1 *****优先队列与集合****
2 **优先队列** priority_queue
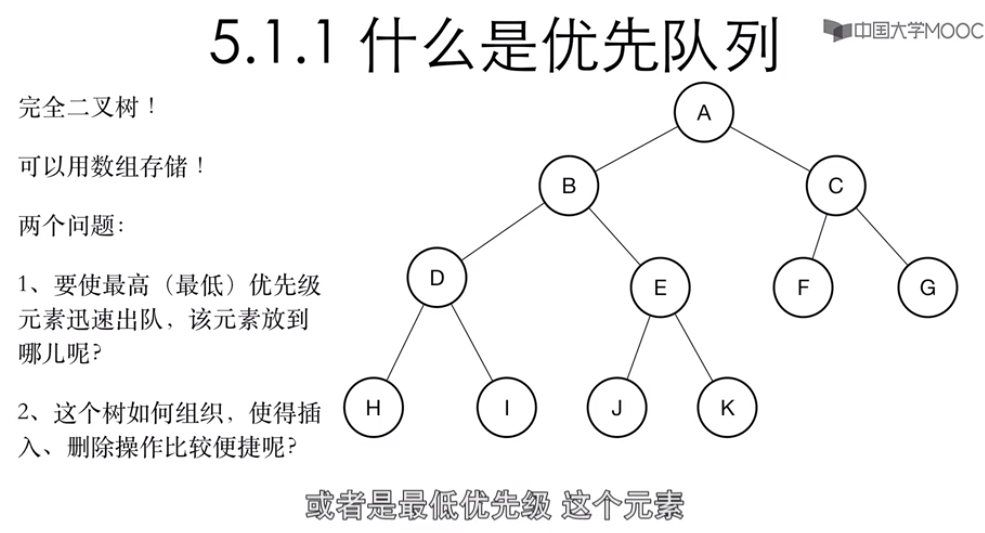
3 优先队列:对元素进行优先级的区分,入队没有要求,出对的时候按照优先级出队
4 数组、链表、二叉树、二叉搜索树 都可以做成优先队列。
5 但是他们各有各的优缺点,如图所示:
6 更好的实现方案?如图![]()
所示:![]()
![]()
7
8 课程地址:
9 https://www.icourse163.org/learn/QDU-1206503801?tid=1464154451#/learn/content?type=detail&id=1242523902&cid=1265642403&replay=true
10 *******代码实现*******
11 *******注意 下面实现的是小顶堆******
12 //2020.12.27 代码可能有注释不够清楚的地方,请参考青岛大学周强老师的《数据结构实战》,下次复习时候我再更新代码。#include<stdlib.h>
13 #include<cstdio>
14 #include<cstdlib>//引入free函数 销毁malloc申请的内存空间
15
16 typedef int Elem;
17
18 /*写在最前面:我们所学的是二叉堆(用完全二叉树(数组)储存)
19 但是我们还有二项堆、Fib堆,这两种堆就不是用完全二叉树实现的
20 二叉堆只是prorityqueue这个结构实现的一种方式,而不是说优先队列等同于二叉堆
21 priortiyqueue还能用二项堆、avl树、线段树还有二进制分组的vector实现
22 */
23 /*
24 堆的其他操作:
25 全部操作都首先要看这个堆是最大堆还是最小堆,细节上有些差异
26 1.提高元素优先级:提高优先级 + percolateup(因为提高优先级之后,这个位置不合适了,向上过滤)
27 2.降低元素优先级:降低优先级 + percolatedown(和提高优先级的的理由一致)
28 3.删除元素(不是堆顶的元素): 欲想让其灭亡,先让其膨胀,不是堆顶就提高它的优先级变成堆顶,那么我们的操作就变成了删除堆顶hh
29 */
30 struct heap{
31 //暂时用int代替Elem
32 //动态分配空间
33 Elem *data;
34 int capcity;
35 int size;
36 };
37
38 typedef struct heap* Heap;
39
40 Heap initHeap(int max){
41 Heap h;
42 h = (Heap)malloc(sizeof(struct heap));
43 //不够内存分配时候
44 if(h == 0) return NULL;
45 h->data = (Elem*)malloc(sizeof(Elem)*(max+1));
46 if(h->data == 0) return NULL;
47 h->size = 0;
48 return h;
49 //free自己写
50 }
51
52 void printHeap(Heap h){
53 //为了方便查找,0号位置不放东西
54 for(int i = 1; i <= h->size; i ++){
55 printf("%d ",h->data[i]);
56 }
57 putchar('\n');
58 }
59
60 bool isEmpty(Heap h){
61 return h->size == 0;
62 }
63 bool isFull(Heap h){
64 return h->capcity == h->size;
65 }
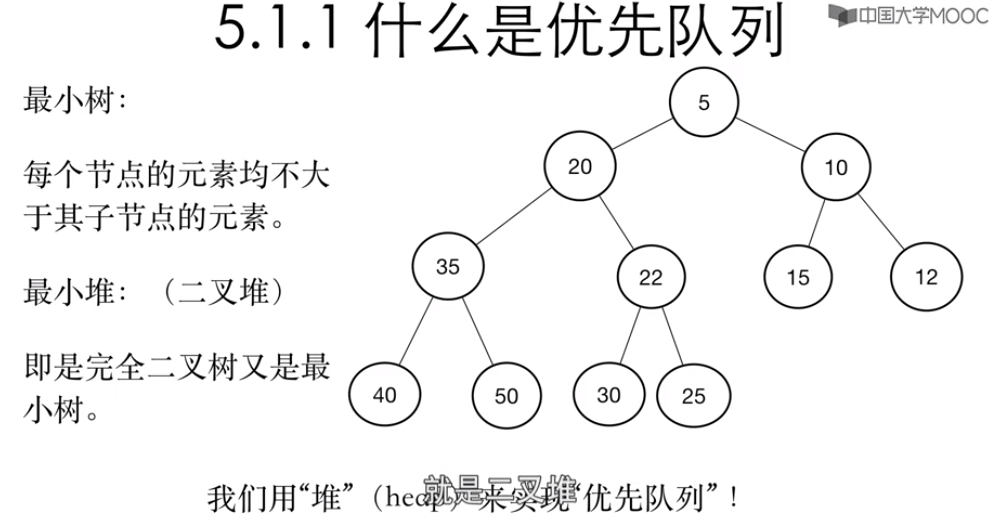
