散列
一.什么是散列
散列使用一个散列函数,将一个键映射到一个索引上。
散列非常高效。使用散列将耗费O(1)时间来查找、插入、及删除一个元素。
映射表是一种用散列实现的数据结构,映射表是一种存储条目的容器,每个条目包含两个部分:一个键(key)和一个值(value)。键又称为搜索键用于查找对应的值。
映射表(map)又称为字典(dictionary)、散列表(hash table)或者关联数组(associate array)。
Java合集框架定义了java.util.Map接口,三个具体的的实现为java.util.HashMap、java.util.linkedHashMap以及java.util.TreeMap。java.util.HashMap使用散列实现,java.util.linkedHashMap使用linkedList,java.util.TreeMap使用红黑树。
二.散列函数和散列码
1.散列函数
将键映射到散列表的索引上的函数称为散列函数(hash function)。理想的,将每个搜索的键映射到散列表中的不同索引上,这样的函数称为完美散列函数。然而,很难找到一个完美的散列函数,当两个或更多的键映射到一个散列值上的时候,我们称之为产生了一个冲突(collision)。
典型的散列函数首先将搜索键转换成为一个整数值,称之为散列码。然后将散列码压缩为散列表中的索引。
2.equals和hashCode
Java的根类Object具有hashCode方法,返回一个整数的散列码。默认的,该返回值是一个该对象的内存地址。hashCode一般有如下约定:
1)当equals方法被重写时,应该重写hashCode方法,以保证两个相等的对象返回同样的散列码。
2)程序执行中,如果对象的数据没有被修改,则多次调用hashCode将返回同样的整数。
3)两个不相等的对象可能具有同样的散列码,但是应该在实现hashCode方法时避免太多这样的情形出现。
3.基本数据类型的散列码
对于byte、short、int、char类型,简单讲它们转为int,这些类型中的任何一个不同的搜索键将有不同的散列吗。
对于float,使用Float.floatToIntBits(key)作为散列码,方法返回一个int值。该值得比特表示和浮点数f的比特表示相同。
对于long类型的搜索键,简单地转为int不是很好的选择,因为无法反应前面32高位的不同。考虑到这种情况,将64比特分为两部分,并执行异或操作将两部分结合,这个过程称为折叠(folding)。
一个long类型键的散列码为:
int hashCode=(int)(key^(key>>32));
对于double类型的搜索键,首先使用Double.doubleToLongBits方法转为long值,再执行折叠操作。
4.字符串类型的散列码
一个比较直观的方法是将所有字符的unicode求和作为字符串的散列码。这个方法可能有较大的冲突,也无法区分dog与dgo。
一个更好的方法是考虑字符的位置,然后产生散列码:
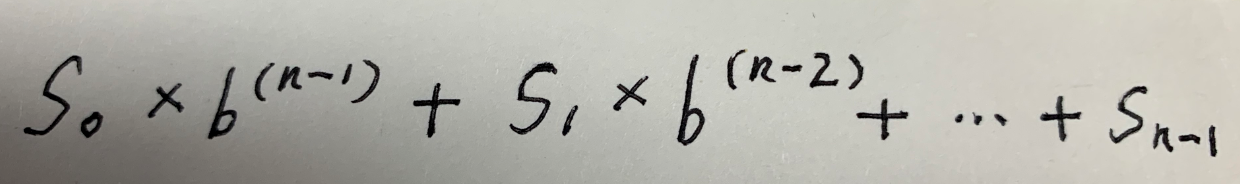
这里Si为s.charAt(i),这个方法被称为多项式散列码。计算时,对于长的字符串会导致溢出,但Java中会忽略溢出。要最小化冲突,关键是选择合适的b,实验显示,b较好的取值为31,33,37,39,41。
java.lang.String.java中的多项式散列实现:
/**
* Returns a hash code for this string. The hash code for a
* {@code String} object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
* </pre></blockquote>
* using {@code int} arithmetic, where {@code s[i]} is the
* <i>i</i>th character of the string, {@code n} is the length of
* the string, and {@code ^} indicates exponentiation.
* (The hash value of the empty string is zero.)
*
* @return a hash code value for this object.
