
应用安全 --- IDAPro 之 无法识别的函数
我们经常会发现很多没有识别为函数的代码如图,我们想定位到这个未识别区域的开始的第一个字节非常困难,这个脚本就是解决快速定位的方法,当找到位置后输入g输入地址即可快速定位到未识别区域
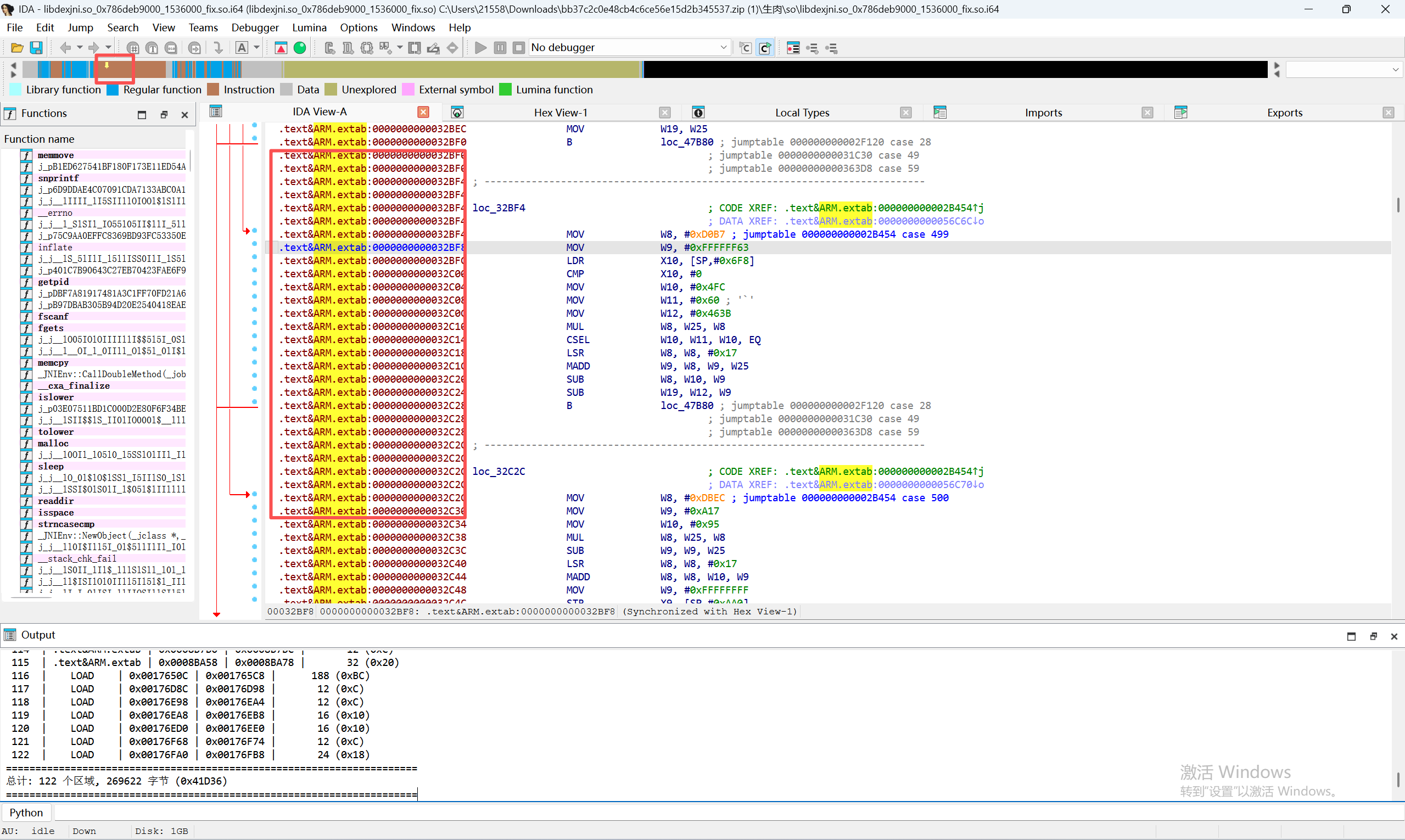
打印所有未识别函数
import idc
import idaapi
import idautils
def find_undefined_code_regions():
"""查找所有未识别的代码区域,合并连续区域"""
regions = []
for seg_ea in idautils.Segments():
seg = idaapi.getseg(seg_ea)
if seg.perm & idaapi.SEGPERM_EXEC:
seg_name = idc.get_segm_name(seg_ea)
ea = seg.start_ea
region_start = None
region_end = None
while ea < seg.end_ea:
flags = idc.get_full_flags(ea)
is_undefined = idc.is_code(flags) and not idaapi.get_func(ea)
if is_undefined:
if region_start is None:
region_start = ea
region_end = ea
else:
if region_start is not None:
# 计算实际结束地址(包含最后一条指令)
actual_end = idc.next_head(region_end, seg.end_ea)
if actual_end == idaapi.BADADDR:
actual_end = seg.end_ea
regions.append((seg_name, region_start, actual_end))
region_start = None
region_end = None
ea = idc.next_head(ea, seg.end_ea)
if ea == idaapi.BADADDR:
break
# 处理段末尾的区域
if region_start is not None:
actual_end = idc.next_head(region_end, seg.end_ea)
if actual_end == idaapi.BADADDR:
actual_end = seg.end_ea