66
67 //建立小顶堆
68 //从位置k开始向上过滤
69 //向上渗透一直到堆顶为止,或者直至它的上一个元素不大于它为止
70 void percolateUp(int k, Heap h){
71 Elem x;
72 x = h->data[k];
73 //父子相比大小,最后如果到了树根,就没法再往上走了,不用再和父亲比了,父亲是0号位置
74 //当然与0号位置相比可以采取“哨兵”的做法,我们这个程序不采用这样的写法
75 //另外,i是要继续用的,所以不能定义为for的局部变量
76 //循环判断条件解释:=1时为树根,小于父亲节点时候进行交换
77 int i;
78 for(i = k; i > 1 && h->data[i] < h->data[i/2];i = i / 2){
79 //将小于x的父亲节点数据copy到这个位置
80 //我们不需要临时变量保存它,因为开头x就是临时变量
81 h->data[i] = h->data[i/2];
82 }
83 //出来循环有两种情况: i到了树根位置 or 父亲节点比x小
84 //pps:我们当前的堆以最小堆为样例
85 h->data[i] = x;
86 }
87 //因为可能会失败,用boolean作为返回值
88 //插入的元素,插入的位置
89 bool insertHeap(Elem x, Heap h){
90 if(isFull(h)) return false;
91 //size从0开始增长,可不就是++size的地方开始存放元素嘛
92 h->data[++h->size] = x;
93 percolateUp(h->size, h);
94 return true;
95 }
96
97 /*删除操作:堆顶元素为最大或者最小 所以删除显然是删除堆顶比较方便
98 本测试程序中以最小堆为示例,删除最小的元素
99 考虑堆是空的时候,抛出异常
100 */
101 /*如果是删除堆顶这个位置,会导致堆顶空了一个位置,接着堆顶这个空位会与它的
102 左儿子和右儿子进行交换,把这个空位给交换下去,导致一块地方给空了出来
103 最终会破坏掉整棵完全二叉树的结构
104 (二叉树的深度为k,除第 k 层外,其它各层 (1~k-1) 的结点数都达到最大个数,第k 层所有的结点都连续集中在最左边,这就是完全二叉树)
105 那么我们可以交换最后一个元素和堆顶元素的位置,这样删除的就是最后一个元素的位置
106 和堆顶的值,交换之后向下渗透就完事
107 */
108
109 //由于向上想下过滤并不一定只是适用于最后一个位置/最开始的位置 (比如堆排序.)
110 //所以我们在参数里面考虑用int k来指明位置
111 void percolateDown(int k, Heap h){
112 //向下渗透
113 Elem x;
114 x = h->data[k];
115 /*****/
116 printf("已经保存的临时变量为:%d,从x:%d开始过滤\n",h->data[k],h->data[k]);
117 printf("当前h:");
118 for(int i = 1; i <= h->size; i ++){
119 printf("%d ",h->data[i]);
120 }
121 putchar('\n');
122 /*****/
123 //用i获取位置
124 //循环终止条件:没有儿子当然要停下来啦,当你比下一步的儿子还小的时候当然也要停下来啦
125 //i需要用来查看停止位置即原先第k号元素应该放的新位置
126 //所以i必须是一个for外面的变量
127 int i,child;
128
129 //疑惑:i*2=h->size的时候,下面语句中child++也就是i*2+1不会越界???