*/
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
5.压缩散列码
键的散列码可能是一个很大的整数,超过了散列表索引的范围,因此需要将它缩小。假设散列表的索引处于0到N-1之间,常用的压缩做法是:
h(hashCode)=hashCode%N
保证索引均匀扩展,选择N大于2的素数。
上面的式子等价于:
h(hashCode)=hashCode&(N-1)
为保证散列是均匀分布的,java.util.HashMap的实现中采用了补充的散列函数与主散列函数一起使用:
private static int supplementalHash(int h){
h^=(h>>>20)^(h>>>12);
return h^(h>>>7)^(h>>>4);
}
完整的散列函数:
h(hashCode)= supplementalHash(hashCode)%N
这个式子与下面式子一样:
h(hashCode)= supplementalHash(hashCode) &(N-1)
三. 开放地址法
当两个键映射到散列表中的同一个索引,冲突发送,通常有2种方法处理冲突:开放地址法与链地址法。
开放地址法有以下几个变体。
1.线性探测
线性探测法在发生冲突时,按顺序找到下一个可用的位置。连续冲突时继续按序检查,直到找到可用位置。
当探测到表的终点时,则返回表的起点。因此,散列表被当成是循环的。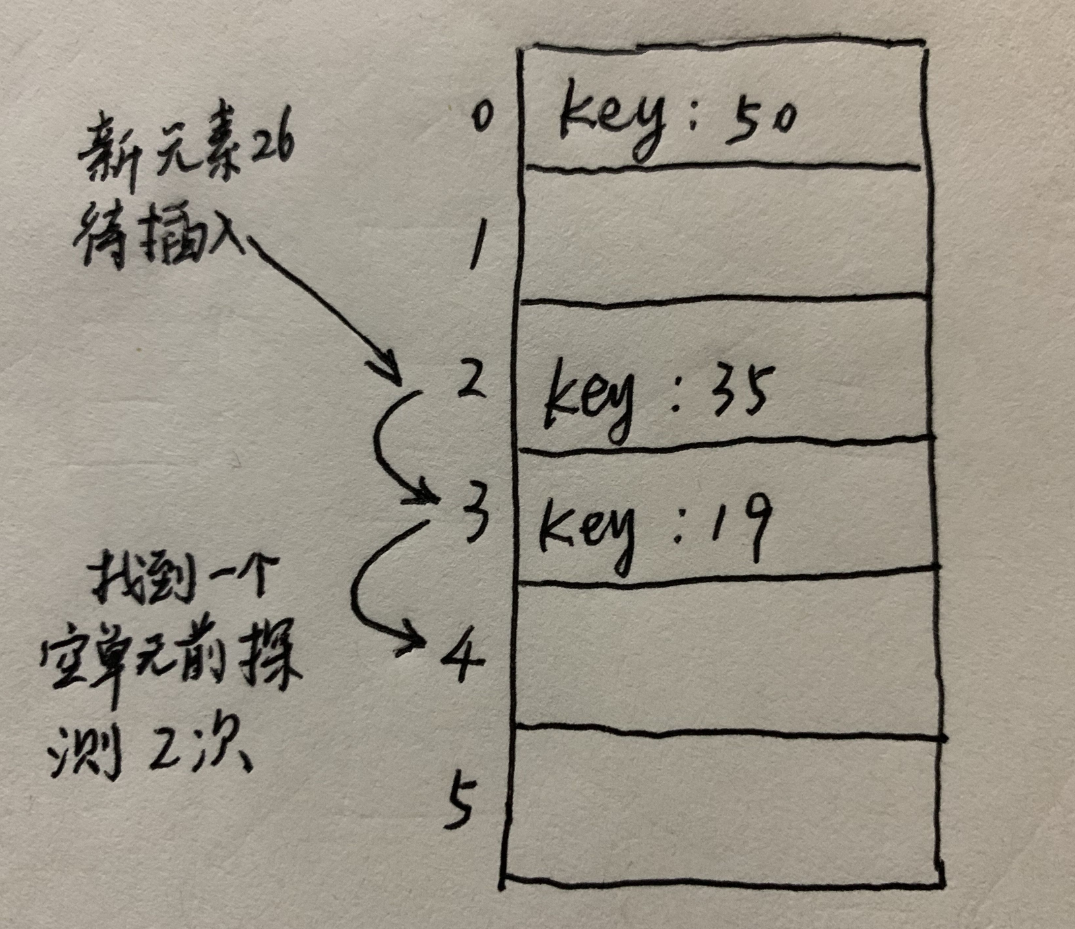
线性探测法容易导致散列表中连续的单元组被占用。这样的每个组称为一个簇(cluster)。