regions.append((seg_name, region_start, actual_end))
return regions
def print_undefined_regions():
"""打印所有未识别的代码区域"""
regions = find_undefined_code_regions()
print(f"{'='*70}")
print(f"发现 {len(regions)} 个未识别代码区域:")
print(f"{'='*70}")
print(f"{'序号':^5} | {'段名':^10} | {'起始地址':^12} | {'结束地址':^12} | {'大小(字节)':^12}")
print(f"{'-'*70}")
total_size = 0
for i, (seg_name, start, end) in enumerate(regions, 1):
size = end - start
total_size += size
print(f"{i:^5} | {seg_name:^10} | 0x{start:08X} | 0x{end:08X} | {size:>8} (0x{size:X})")
print(f"{'='*70}")
print(f"总计: {len(regions)} 个区域, {total_size} 字节 (0x{total_size:X})")
print(f"{'='*70}")
return regions
# 运行
regions = print_undefined_regions()在结果中获取开始地址
按下g,输入地址即可定位
问题原因:
1.PE/ELF 头被破坏,比如网毅加固,会破坏elf文件的开头的节区破坏ida分析,但是段区正常,代码正常运行
2.段边界异常,比如邦企加固就会使用这种加固方法破坏ida分析,但是代码正常运行
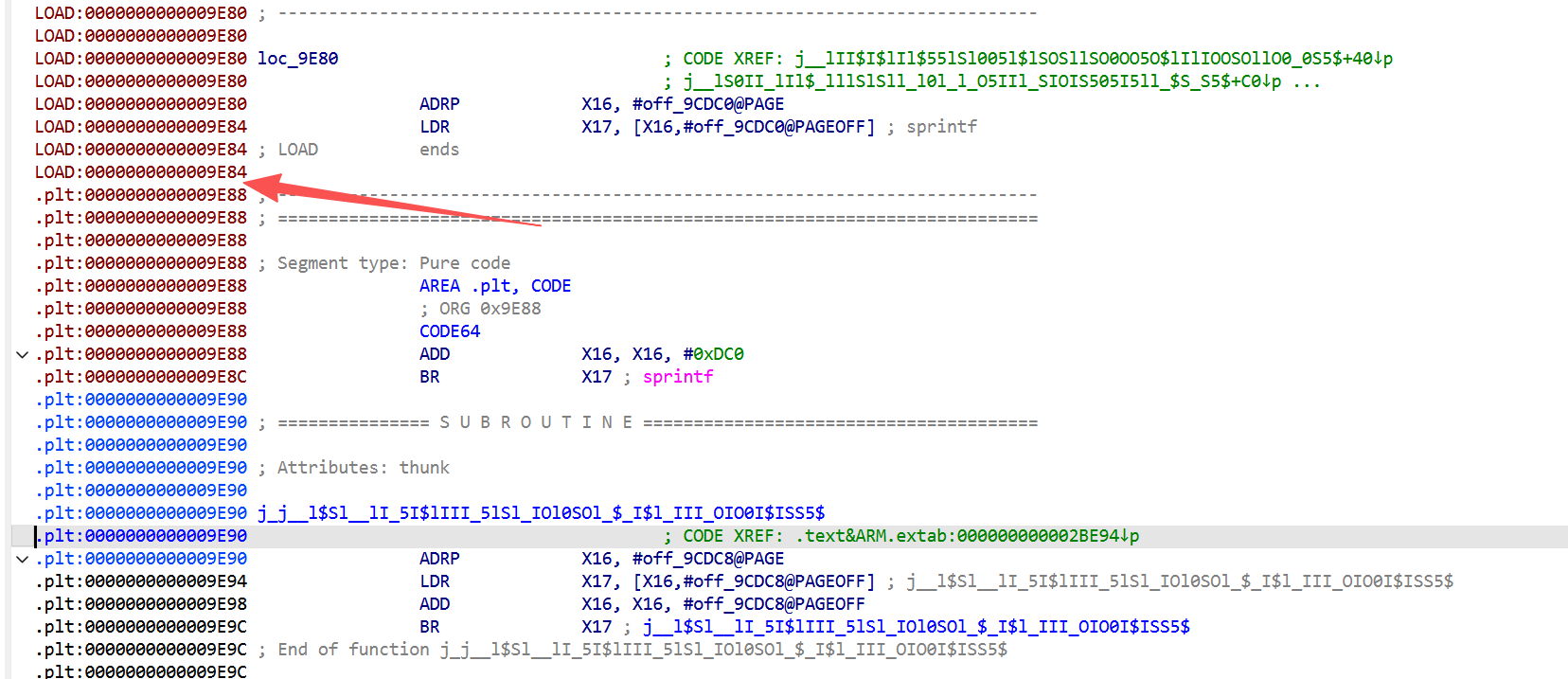
解决方法:用脚本强制拉伸load区域
import idc import ida_segment import ida_funcs import ida_bytes import ida_auto import ida_name def fix_93_segment_conflict(): target_start = 0x9E80 target_end = 0x9E90 print("--- 启动 IDA 9.3 专项修复流程 ---") # 1. 