130 //2021.7.25 听课不够认真。。。下面已经用child!=h->size限制了越界 不可能会发生越界的
131 for(i = k; i*2 <= h->size; i = child){
132 //为什么在for里面不直接像percolateUp那样同理赋值成一个特定的儿子?
133 //因为我们在(小顶堆)向下过滤的时候,我们要找的是小儿子进行替换,而不是有儿子就进行替换
134 //先看左儿子 在下标1 2 3 4...这样顺序的情况下,完全二叉树的i节点的左右儿子位置为i*2 i*2+1 父节点位置i/2
135 //需不需要写成移位加快速度?不论是i+i,还是i*2,现在编译器都会优化成i<<1 左移,所以i+i 和i*2都可以
136 child = i * 2;
137 //注意越界
138 //判断条件解释:child不是最后一个,左儿子大于右儿子
139 /*****/
140 printf("左儿子:%d,右儿子:%d\n",h->data[i*2],h->data[i*2+1]);
141 /*****/
142 //不能直接写h->data[child] < h->data[child + 1],因为可能会越界
143 //用child!=h->size就能判断child不是堆h的最后一个元素,只要不是最后一个元素,child++就不会越界
144 //最大child = h->size - 1的时候,child++刚好是最后一个元素
145 //pps:child 左儿子 child+1就是右儿子嘛
146 //这个判断语句帮忙找出左儿子和右儿子哪个比较小
147 if(child != h->size && h->data[child] > h->data[child+1]){
148 //更小的是右儿子
149 //否则就是维持默认的最小是左儿子,上面child的缺省值为i*2(左儿子)
150 child ++;
151 }
152 /****/
153 printf("当前比较小的是:%d\n",h->data[child]);
154 /****/
155 //i位置的数据大于小儿子 因为这个是最小堆 所以小儿子要往上挪
156 if(h->data[i] > h->data[child]){
157 /***/
158 printf("i位置元素:%d大于小儿子,小儿往上挪",h->data[i]);
159 /***/
160 h->data[i] = h->data[child];
161 }else{//只要没有发生交换 就已经可以停止了
162 break;
163 }
164 /****/
165 printf("当前h:");
166 printHeap(h);
167 /****/
168 }
169 //出来以后,i到了叶节点 要么i处于比小儿子还小的位置上
170 /***/
171 printf("最终i的位置为:%d\n",i);
172 printf("x为:%d",x);
173 /***/
174 h->data[i] = x;
175 }
176
177 //参数:返回删除的元素,指定堆
178 //C语言没有异常的机制,需要一个返回值来确认是否成功
179 //删除的堆可能会是空的,就会异常,所以不直接用返回值来作为删除掉的元素
180 int removeHeap(Elem *px, Heap h){
181 if(isEmpty(h)) return 0;//堆是空的,返回0
182 *px = h->data[1];//堆顶元素存到*px中
183 h->data[1] = h->data[h->size];//用最后一个元素上去顶替1号位置的堆顶
184 h->size --;//删除了少了一个
185 percolateDown(1,h);//把堆顶向下过滤
186 return 1;
187 }
188
189 //参数:指定列表?size?堆的最大容量
190 Heap buildHeap(Elem *a, int size, int max){
191 Heap h;
192 h = initHeap(max);
193 //h为空
194 if(!h) return NULL;
195 h->size = size;
196 //不需要写h->capacity = max 因为initHeap里面已经有了
197 for(int i = 1; i <= size; i ++){//谨记 为了找父节点和儿子节点方便 我们是不用0号位置的
198 //a是从0开始的 堆是从1开始的!!!
