Redis(2)主从,哨兵,集群
文章目录
前言
redis 主从配置(主从原理)
redis 哨兵配置(哨兵原理及特点)
redis 集群配置
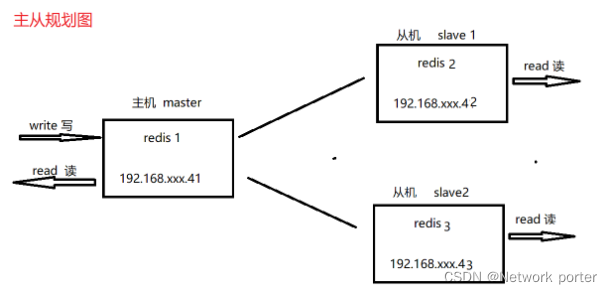
一、 redis 主从配置master slave
1. 好处
防止单点故障(除了单机版,都可以)
读写分离,更好的实现读多写少
2.实现 主 - (从-从)
克隆获得redis2和redis3,分别安装redis
复制redis.conf为master.conf,slaver1.conf ,slaver2.conf
cp /usr/redis/redis-5.0.5/redis.conf /usr/redis/bin/master.conf //redis1
cp /usr/redis/redis-5.0.5/redis.conf /usr/redis/bin/slave1.conf //redis2
cp /usr/redis/redis-5.0.5/redis.conf /usr/redis/bin/slave2.conf //redis3
在all-session 中:
修改配置文件:
-
在redis1修改配置文件 vim /usr/redis/bin/master.conf
:69 bind 192.168.*。 绑定虚拟机IP :
92 port 6666 端口号
:136 daemonize yes 守护进程 -
在redis2修改配置文件 vim slave1.conf
:136 daemonize yes 守护进程
:69 bind 192.168. **** 绑定虚拟机IP
:92 port 7777
在文件末尾加上一行: slaveof 192.168.170.41 6666 连接主redis -
在redis3修改配置文件 vim slave2.conf
:136 daemonize yes 守护进程
:69 bind 192.168. **** 绑定虚拟机IP
:92 port 7777
在文件末尾加上一行: slaveof 192.168.170.41 6666 连接主redis
启动
redis1:
/usr/redis/bin/redis-server /usr/redis/bin/master.conf
redis2:
/usr/redis/bin/redis-server /usr/redis/bin/slave1.conf
redis3:
/usr/redis/bin/redis-server /usr/redis/bin/slave2.confredis1写入数据:
set a 1 set b 2 redis2和redis3查看: keys *
3.特点
1、master/slave 角色
2、master/slave 数据相同
3、降低 master 读压力,从库分担
4.原理
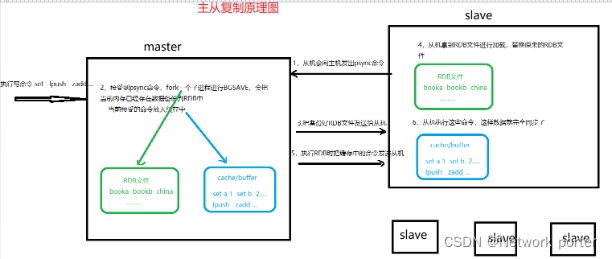
- 从服务器连接主服务器,发送 PSYNC(同步) 命令;
- 主服务器接收到 PSYNC 命名后,开始fork子进程执行 BGSAVE 命令生成 RDB 文件并使用缓冲区记录此后执行的所有写命令