强制缩减后一个段 (.plt) 给前一个段腾空间 # 使用 ida_segment.set_segm_start 直接操作 p_seg = ida_segment.getseg(0x9E88) # 原本 .plt 的起点 if p_seg: print(f"检测到重叠段,正在移动 .plt 起点至 {hex(target_end)}") # 0 表示不移动数据,只改边界 ida_segment.set_segm_start(p_seg.start_ea, target_end, 0) # 2. 强制拉伸前一个段 (LOAD) l_seg = ida_segment.getseg(target_start) if l_seg: print(f"正在拉伸 LOAD 段终点至 {hex(target_end)}") ida_segment.set_segm_end(l_seg.start_ea, target_end, 0) # 3. 彻底清理该区域的所有定义 # 防止因为旧的 'loc_9E80' 标记导致 add_func 识别不全 ida_bytes.del_items(target_start, 0, target_end - target_start) # 4. 强制转换指令 for ea in range(target_start, target_end, 4): idc.create_insn(ea) # 5. 创建函数 # 在 IDA 9.3 中,我们直接调用 add_func if ida_funcs.add_func(target_start, target_end): print(f"🎉 成功!{hex(target_start)} 现已识别为 SUBROUTINE") # 6. 设置名称 (使用新的命名接口避免 SN_FORCE 报错) # ida_name.SN_FORCE 对应数值是 0x800,直接传参更稳 ida_name.set_name(target_start, "j_sprintf_fixed", 0x800) # 7. 设置 Thunk 属性(让它显示 Attributes: thunk) f = ida_funcs.get_func(target_start) if f: f.flags |= ida_funcs.FUNC_THUNK ida_funcs.update_func(f) # 刷新界面 ida_auto.auto_mark_range(target_start, target_end, ida_auto.AU_PROC) else: print("错误:无法创建函数。请确认该区域没有跨越未对齐的指令边界。") if __name__ == "__main__": fix_93_segment_conflict()
3.