199 h->data[i] = a[i - 1];
200 printf("a[%d]:%d\n",i-1,a[i - 1]);
201 printf("h->data[%d]:%d\n",i,a[i - 1]);
202 }
203 //size / 2是最后一个节点的父亲,所以i=size/2就是找到最后一个有儿子的结点
204 //ppps:找父亲 i/2 找左节点 i*2 找右节点i*2 + 1
205 //放进去之后开始调整元素的顺序
206 //从什么地方开始调?最后一个有儿子的元素向下过滤
207 //不停地往上找父节点进行向下过滤,树根1号位置的数据可能也要调整,将所有的树调整为最小堆
208 //最后一个元素为h->data[size],那么它的父节点就是size/2
209 for(int i = size / 2; i > 0; i --){
210 percolateDown(i, h);
211 }
212 return h;
213 }
214
215 void destroy(Heap h){
216 free(h);
217 }
218
219 int main(){
220 /*调试堆的代码*/
221 Heap h;
222 h = initHeap(10);
223 insertHeap(20,h);
224 printHeap(h);
225 insertHeap(10,h);
226 printHeap(h);
227 insertHeap(5,h);
228 printHeap(h);
229 insertHeap(15,h);
230 insertHeap(30,h);
231 insertHeap(18,h);
232 printHeap(h);
233 Elem x;
234 removeHeap(&x,h);
235 printf("%d\n",x);
236 printHeap(h);
237
238 /*****基于一个列表创建堆*****
239 给出列表:90 20 70 10 30 40 15 25 35 45 11 80
240 创建最小堆
241 创建空堆O(logN),然后放进去 O(N)
242 总体效率为O(N*logN)
243 实际上我们还可以简化为O(N)的效率
244 分析一下:上面慢在哪里?因为每个元素插入都是放在最后面,要往上走最多要O(logN)
245 后来会越来越多元素,就越来越慢,我们就发现叶子点占据的操作时间非常多
246 能不能让这些数量最多的点的操作用的时间更少?
247 我们可以认为,叶子节点已经是一个堆,因为一个元素嘛,不论最大最小都是一个堆了,
248 那么叶子节点的上一层,这些点作为树根的树要成为最小堆,最多只需要调节一次,
249 直至最上面,树根,我们发现,只有这个调节时间是最长的,是logN,,而且它只会有一个
250 最终我们发现,占一半数量的叶子节点是不需要调节的,1/4的点调一层,1/8的点调两层
251 最后那个点要调logN层,总的时间为O(N).
252 //以下为根据列表创建堆的代码
253
254 /*Elem a[6] = {10, 50, 60, 5, 30, 20};
255 //创建capcity为50的堆,首先将上面的六个元素放进去初始化
256 Heap h;
257 h = buildHeap(a, 6, 50);
258 printHeap(h);
259 for(int i = 1; i <= 6; i ++){
260 printf("%d ",h->data[i]);
261 } */
262 destroy(h);
263 return 0;
264 }
265 ***堆的其他操作:提高元素优先级 降低元素优先级 删除元素(不只是堆顶)
266 ***大顶堆,只要加大这个数,就能提高它的优先级,小顶堆则相反
267 ***如何提高元素优先级? 提高优先级后 + percolateUp 就好了
268 ***如何降低元素优先级? 降低优先级后 + percolateDown 就好了
269 ***实际中的应用:例如病人的病情加重,或者减弱...
270 ***删除元素?我们之前只学过删除堆顶,那么如果我们要删除一个特定的元素,只要把这个元素弄膨胀
271 ***让它变成堆顶,我们就能删除它了。
272
273 ***下面来看一下其他的语言如何使用堆***
274 C++:
275 #include<iostream>
276 #include<queue>
277
278 using namespace std;
279
280 int main(){
281 //默认为大顶堆
282 //小顶堆要写成priorit_queue<int, vector<int>, greater<int>> q;
283 priority_queue<int> q;//堆就是优先队列的一种形式
284 q.push(111);
285 q.push(222);
286 q.push(333);
287 q.push(11);
288 q.push(22);
289 cout << q.top() << endl;
290 q.pop();
291 cout << q.top() << endl;
292 return 0;
293 }
294
295 JAVA:
296
297 import java.util.PriorityQueue;
298
299 public class Main{
300 public static void main(String[] args){
301 //默认为小顶堆
302 PriorityQueue<Integer> q = new PriorityQueue<>();
303 //大顶堆写法
304 //补充知识点:因为JAVA的函数,必须依靠类存在,所以在下面我们采取一种叫匿名内部类的东西
305 //注意,10虽然传入了大小,但是即使add多了,也会自动扩容,无影响
306 //实现了comparator这个接口的话 必须要实现compare方法
307 //写comparator比较麻烦,我们可以采取写lambda表达式的方法
308 PriorityQueue<Integer> q1 = new PriorityQueue<>(10,
309 new Comparator<Integer>(){
310 @override
311 public int compare(Integer o1, Integer o2){
312 return o2 - o1;
313 }
314 })
315
316 //Lambda表达式作为参数写法
317 PriorityQueue<Integer> q2 = new PriorityQueue<>(10, (a, b)->{return b - a;});
318 //*****
319 q.add(111);
320 q.add(222);
321 q.add(333);
322 q.add(444);
323 q.add(11);
324 q.add(22);
325 //java的弹出会返回弹出的元素 和C++有点不一样
326 System.out.println(q.poll());
327 }
328 }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号