2.二次探测
线性探测法从索引k的位置检查连续单元,二次探测法则从索引为(k+j^2)%N位置开始检查,其中j>=0。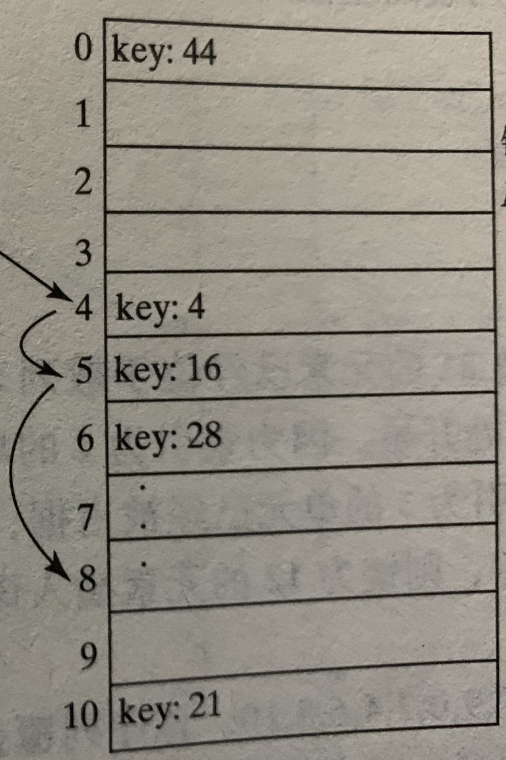
二次探测法避免了线性的成簇问题,但有自己本身的成簇问题,称为二次成簇,即产生冲突的条目将采用同样的探测序列。
3.再哈希法
避免成簇问题的另一个方法是再哈希法。
四. 链地址法
链地址法将具有相同的散列索引的条目都放在一个位置,每个位置使用一个桶来放置这些条目。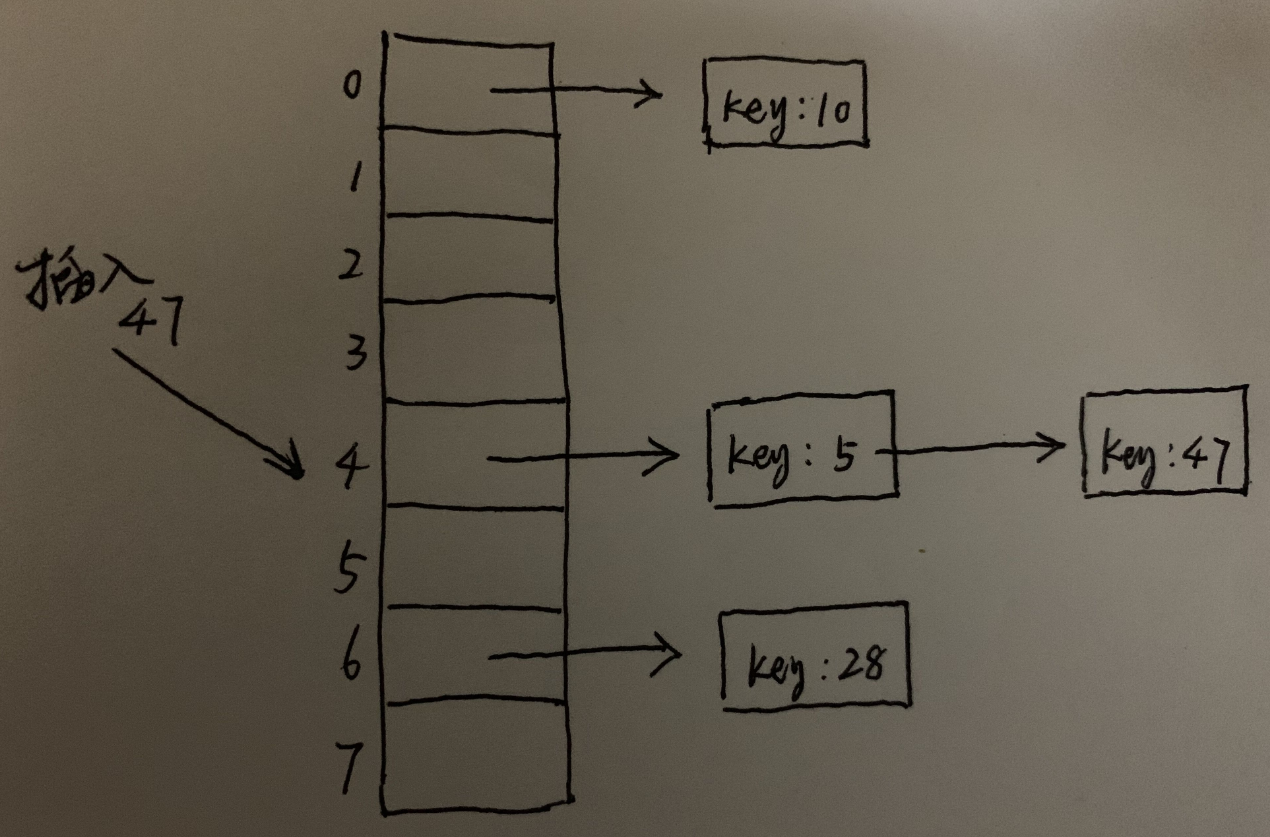
链地址法是种广泛使用的方法。
(在JDK中有不少基于此方法的实现,如jdk1.7的hasMap实现方案,在多线程环境中发生链循环等错误,jdk1.8中重写了链的处理,修正了此错误等故事。)
五. 装填因子和再散列
装填因子(load factor)衡量一个散列表有多满。如果装填因子超出,则增加散列表的大小,并重新装载条目到一个新的更大的散列表中,这称为再散列。
装填因子=条目数n/容量N,如果散列表满了,装填因子=1
当装填因子接近1时,冲突的可能性就增大。一般对于开发地址法,装填因子需要控制在0.5下,链地址法通常维持在0.9下。
在java.util.HashMap的实现中,采用了装填因子0.75的阈值。一旦超过阈值,就需要增加散列表的大小,并进行再散列。再散列的代价比较大,为避免频繁的再散列,一旦扩容时应该至少将散列表的大小翻倍。
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号