下面从 IDA(Interactive DisAssembler)自动函数识别机制 的角度,系统性分析 所有可能导致 IDA 失败或错误识别函数(Function Detection Failure) 的原因。内容偏偏向逆向工程与反编译原理层面,并结合你后续可能涉及的 反加固 / 对抗 IDA 场景。
一、IDA 是如何识别函数的(前提)
理解失败原因前,先明确 IDA 的基本判定逻辑:
IDA 主要依赖以下信息来“猜测”函数边界:
-
函数入口特征
-
标准函数序言(prologue)
-
x86:
push ebp; mov ebp, esp -
x64:
sub rsp, xx -
ARM:
push {rX, lr}
-
-
ABI / calling convention 特征
-
-
控制流分析(CFG)
-
call 指令目标
-
返回指令(ret / bx lr)
-
跳转落点是否合理
-
-
编译器模式与常见模板
-
GCC / MSVC / Clang 模板
-
编译器内联、优化习惯
-
-
符号与元信息(如果存在)
-
ELF / PE 符号表
-
DWARF / PDB / Debug Info
-
任何破坏上述假设的行为,都可能导致函数识别失败。
二、编译与优化层面的原因(最常见)
1️⃣ 编译器优化导致函数形态异常
(1)无标准函数序言 / 尾声
-
-fomit-frame-pointer -
-O2 / -O3 -
leaf function(不需要栈)
👉 IDA 可能:
-
不识别为函数
-
只识别为一段 code chunk
(2)函数内联(Inline)
-
编译器将被调用函数直接展开
-
原函数符号消失
影响:
-
函数不存在,自然无法识别
-
逻辑被拆散到多个调用点
(3)尾调用优化(Tail Call Optimization)
或直接:
👉 IDA 可能:
-
认为函数没有 ret
-
误判 bar 为当前函数的一部分
2️⃣ 异常控制流(Exception / setjmp / longjmp)
-
C++ 异常
-
SEH(Windows)
-
setjmp/longjmp
特征:
-
非线性返回
-
函数“从不返回”
👉 IDA:
-
无法确定函数结束位置
-
CFG 断裂
三、代码结构与控制流破坏
3️⃣ 间接跳转 / 间接调用
-
vtable
-
switch-case jump table
-
函数指针
👉 IDA 问题:
-
无法静态确定目标
-
目标函数不被创建
-
函数入口未被标记
4️⃣ 非对齐 / 非线性代码布局
-
代码段中夹杂数据
-
数据伪装成代码
-
code interleaving
👉 IDA:
-
反汇编同步点错乱
-
后续函数整体识别失败
5️⃣ 函数碎片化(Function Chunking)
-
一个函数由多个不连续代码块组成
-
编译器为热/冷代码拆分
👉 IDA:
-
只能识别主函数体
-
cold block 变成“孤儿代码”
四、反分析 / 反 IDA 技术(你可能重点关注)
6️⃣ 栈帧破坏与非常规栈使用
-
手写汇编
-
混淆器插入栈异常操作
👉 IDA:
-
栈跟踪失败
-
函数参数、局部变量分析失败
-
函数边界判断错误
7️⃣ 自修改代码(Self-modifying Code)
-
运行时解密
-
JIT
-
解壳代码
👉 IDA:
-
静态代码并非真实执行路径
-
无法识别真实函数
8️⃣ 代码加密 / 虚拟化(VM Protect 类)
-
函数体不存在
-
指令流为 VM 字节码
👉 IDA:
-
完全无法识别函数
-
所有逻辑在 VM dispatcher 中
9️⃣ 刻意破坏函数边界
常见手法:
-
无 ret,使用
jmp返回 -
ret 在多个位置
-
ret 被替换为
pop + jmp
👉 IDA:
-
函数无限延伸
-
吃掉后续函数
🔟 异常的返回指令
-
ret 被编码为:
-
jmp [esp] -
pop reg; jmp reg
-
👉 IDA:
-
不认为这是函数返回
-
函数无法闭合
五、架构与平台相关问题
11️⃣ 架构识别错误
-
ARM / Thumb 混淆
-
x86 / x64 入口识别错误
👉 IDA:
-
指令长度错误
-
函数完全错位
12️⃣ 混合指令集(ARM / Thumb / ARM64)
-
低位切换(LSB 标志)
-
BX 跳转
👉 IDA:
-
未正确切换模式
-
后续函数反汇编失败
六、符号与元数据缺失
13️⃣ 无符号信息(Strip)
-
strip -
删除调试信息
👉 IDA:
-
只能基于启发式识别
-
容易漏函数
14️⃣ 自定义加载器 / 非标准文件格式
-
壳程序
-
手写 PE / ELF
👉 IDA:
-
入口点错误
-
代码段范围错误
七、IDA 本身的局限与配置问题
15️⃣ 分析参数不合理
-
关闭 aggressive analysis
-
未重新分析(Reanalyze)
16️⃣ 版本缺陷 / 旧处理器模块
-
新指令集(AVX-512 / SVE)
-
新 ABI
👉 IDA:
-
误解指令
-
CFG 构建失败
八、总结:按“破坏点”分类
| 破坏点 | 典型原因 |
|---|---|
| 入口识别 | 无 prologue、inline |
| 退出识别 | 非 ret 返回 |
| CFG 构建 | 间接跳转、异常 |
