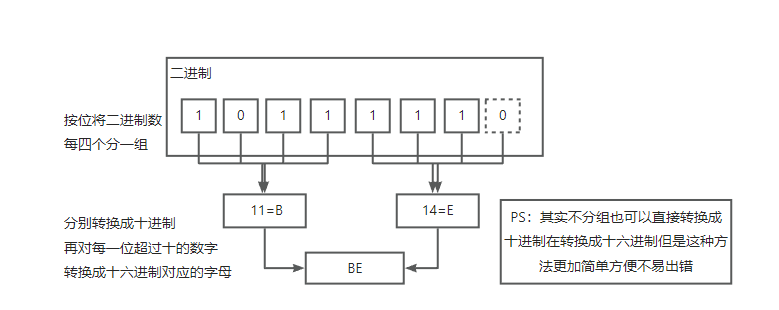
3. 八进制 转 十六进制
方式
八进制 → 二进制 → 十六进制
二.存储单位
计算机的存储单位 一般用
bit; Byte; KB; MB; GB; TB; PB; EB; ZB; BB; YB......
-
1B(Byte 字节)=8bit
-
1KB (Kilobyte 千字节)=1024B,
-
1MB (Megabyte 兆字节 简称“兆”)=1024KB,
-
1GB (Gigabyte 吉字节 又称“千兆”)=1024MB,
-
1TB (Trillionbyte 万亿字节 太字节)=1024GB
-
1PB(Petabyte 千万亿字节 拍字节)=1024TB,
-
1EB(Exabyte 百亿亿字节 艾字节)=1024PB,
-
1ZB (Zettabyte 十万亿亿字节 泽字节)= 1024 EB,
-
1YB (Yottabyte 一亿亿亿字节 尧字节)= 1024 ZB,
-
1BB (Brontobyte 一千亿亿亿字节)= 1024 YB.
三.基本数据类型
整数类型
- byte 字节型 8个 bit 就是一个字节 范围-128 ~ +127
- short 短整型 16 个bit , 也就是 两个字节 范围 -32768 ~ +32768
- int 整形 32 个bit 也就是四个字节 最常用的整形: -214483648 ~ +2147483647
- long 长整型 64个bit 也就是8个字节 范围: -9223372036854775808 ~ +9223372036854775807
浮点类型
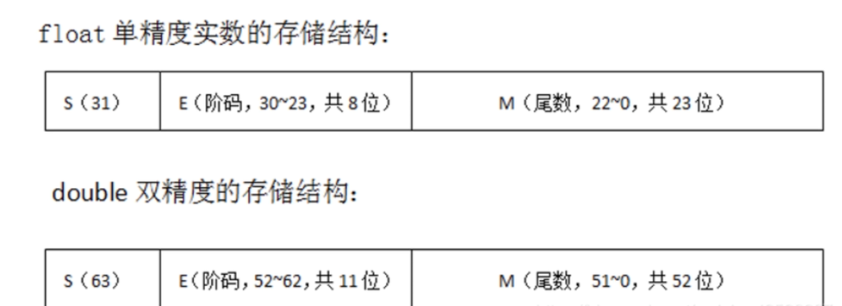
- float 单精度浮点数类型 (32bit,4字节)
- double 双精度浮点数类型 (64bit,8字节)
![]()
字符类型
- char 字符型(16个bit,也就是2字节,它不带符号)范围是0 ~ 65535
char类型依然存储的是数字,实际上每个数字在计算机中都会对应一个字符,ASCII码:
若要将 A 要展示出来,那就是一个字符的形式,而其对应的ASCII码值为65,所以说当char为65时,打印出来的结果就是大写的字母A:

或者也可以直接写一个字符常量值赋值:

布尔类型
布尔类型是编程中的一个比较特殊的类型,它并不是存放数字的,而是状态,它有下面的两个状态:
- true - 真
- false - 假
布尔类型(boolean)只有true和false两种值,也就是要么为真,要么为假,布尔类型的变量通常用作流程控制判断语
一些细节
隐式类型转换
小的数据类型 可以将数据 传递给大的数据类型
public static void main(String[] args) {
short a = 10;
int b = a; //小的类型可以直接传递给表示范围更大的类型
System.out.println(b);
}
这里由于问哦将小的整数类型传递给大的整数类型是时发生了隐式类型转换,只要是存储范围小的类型存储到大的范围类型 都支持隐式类型转换,它可以自动将某种类型的值,转换为另一种类型
隐式类型转换不仅可以发生在整数类型之间,也是可以在基本数据类型之间。
实际上我们在为变量赋值一个常量数值时,也发生了隐式类型转换
public static void main(String[] args){
byte b = 10 ;
}
强制类型转换(显式)
- 特点:代码需要进行特殊格式处理,不能自动完成。
- 格式:范围小的类型, 范围小的变量名 = (范围小的类型)原本范围大的数据
- ">强制类型转换一般不推荐使用,因为有可能发生精度损失、数据溢出。
- byte/short/char这三种类型都可以发生数学运算,例如“+”
- byte/short/char这三种类型在运算的时候,会被首先提升为int类型,再计算
- boolean类型不能发生数据类型转换
数值的一些细节
由于直接编写的正数都默认为int 当定义 long 的时候需要注意一下
按照long类型的规定,实际上是可以表示这么大的数字的,这里会报错,是因为直接在代码中写的常量数字,默认情况下是int类型,如果需要将其表示为一个long类型的常量数字,那么需要在后面添加大写或是小写的L

针对很长的数字, 为了提高辨识度我们可以使用下划线来分割每一位

我们也可以以八进制或者十六进制表示一个常量值

再看 这个问题

这里 a 的值 已经到达了int 可以表示的最大值了
2147483647 = 01111111 11111111 11111111 11111111
如果此时再加上 1 那么会在 结果就是 二进制位 进一位
会变成 10000000 00000000 00000000 00000000
按照 此时 变成了一个负数 那么 按照负数的补码规则 就变成了 -2147483648 int 类型的最小值
四.字符集
字符编码时 和解码使用的字符集 必须要一致否则会报错
标准ASCll 字符集
全称为 (American Standard CodeforInformation Interchange)
漂亮国 信息交换标准代码,包括了英文,符号等,
标砖的ASCll 使用一个字节存储一个字符,符号位是0,总共可以表示128个字符,基本上涵盖了漂亮国 的所需要的所有字符

GBK 字符集
全称为 《汉字内码扩展规范》(Chinese Internal Code Specification)
中文码 分为 内码 和 交换码 其中 GB2312 和GBK 都是 交换码 而Big5 是内码
汉字 占 3 个字节 英文数字占1 个字节
GBK编码
于1995年12月1日制定 。在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,符号位为1,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,图形符号 883 个,完全兼容GB2312-80标准,
汉字编码字符集,包含了2万多个汉字等字符,GBK中每个中文字符会被编码成两个字节的形式存储

