
理解爬虫原理
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2881
一. 简单说明爬虫原理
爬虫即是从网络中爬取数据,就python为例,利用requests模块访问网址,将访问后返回的html保存下来,并利用bs4进行分析,将想要的数据保存下来。
二. 理解爬虫开发过程
1.简要说明浏览器工作原理
从用户键入网址回车确认后,浏览器向服务器发送http请求,服务器接收到请求后相应的业务逻辑处理,并返回数据,浏览器接收到数据后,便开始解析返回来的数据,并生成DOM模型,渲染界面。
2.使用 requests 库抓取网站数据
运行代码:
res=requests.get("http://news.gzcc.cn/html/xibusudi/") res.encoding='utf-8' print(res.text)
运行效果:

3.了解网页
运行代码:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>作业一</title>
<stytle>
.content{
width:100%
}
</stytle>
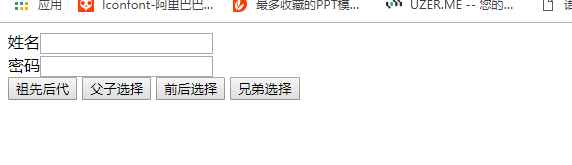
</head> <body> <form> <div id="name" class='content'><label>姓名</label><input type="text"></div> <div id="password" class='content'><label>密码</label><input type="text"></div> </form> <button>祖先后代</button> <button>父子选择</button> <button>前后选择</button> <button>兄弟选择</button> </body> </html>
运行效果:
4.使用 Beautiful Soup 解析网页
运行代码:
res=requests.get("http://localhost:9999/jquery.html") res.encoding='utf-8' soup=bs4.BeautifulSoup(res.text,'html.parser') print('含有特定标签(button)的元素:{}'.format(soup.button)) print('含有特定类名(button)的元素:{}'.format(soup.select(".content"))) print('含有特定id(name)的元素:{}'.format(soup.select("#name")))
运行效果:

三.提取一篇校园新闻的标题、发布时间、发布单位、作者、点击次数、内容等信息
运行代码:
res=requests.get("http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0328/11086.html") res.encoding='utf-8' soup=bs4.BeautifulSoup(res.text,'html.parser') title=soup.select(".show-title")[0] print("标题:") print(title.text) infos=soup.select(".show-info")[0].text.split() datestr=infos[0]+' '+infos[1] date=datetime.strptime(datestr,'发布时间:%Y-%m-%d %H:%M:%S') print("时间:") print(date) print(infos[3]) print(infos[4]) print(infos[5]) countHtml=requests.get("http://oa.gzcc.cn/api.php?op=count&id=11086&modelid=80") count=int(re.findall("\d+",count.text.split(".html")[-1])[0]) print("点击次数:{}".format(count)) content=soup.select("#content")[0] print("内容:") print(content.text.strip())
运行效果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号