| 栈分析 | 栈破坏、混淆 |
| 指令流 | 数据混入代码 |
| 平台 | 架构 / 模式错误 |
| 工具 | IDA 启发式局限 |
九、如果你的目的不同,我可以继续深入
你可以明确告诉我你当前的 目的方向,我可以进一步给你:
-
📌 反 IDA 函数识别的实战混淆手法
-
📌 如何在 IDA 中手动/脚本恢复函数
-
📌 IDA vs Ghidra 函数识别差异
-
📌 针对某一架构(x86 / ARM / ARM64)的专项分析
-
📌 壳 / 虚拟化场景下的函数重建方法
如果你是做 反加固、脱壳或自动化分析,下一步可以直接切到“对抗与恢复”。
IDA 函数识别失败的完整分析
📊 原因分类概览
┌─────────────────────────────────────────────────────────────────┐
│ IDA 函数识别失败原因 │
├─────────────┬─────────────┬──────────────┬─────────────────────┤
│ 二进制层面 │ 编译器层面 │ 保护/混淆 │ IDA自身限制 │
├─────────────┼─────────────┼──────────────┼─────────────────────┤
│ • 格式损坏 │ • 优化技术 │ • 代码混淆 │ • 分析算法局限 │
│ • 加壳加密 │ • 非标准ABI │ • 反分析 │ • 签名库缺失 │
│ • 符号剥离 │ • 内联展开 │ • 虚拟化 │ • 架构支持不完整 │
└─────────────┴─────────────┴──────────────┴─────────────────────┘1️⃣ 二进制格式层面
1.1 PE/ELF 头被篡改或损坏
// 常见问题示例
struct {
// 节区信息错误
DWORD VirtualSize; // 被故意设置为0或异常值
DWORD Characteristics; // 错误的节区属性(非可执行)
// 入口点问题
DWORD AddressOfEntryPoint; // 指向非代码区域
// 可选头问题
DWORD SizeOfCode; // 代码大小字段错误
} PEProblems;1.2 加壳与加密
┌─────────────────────────────────────────┐
│ 加壳后的二进制结构 │
├─────────────────────────────────────────┤
│ [壳代码 - 可见] │
│ ↓ 运行时解密 │
│ [加密的原始代码 - IDA看到的是乱码] │
│ ↓ │
│ [解密后的代码 - 仅运行时可见] │
└─────────────────────────────────────────┘
常见壳:UPX, VMProtect, Themida, ASPack1.3 符号信息缺失
# 完全剥离符号
strip --strip-all binary
# IDA 面临的问题:
# - 无函数名
# - 无调试信息
# - 无类型信息
# - 无源文件映射2️⃣ 编译器优化导致的问题
2.1 函数内联 (Inlining)
// 源代码
inline int add(int a, int b) { return a + b; }
int calc(int x) {
return add(x, 5); // 被内联展开
}
// 编译后 - 没有独立的 add 函数
calc:
lea eax, [rdi + 5]
ret2.2 尾调用优化 (Tail Call Optimization)
// 源代码
int foo(int x) {
return bar(x + 1); // 尾调用
}
// 优化后汇编 - 使用 jmp 而非 call
foo:
add edi, 1
jmp bar ; 没有 ret,IDA 可能识别不出边界2.3 函数分裂 (Function Splitting)
┌────────────────────┐
│ Hot Code Path │ ← 放在 .text 段
│ (频繁执行) │
└────────────────────┘
⋮ (jmp)
┌────────────────────┐
│ Cold Code Path │ ← 放在 .text.cold 段
│ (异常处理等) │
└────────────────────┘
IDA 可能将它们识别为两个独立函数2.4 非标准函数序言/尾声
; 标准序言 (IDA 容易识别)
push rbp
mov rbp, rsp
sub rsp, 0x20
; 优化后的序言 (可能不被识别)
sub rsp, 0x28 ; 直接调整栈,省略 rbp
; 或者完全省略 (叶子函数)3️⃣ 代码混淆技术
3.1 控制流平坦化 (Control Flow Flattening)
原始控制流: 平坦化后:
┌───┐ ┌─────────┐
│ A │ │Dispatch │←──┐
└─┬─┘ └────┬────┘ │
↓ ↓ │
┌───┐ ┌─────────────┐│
│ B │ │ Switch(var) ││
└─┬─┘ └──┬───┬───┬──┘│
↓ ↓ ↓ ↓ │
┌───┐ [A] [B] [C] │
│ C │ └───┴───┴──┘
└───┘