(图片来源: 百度)
既然 提到GBK 就不得不提一下 GB2312 和Big5:
GB2312
GB2312是 1981年5月1日 开始实施的一套国家标准 信息交换用汉字编码字符集 共收录了6763个汉字和非汉字符号682个。
GB2312中对所收汉字进行了“分区”处理,首先构造一个94行94列的方阵,对每一行称为一个“区”,每一列称为一个“位”。每区含有94个汉字/符号。这种表示方式也称为区位码。
01-09区为特殊符号。
16-55区为一级汉字,按拼音排序。
56-87区为二级汉字,按部首/笔画排序。
10-15区及88-94区则未有编码。
举例来说,“啊”字是GB2312之中的第一个汉字,它的区位码就是1601。
Big5
Big5 又称为大五码 或 五大码,是使用繁体中文的社区中最常用的电脑汉字字符集标准 共收录了12060个汉字
Big5 曾经在台湾 香港 和澳门的使用繁体中文的地区大方光彩 一度成为业界标准 其中倚天中文系统 和 Windows的繁体中文版的主要系统字符集都是以Big5为基准 。但长期以来并非当地的国家/地区标准或官方标准
直到 2003 年 Big5 被收录到了 CNS11643 中文标准交换码的附录中 从而获得了较为正式的地位,这个最新版本称为Big5-2003。
Big5码是一套双字节字符集,使用了双八码存储方法,以两个字节来安放一个字。第一个字节称为“高位字节”,第二个字节称为“低位字节”。在Big5的分区中:
| 0x8140-0xA0FE | 保留给用户自定义字符(造字区) |
|---|---|
| 0xA140-0xA3BF | 标点符号、希腊字母及特殊符号,包括在0xA259-0xA261,安放了九个计量用汉字:兙兛兞兝兡兣嗧瓩糎。 |
| 0xA3C0-0xA3FE | 保留。此区没有开放作造字区用。 |
| 0xA440-0xC67E | 常用汉字,先按笔划再按部首排序。 |
| 0xC6A1-0xC8FE | 保留给用户自定义字符(造字区) |
| 0xC940-0xF9D5 | 次常用汉字,亦是先按笔划再按部首排序。 |
| 0xF9D6-0xFEFE | 保留给用户自定义字符(造字区) |
冲码问题
因为低比特字符中包含了编程语言、shell、script等各种语言中字符串或命令常会用到的特殊字符
Big5码字符的首字节会与DOS代码页437的画线字符相冲而产生乱码。如果在字符串中有这些特殊的转义字符,会被程序或解释器解释为特殊用途。但是因为是中文的原因,故无法正确解释为上面所述的行为,因此程序可能会忽略此转义符号或是中断运行。若此,就违反了用户本来要当成中文字符一部分使用的本意。
Unicode字符集
即 统一码 也被称为 万国码
UTF-8,是 (Universal Character Set/Unicode Transformation Format)的缩写,意为Unicode转换格式。
UTF-8(8位元,Universal Character Set/Unicode Transformation Format)是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与相容,使得原来处理ASCII字符的软件无需或只进行少部分修改后,便可继续使用。因此,它逐渐成为诸多应用中,优先采用的编码。
汉字 占 3 个字节 英文数字占1 个字节
UTF-8
UTF-16
UTF-32
运算符
| 类别 | 操作符 | 关联性 |
|---|---|---|
| 后缀 | () [] . (点操作符) | 左到右 |
| 一元 | expr++ expr-- | 从左到右 |
| 一元 | ++expr --expr + - ~ ! | 从右到左 |
| 乘性 | * /% | 左到右 |
| 加性 | + - | 左到右 |
| 移位 | >> >>> << | 左到右 |
| 关系 | > >= < <= | 左到右 |
| 相等 | == != | 左到右 |
| 按位与 | & | 左到右 |
| 按位异或 | ^ | 左到右 |
| 按位或 | ||
| 逻辑与 | && | 左到右 |
| 逻辑或 | ||
| 条件 | ?: | 从右到左 |
| 赋值 | = + = - = * = / =%= >> = << =&= ^ = | = |
| 逗号 | , | 左到右 |
赋值运算符
赋值运算符的左边必须是一个可以赋值的目标,比如变量,右边可以是任意满足要求的值,包括变量
当出现连续使用赋值运算符时,按照从右往左的顺序进行计算,所以,使用连等可以将一连串变量都赋值为最右边的值。
| 操作符 | 描述 | 例子 |
|---|---|---|
| = | 最简单的赋值运算符, | C = A + B将把A + B得到的值赋给C |
| += | 加和赋值操作符,它把左操作数和右操作数相加赋值给左操作数 | C + = A等价于C = C + A |
| -+ | 减和赋值操作符,它把左操作数和右操作数相减赋值给左操作数 | C - = A等价于C = C - A |
| *= | 乘和赋值操作符,它把左操作数和右操作数相乘赋值给左操作数 | C * = A等价于C = C * A |
| /= | 除和赋值操作符,它把左操作数和右操作数相除赋值给左操作数 | C / = A,C 与 A 同类型时等价于 C = C / A |
| %= | 取模和赋值操作符,它把左操作数和右操作数取模后赋值给左操作数 | C%= A等价于C = C%A |
| <<= | 左移位赋值运算符 | C << = 2等价于C = C << 2 |
| >>= | 右移位赋值运算符 | C >> = 2等价于C = C >> 2 |
| &= | 按位与赋值运算符 | C&= 2等价于C = C&2 |
| ^= | 按位异或赋值操作符 | C ^ = 2等价于C = C ^ 2 |
| != | 按位或赋值操作符 | C |
算数运算符
算术运算符也就是我们初等数学中认识的这些运算符,包括加减乘除,当然Java还支持取模运算,算术运算同样需要左右两边都有一个拿来计算的目标。
ps : 不同类型的变量(数值)在参与算术运算的时候 会发生隐式类型转换,所以说最后的到的结果也一定是转换后的类型