- 主服务器 BGSAVE 执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
问题:
无法保证高可用(一旦主节点挂了,整个主从就不能写入数据)
没有解决 master 写的压力
二、 redis 哨兵配置 sentinel
1.好处
解决主从中出现master宕机,没有写节点的问题,从slave中选举新的主节点,执行写操作
2.实现
在redis1-3复制哨兵文件
cp /usr/redis/redis-5.0.5/sentinel.conf /usr/redis/bin/sentinel1.conf
cp /usr/redis/redis-5.0.5/sentinel.conf /usr/redis/bin/sentinel2.conf
cp /usr/redis/redis-5.0.5/sentinel.conf /usr/redis/bin/sentinel3.conf
修改:
vim /usr/redis/bin/sentinel1.conf //redis1 三台机子只有 哨兵端口不同 其他相同 注意防火墙
vim /usr/redis/bin/sentinel2.conf //redis2
vim /usr/redis/bin/sentinel3.conf //redis3
- #关闭保护模式 当开启保护模式的时候默认只能本机连
protected-mode no #17 - #哨兵端口
port 26666 #21 port 27777 port 28888 - #添加守护进程模式
daemonize yes #26 - #添加指明日志文件名
logfile “./temp.log” #36
-
#修改工作目录
dir “/tmp” #65 -
#哨兵监控的master名称可以随便起,ip和端口固定 quorum 当哨兵是集群时,有多少个哨兵认为master失效(客观下线),master才算失效。 遵循过半 3个就是 2个 认为 四个就是 三个认为 数量除以2 加一
sentinel monitor mymaster 192.168.106.130 6666 2 #84
![在这里插入图片描述]()
-
#master或slave多长时间(默认30秒)不能使用后标记为down状态。 多长时间连接不上就是下线 时间内 一次连上就在上线
sentinel down-after-milliseconds mymaster 30000 #113
![在这里插入图片描述]()
-
#设置master和slaves验证密码
sentinel auth-pass mymaster tiger #103


在主从的基础上打开 哨兵模式
启动 /usr/redis/bin/redis-sentinel /usr/redis/bin/sentinel1.conf //redis1
/usr/redis/bin/redis-sentinel /usr/redis/bin/sentinel2.conf //redis2
/usr/redis/bin/redis-sentinel /usr/redis/bin/sentinel3.conf //redis3
在all-session中:ps -ef |grep redis|grep -v grep 可以看到redis实例和哨兵实例
测试:
shutdown save 在redis1 执行
过一会查看是否其他redis 的role有一个是否切换为master
此时主从切换
再次启动 redis1
/usr/redis/bin/redis-server /usr/redis/bin/master.conf //启动redis1
/usr/redis/bin/redis-cli -h 192.168.170.41 -p 6666 使用客户端链接
redis1自动变为从机 在redis1宕机期间,其他主机执行命令的结果都会被同步
注意:超过半数哨兵宕机,则自动容灾无效
ps -ef|grep redis |grep -v
grep 找到哨兵进程 kill -9 杀死两个 关闭当前master 观察效果
3.特点
1、保证高可用(除了切换主从的一瞬间,集群是高可用)
2、哨兵监控各个节点
3、自动故障迁移
4.原理
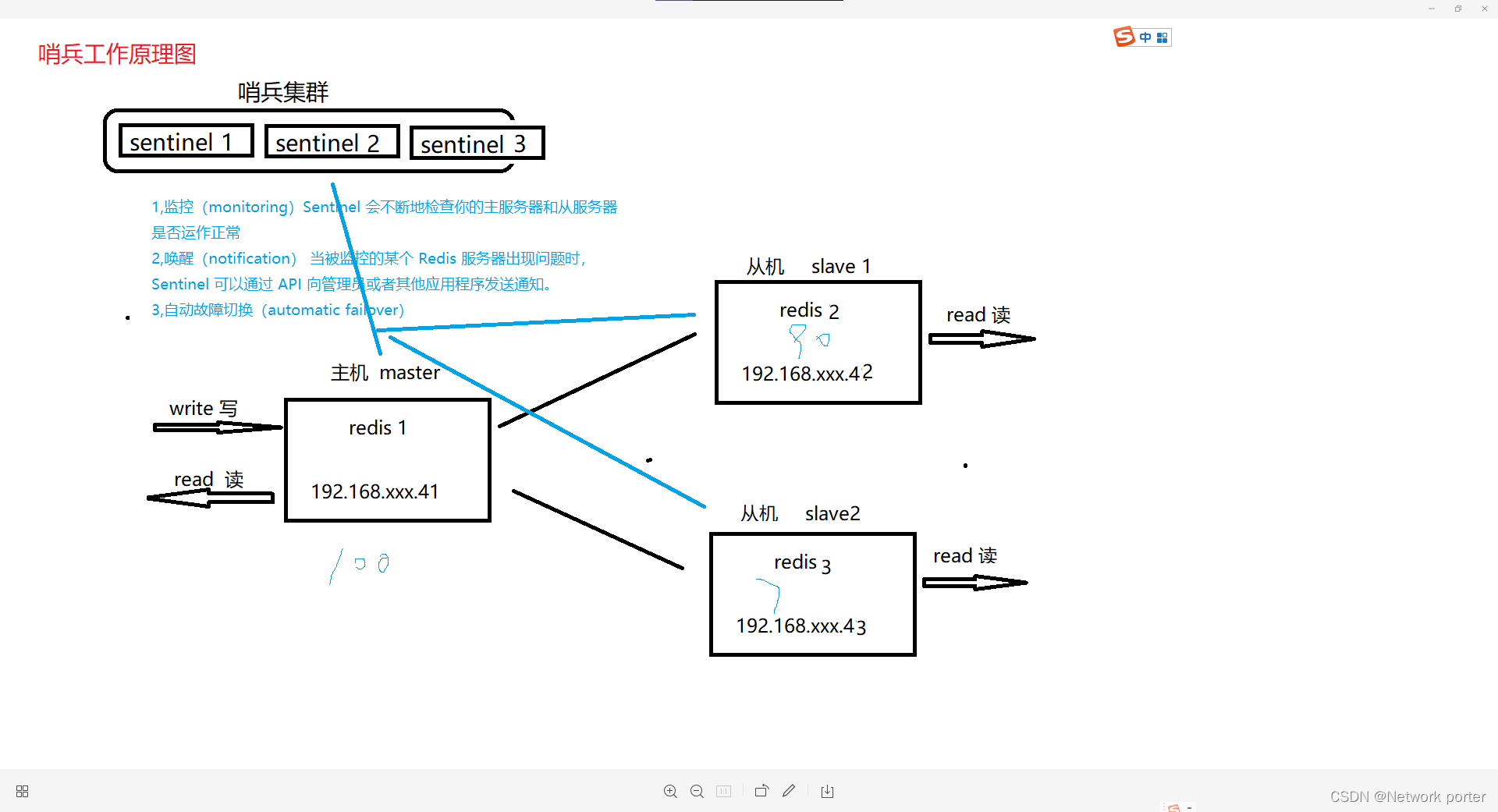
-
监控(Monitoring):Sentinel会不断地检查你的主服务器和从服务器是否运作正常 2个定时任务:
1)每10秒每个sentinel对master和slave执行info 目的:发现slave节点,确认主从关系 2) 每1秒每个sentinel对其他sentinel和redis实例 执行ping 目的:心跳检测,失败判定依据 -
当主机宕机
-
在从服务器中执行SLAVEOF NO ONE命令,断开主从关系并且提升为主库继续服务 当有多个从节点遵循下列原则选举新主节点
1). 选择slave-priority最高的slave节点(默认是相同)。
2). 选择复制偏移量(从节点同步主节点数据的数量)最大的节点。
3). 如果以上两个条件都不满足,选runId最小的(启动最早的)。 -
将主库重新启动后,执行SLAVEOF命令,将其设置为其他库的从库,数据更新回来
三、redis集群cluster
1.有什么用
redis为了提高网站响应速度,总是把热点数据保存在缓存中而不是直接从后端数据库中读取。一般大型网站有28定律 80%访问量集中在20%的业务上。大型网站应用,热点数据量往往巨大,使用一台 Redis 实例无满足需求,这时就需要使用 多台 Redis (集群)作为缓存数据库。才能在用户请求时快速的进行响应。
2.好处
- 高可用。放止单点故障
- 高性能。集群的每一台主机读写能力与单节点同级别,写压力多个节点分担
- 方便扩展,当每个节点变大或者变小,可以动态新加或者移除节点,集群正常使用
3.实现过程
-
redis集群设计架构
![在这里插入图片描述]()
-
架构细节
1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽. (2)节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群中的所有节点,连接集群中任何一个可用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value(key=values) 16384
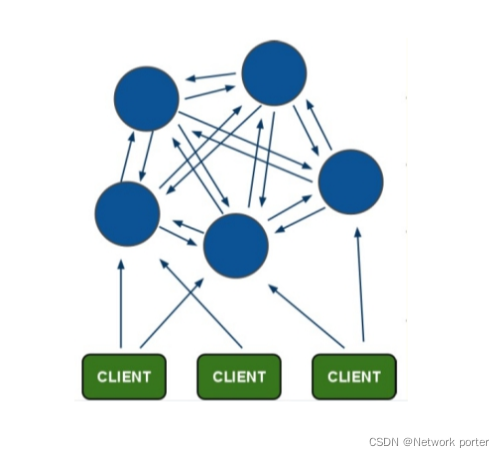