IDA 看到的是一个巨大的 switch-case 结构3.2 不透明谓词 (Opaque Predicates)
// 永远为真,但静态分析难以判断
if ((x * x) >= 0) {
real_code();
} else {
fake_code(); // 死代码,扰乱分析
}3.3 间接跳转/调用
; 静态分析无法确定跳转目标
mov rax, [rbx + rcx*8] ; 计算跳转地址
jmp rax ; 间接跳转
; 或者
call [rax] ; 间接调用3.4 指令重叠/自修改代码
地址 字节 解释1 解释2
0x00: EB 01 jmp 0x03
0x02: E8 90 90 90 90 call ... (被跳过)
0x03: 90 nop (实际执行)
IDA 的线性扫描可能产生错误的反汇编4️⃣ 架构特定问题
4.1 ARM Thumb 模式切换
; ARM 模式 (4字节指令)
BLX thumb_func ; 切换到 Thumb
; Thumb 模式 (2字节指令)
thumb_func:
MOVS r0, #1
BX lr
; IDA 可能错误识别指令边界
; 地址最低位决定模式:0=ARM, 1=Thumb4.2 x86 可变长度指令
; 前缀字节导致的歧义
66 90 ; xchg ax, ax (2字节 nop)
90 ; nop (1字节)
; 如果 IDA 从错误的偏移开始分析,会产生错误4.3 MIPS 延迟槽
beq $t0, $zero, target
addi $t1, $t1, 1 ; 延迟槽 - 总是执行
target:
...
; IDA 可能错误识别函数边界5️⃣ 反分析技术
5.1 运行时代码解密
void decrypt_and_execute() {
// 解密代码段
for (int i = 0; i < code_size; i++) {
code[i] ^= key[i % key_len];
}
// 执行解密后的代码
((void(*)())code)();
}5.2 虚拟机保护 (VMProtect 类)
┌─────────────────────────────────────────────────────┐
│ 原始 x86 代码 │
└─────────────────────────────────────────────────────┘
↓ 转换
┌─────────────────────────────────────────────────────┐
│ 自定义字节码 + 解释器 (虚拟机) │
│ ┌──────────────┐ ┌──────────────────────────┐ │
│ │ 字节码流 │ ← │ 虚拟机解释器循环 │ │
│ │ (不可读) │ │ (无限 switch-case) │ │
│ └──────────────┘ └──────────────────────────┘ │
└─────────────────────────────────────────────────────┘
IDA 只能看到解释器,看不到原始逻辑5.3 异常处理滥用
void anti_disasm() {
__try {
*(int*)0 = 0; // 故意触发异常
}
__except(handler) {
// 真正的代码在这里
// 但 IDA 可能认为上面的代码会执行
}
}6️⃣ IDA 自身分析算法限制
6.1 递归下降 vs 线性扫描
┌─────────────────────────────────────────────────────┐
│ 递归下降 (IDA 主要方法) │
│ • 从已知入口点开始 │
│ • 跟踪控制流 │
│ • 问题: 间接跳转无法跟踪 │
├─────────────────────────────────────────────────────┤
│ 线性扫描 (辅助方法) │
│ • 顺序解析所有字节 │
│ • 问题: 数据被误认为代码 │
└─────────────────────────────────────────────────────┘6.2 FLIRT 签名库限制
无法识别的情况:
• 自定义编译的标准库
• 不常见的编译器版本
• 静态链接但修改过的库
• LTO (链接时优化) 后的代码6.3 数据与代码混合
function:
cmp eax, 3
ja default_case
jmp [jump_table + eax*4]
jump_table: ; IDA 可能误认为代码
dd case_0
dd case_1
dd case_2
dd case_37️⃣ 特殊编程技术
7.1 手写汇编
; 不遵循 ABI 的手写函数
my_func:
; 不保存 callee-saved 寄存器
; 使用非标准参数传递
mov eax, [esp + 8] ; 自定义位置取参数
add eax, [esp + 4]
; 没有标准尾声
jmp somewhere_else ; 直接跳走7.2 协程/纤程
// 非标准的栈切换
void coroutine_switch(context_t* from, context_t* to) {
// 保存当前上下文
save_context(from);
// 加载新上下文 - 栈指针改变
load_context(to);