小数和整数一起计算同样会发生隐式类型转换

因为小数表示范围更广,所以说整数会被转换为小数再进行计算,而最后的结果也肯定是小数了。
我们也可以将加减号作为正负符号使用,比如我们现在需要让a变成自己的相反数:
public static void main(String[] args) {
int a = 10;
a = -a; //减号此时作为负号运算符在使用,会将右边紧跟的目标变成相反数
System.out.println(a); //这里就会得到-10了
}
加法支持对字符串的拼接,字符串不仅可以跟字符串拼接,也可以跟基本数据类型拼接:
public static void main(String[] args) {
String str = "蔡徐坤" + true + 2.5 + 'Kun';
System.out.println(str);
}
条件运算符
条件运算符也被称为三元运算符。该运算符有3个操作数,并且需要判断布尔表达式的值。该运算符的主要是决定哪个值应该赋值给变量。
判断语句 ? 结果1 : 结果2
位运算符
Java定义了位运算符,应用于整数类型(int),长整型(long),短整型(short),字符型(char),和字节型(byte)等类型。位运算符作用在所有的位上,并且按位运算。
| 操作符 | 描述 | 例子 |
|---|---|---|
| & | 如果相对应位都是1,则结果为1,否则为0 | (5&3),二进制位 相比较得到 0000 0001 |
| | | 如果相对应位都是 0,则结果为 0,否则为 1 | (5 |
| ^ | 如果相对应位值相同,则结果为0,否则为1 | (5 ^ 3)得到 0000 0110 |
| 〜 | 按位取反运算符翻转操作数的每一位,即0变成1,1变成0。 | (〜5)得到 1111 1010 |
| << | 按位左移运算符。左操作数按位左移右操作数指定的位数。 | 5 << 2 得到 0001 0100 |
| >> | 按位右移运算符。左操作数按位右移右操作数指定的位数。 | 5 >> 2得到 0000 0001 |
| >>> <<< |
无符号左移运算符。无符号的意思是将符号位当作数字位看待。即无论值的正负,都在高位补0. | 255>>>2 得到 0111 1111 255<<<2得到 1111 1000 |
逻辑运算符
| 操作符 | 描述 | 例子 |
|---|---|---|
| && | 逻辑与运算符,当两个操作数都为真,条件才为真 | (A |
| || | 逻辑或操作符。如果任何两个操作数任何一个为真,条件为真 | (A |
| ! | 成为逻辑非运算符。用来反转操作数的逻辑状态。如果条件为true,则逻辑非运算符将得到false。 | !(A&&B) 为真 |
流程控制
条件语句
IF
如果布尔表达式的值为 true,则执行 if 语句中的代码块,否则执行 else 语句块后面的代码。
if(布尔表达式)
{
//如果布尔表达式为true将执行的语句
}
IF else
if 语句后面可以跟 else 语句,当 if 语句的布尔表达式值为 false 时,else 语句块会被执行。
if(布尔表达式){
//如果布尔表达式的值为true
}else{
//如果布尔表达式的值为false
}
else IF
if 语句后面可以跟 else if…else 语句,这种语句可以检测到多种可能的情况。
使用 if,else if,else 语句的时候,需要注意下面几点:
- if 语句至多有 1 个 else 语句,else 语句在所有的 else if 语句之后。
- if 语句可以有若干个 else if 语句,它们必须在 else 语句之前。
- 一旦其中一个 else if 语句检测为 true,其他的 else if 以及 else 语句都将跳过执行。
if(布尔表达式 1){
//如果布尔表达式 1的值为true执行代码
}else if(布尔表达式 2){
//如果布尔表达式 2的值为true执行代码
}else {
//如果以上布尔表达式都不为true执行代码
}
嵌套
if(布尔表达式 1){
////如果布尔表达式 1的值为true执行代码
if(布尔表达式 2){
////如果布尔表达式 2的值为true执行代码
}
}
switch case
sswitch 是条件 选择判断语句 ,通过判断一个变量和分支的值是否相等 。
switch(expression){
case value :
//语句
break; //可选
case value :
//语句
break; //可选