通俗的说,redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
4.具体实现
3台redis服务器 每一台服务器上放置2个节点,一共6个节点(3master 3slave)
192.168.170.41 : (6001 6002)
192.168.170.42: (6003 6004)
192.168.170.43: (6005 6006)
4.1创建单机redis
上面已经弄过了
4.2.单机创建节点
1)在每个单机 /usr/redis目录下创建 cluster 目录;
mkdir /usr/redis/cluster //在all-session中执行
ls /usr/redis 查看
2)在 cluster 下创建节点目录(为了方便区别,创建和端口号一样的目录)
检查 ls /usr/redis/cluster/ //在all-session中执行
mkdir /usr/redis/cluster/6001 /usr/redis/cluster/6002 // 在redis1执行
mkdir /usr/redis/cluster/6003 /usr/redis/cluster/6004 // 在redis2执行
mkdir /usr/redis/cluster/6005 /usr/redis/cluster/6006 // 在redis3执行
ls /usr/redis/cluster/ //在all-session中执行
3)复制redis.conf配置到节点目录下
cp /usr/redis/redis-5.0.5/redis.conf /usr/redis/cluster/6001
4)修改配置redis.conf:
vim /usr/redis/cluster/6001/redis.conf
/关键字 //例如 /port 在文件中查找port
bind 本机ip //默认ip为127.0.0.1 需要改为其他节点机器可访问的ip 否则创建集群时无法访问对应的端口,无法创建集群 69行
port 6001 //端口7001,7002,7003 92行
daemonize yes //redis后台运行 136行
pidfile /var/run/redis_6001.pid //pidfile文件对应7000,7001,7002 158行
appendonly yes //aof日志开启 有需要就开启,它会每次写操作都记录一条日志 699行
cluster-enabled yes //开启集群 把注释#去掉 832行
cluster-config-file nodes_6001.conf //集群的配置 配置文件首次启动自动生成 7000,7001,7002 840行
cluster-node-timeout 15000 //请求超时 默认15秒,可自行设置 846行
5)复制6001下redis.conf 到6002-6006
cp /usr/redis/cluster/6001/redis.conf /usr/redis/cluster/6002
//远程免密登录参考免密登录原理图
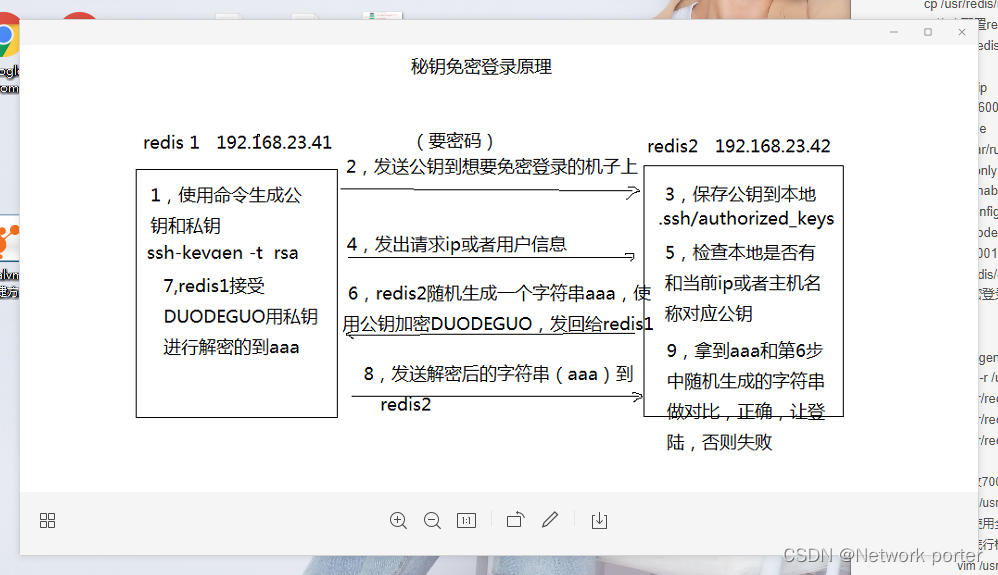
// ssh-keygen -t rsa ssh-copy-id 192.168.170.42/43