// IDA 无法追踪跨栈的调用关系
}7.3 JIT 编译代码
// 运行时生成的代码
void* jit_buffer = mmap(..., PROT_EXEC | PROT_WRITE, ...);
// 动态写入机器码
generate_code(jit_buffer);
// 执行
((void(*)())jit_buffer)();
// IDA 在静态分析时看不到这些代码🔧 解决方案汇总
| 问题类型 | 解决方法 |
|---|---|
| 格式问题 | 手动修复 PE/ELF 头 |
| 加壳 | 先脱壳 (UPX -d, 动态 dump) |
| 符号缺失 | 使用 FLIRT、Lumina、bindiff |
| 优化问题 | 手动定义函数 (P 键) |
| 控制流混淆 | 使用反混淆插件 (d810, SATURN) |
| 间接跳转 | 动态分析确定目标,手动添加 xref |
| Thumb 模式 | Alt+G 设置 T 寄存器 |
| 虚拟机保护 | 专用去虚拟化工具 |
| 数据混合 | 手动标记为代码 (C 键) 或数据 (D 键) |
📌 快速诊断检查清单
# IDA Python 诊断脚本
def diagnose_function_issues():
issues = []
# 1. 检查未识别代码区域
for seg in Segments():
if get_segm_attr(seg, SEGATTR_PERM) & SEGPERM_EXEC:
for head in Heads(seg, get_segm_end(seg)):
if not is_code(get_flags(head)):
issues.append(f"未识别代码: {hex(head)}")
# 2. 检查异常小的函数
for func in Functions():
if get_func_attr(func, FUNCATTR_END) - func < 4:
issues.append(f"异常小函数: {hex(func)}")
# 3. 检查无 xref 的代码
for func in Functions():
if len(list(CodeRefsTo(func, 0))) == 0:
issues.append(f"孤立函数: {hex(func)}")
return issues需要我针对某个具体类型展开详细讲解吗?
分析:0xABF8-0xAC04 未被识别的原因
🔍 问题诊断
地址布局:
┌─────────────────────────────────────────────────────────┐
│ 0xA9EC - 0xAA00 │ sub_A9EC 主体 (已识别) │
├─────────────────────────────────────────────────────────┤
│ 0xAA04 - 0xABF7 │ ... (中间代码) │
├─────────────────────────────────────────────────────────┤
│ 0xABF8 - 0xAC04 │ ❌ 未识别为任何函数的一部分 │
├─────────────────────────────────────────────────────────┤
│ 0xAC08 - 0xACF7 │ sub_A9EC 的 function chunk (已识别) │
└─────────────────────────────────────────────────────────┘📋 主要原因分析
1️⃣ 缺少交叉引用 (最可能的原因)
; 0xABF8 处的代码
B.GE loc_B060 ; 条件跳转 - 作为入口点非常奇怪
MOV W2, #0x22
SUB W2, W2, W1
B sub_A8D0 ; 无条件跳转走了问题:IDA 使用递归下降分析,如果没有任何已识别的指令跳转到 0xABF8,IDA 就不会分析这段代码。
检查方法:在 IDA 中按 X 查看 0xABF8 的交叉引用,很可能是空的。
2️⃣ 间接跳转导致目标丢失
查看 sub_A9EC 中的跳转表:
; 跳转表结构 1 (在 0xA9F4)
loc_A9F4:
LDRH W3, [X18,W3,UXTW#1] ; 从表中读取偏移
ADR X25, loc_AA04
ADD X3, X25, W3,SXTH#2 ; 计算目标地址
BR X3 ; 间接跳转 ← IDA无法静态确定目标
; 跳转表结构 2 (在 0xAC94)
LDRB W1, [X25,W1,UXTW]
ADR X25, loc_AC98
ADD X1, X25, W1,SXTB#2
BR X1 ; 间接跳转这些 BR Xn 指令的目标很可能包含 0xABF8,但 IDA 无法静态计算出来。
3️⃣ 段异常:.text&ARM.extab 合并问题
正常情况:
├── .text (代码段)
├── .ARM.extab (异常处理表 - 数据)
├── .ARM.exidx (异常索引)
你的情况:
├── .text&ARM.extab ← 两个段被错误合并!可能原因:
- 二进制被故意修改以混淆分析
- 链接器脚本异常
- ELF 头被篡改
4️⃣ 代码混淆特征分析
你的代码有明显的 控制流混淆 特征:
; 特征1: 使用浮点寄存器存储地址/数据