//你可以有任意数量的case语句
default : //可选
//语句
}
switch case 语句有如下规则:
- switch 语句中的变量类型可以是: byte、short、int 或者 char。从 Java SE 7 开始,switch 支持字符串 String 类型了,同时 case 标签必须为字符串常量或字面量。
- switch 语句可以拥有多个 case 语句。每个 case 后面跟一个要比较的值和冒号。
- case 语句中的值的数据类型必须与变量的数据类型相同,而且只能是常量或者字面常量。
- 当变量的值与 case 语句的值相等时,那么 case 语句之后的语句开始执行,直到 break 语句出现才会跳出 switch 语句。
- 当遇到 break 语句时,switch 语句终止。程序跳转到 switch 语句后面的语句执行。case 语句不必须要包含 break 语句。如果没有 break 语句出现,程序会继续执行下一条 case 语句,直到出现 break 语句。
- switch 语句可以包含一个 default 分支,该分支一般是 switch 语句的最后一个分支(可以在任何位置,但建议在最后一个)。default 在没有 case 语句的值和变量值相等的时候执行。default 分支不需要 break 语句。
switch case 执行时,一定会先进行匹配,匹配成功返回当前 case 的值,再根据是否有 break,判断是否继续输出,或是跳出判断。
public class Test {
public static void main(String args[]){
//char grade = args[0].charAt(0);
char grade = 'C';
switch(grade)
{
case 'A' :
System.out.println("优秀");
break;
case 'B' :
case 'C' :
System.out.println("良好");
break;
case 'D' :
System.out.println("及格");
break;
case 'F' :
System.out.println("你需要再努力努力");
break;
default :
System.out.println("未知等级");
}
System.out.println("你的等级是 " + grade);
}
}
//结果 为 良好 你的等级是C
如果 case 语句块中没有 break 语句时,JVM 并不会顺序输出每一个 case 对应的返回值,而是继续匹配,匹配不成功则返回默认 case。
public class Test {
public static void main(String args[]){
int i = 5;
switch(i){
case 0:
System.out.println("0");
case 1:
System.out.println("1");
case 2:
System.out.println("2");
default:
System.out.println("default");
}
}
}
//结果是 default
循环结构
switch case 语句判断一个变量与一系列值中某个值是否相等,每个值称为一个分支
for 循环
for(初始化; 布尔表达式; 更新) {
//代码语句
}
关于 for 循环有以下几点说明:
- 最先执行初始化步骤。可以声明一种类型,但可初始化一个或多个循环控制变量,也可以是空语句。
- 接下来,检测布尔表达式的值。如果为 true,循环体被执行。如果为false,循环终止,开始执行循环体后面的语句。
- 执行一次循环后,更新循环控制变量。
- 再次检测布尔表达式。循环执行上面的过程。
while 循环
while( 布尔表达式 ) { //只要布尔表达式为 true,循环就会一直执行下去。
//循环内容
}
do while 循环
对于 while 语句而言,如果不满足条件,则不能进入循环。但有时候我们需要即使不满足条件,也至少执行一次。
do…while 循环和 while 循环相似,不同的是,do…while 循环至少会执行一次。
do {
//代码语句
}while(布尔表达式);
布尔表达式在循环体的后面,所以语句块在检测布尔表达式之前已经执行了。 如果布尔表达式的值为 true,则语句块一直执行,直到布尔表达式的值为 false。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号