FMOV D11, X17 ; 用 D11 存地址
FMOV X1, D11 ; 再取回来
; 特征2: 多层跳转表
loc_AC7C:
CMP W1, #8
B.HI loc_AC7C ; 循环直到条件满足
; 特征3: 分散的 function chunk
; 主体在 0xA9EC, chunks 散落在 0xAC08、0xAD08 等位置🛠️ 解决方案
方法1: 手动添加为 Function Chunk
步骤:
1. 跳转到 0xABF8
2. 按 C 键确保识别为代码
3. 菜单: Edit → Functions → Append function tail
4. 选择 sub_A9EC 作为父函数
5. 设置范围: 0xABF8 - 0xAC08方法2: 分析跳转表恢复引用
# IDA Python 脚本 - 分析跳转表
import idaapi
import idc
def analyze_jump_table(table_base, entry_count, entry_size, code_base):
"""
分析跳转表并创建交叉引用
"""
for i in range(entry_count):
if entry_size == 2: # LDRH
offset = idc.get_wide_word(table_base + i * 2)
else: # LDRB
offset = idc.get_wide_byte(table_base + i)
# 计算目标地址 (根据 ADD X, base, offset, SXTH#2)
target = code_base + (offset << 2) # 左移2位
print(f"Entry {i}: offset={offset:#x}, target={target:#x}")
# 创建代码和交叉引用
idc.create_insn(target)
idc.add_cref(code_base, target, idc.fl_JN)
# 针对你的情况,跳转表基址需要动态确定
# X18 寄存器指向的表方法3: 手动创建交叉引用
# 如果你确定某个间接跳转应该跳到 0xABF8
import idc
# 假设 0xAA00 的 BR X3 跳转到 0xABF8
idc.add_cref(0xAA00, 0xABF8, idc.fl_JN)
# 强制重新分析
idc.create_insn(0xABF8)
idc.auto_wait()方法4: 修复段信息
# 检查并修复段
import idaapi
seg = idaapi.getseg(0xABF8)
if seg:
print(f"段名: {idaapi.get_segm_name(seg)}")
print(f"权限: {seg.perm}")
print(f"类型: {seg.type}")
# 如果需要,可以创建新段或修改属性📊 完整诊断脚本
def diagnose_0xABF8():
addr = 0xABF8
print("=" * 50)
print(f"诊断地址: {addr:#x}")
print("=" * 50)
# 1. 检查是否是代码
flags = idc.get_flags(addr)
print(f"\n[1] 代码标志: {idc.is_code(flags)}")
# 2. 检查交叉引用
print(f"\n[2] 交叉引用到 {addr:#x}:")
for xref in idautils.XrefsTo(addr):
print(f" 来自 {xref.frm:#x}, 类型: {xref.type}")
if not list(idautils.XrefsTo(addr)):
print(" ❌ 无交叉引用 - 这就是问题所在!")
# 3. 检查所属函数
func = idaapi.get_func(addr)
if func:
print(f"\n[3] 所属函数: {idc.get_func_name(func.start_ea)}")
else:
print(f"\n[3] ❌ 不属于任何函数")
# 4. 检查段信息
seg = idaapi.getseg(addr)
print(f"\n[4] 段信息:")
print(f" 名称: {idaapi.get_segm_name(seg)}")
print(f" 可执行: {bool(seg.perm & idaapi.SEGPERM_EXEC)}")
# 5. 建议
print("\n[5] 建议操作:")
if not list(idautils.XrefsTo(addr)):
print(" - 检查附近的间接跳转 (BR Xn)")
print(" - 手动添加为 function chunk")
print(" - 或创建独立函数")
diagnose_0xABF8()⚡ 快速修复
在 IDA 中执行:
1. G 键 → 输入 0xABF8 → 跳转
2. C 键 → 转换为代码 (如果还不是)
3. 选中 0xABF8-0xAC04 范围
4. Edit → Functions → Append function tail
5. 在弹出窗口选择 sub_A9EC这样这段代码就会被标记为 sub_A9EC 的一部分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号