scp -r /usr/redis/cluster/6001/redis.conf 192.168.170.42:/usr/redis/cluster/6003
scp -r /usr/redis/cluster/6001/redis.conf 192.168.170.42:/usr/redis/cluster/6004
scp -r /usr/redis/cluster/6001/redis.conf 192.168.170.43:/usr/redis/cluster/6005
scp -r /usr/redis/cluster/6001/redis.conf 192.168.170.43:/usr/redis/cluster/6006
6) 修改7002-7006下的配置文件
vim /usr/redis/cluster/6002/redis.conf
使用全局替换,把6001替换为6002
底行模式下 :%s/6001/6002/g
vim /usr/redis/cluster/6003/redis.conf
:69行 改为对应的IP
底行模式下 :%s/6001/6003/g
其他同上
4.3如果多台主机都分别执行第2步操作
更多台主机同上
4.4/启动及检查
启动:
redis1:
/usr/redis/bin/redis-server /usr/redis/cluster/6001/redis.conf
/usr/redis/bin/redis-server /usr/redis/cluster/6002/redis.conf
redis2:
/usr/redis/bin/redis-server /usr/redis/cluster/6003/redis.conf
/usr/redis/bin/redis-server /usr/redis/cluster/6004/redis.conf
redis3:
/usr/redis/bin/redis-server /usr/redis/cluster/6005/redis.conf
/usr/redis/bin/redis-server /usr/redis/cluster/6006/redis.conf
关闭:
/usr/redis/bin/redis-cli -h 192.168.170.43 -p 6005 shutdown
检查:
ps -ef |grep redis-server |grep -v grep //在All-session执行 可以分别在3个窗口看到6个进程
4.5 使用命令创建集群
语法:
redis-cli --cluster create ip1:6000 ip1:6001 ip1:6002 ip2:6003 ip2:6004 ip2:6005 --cluster-replicas 1
实际操作:
/usr/redis/bin/redis-cli --cluster create 192.168.106.130:6001 192.168.106.130:6002 192.168.106.131:6003 192.168.106.131:6004 192.168.106.132:6005 192.168.106.132:6006 --cluster-replicas 1
成功
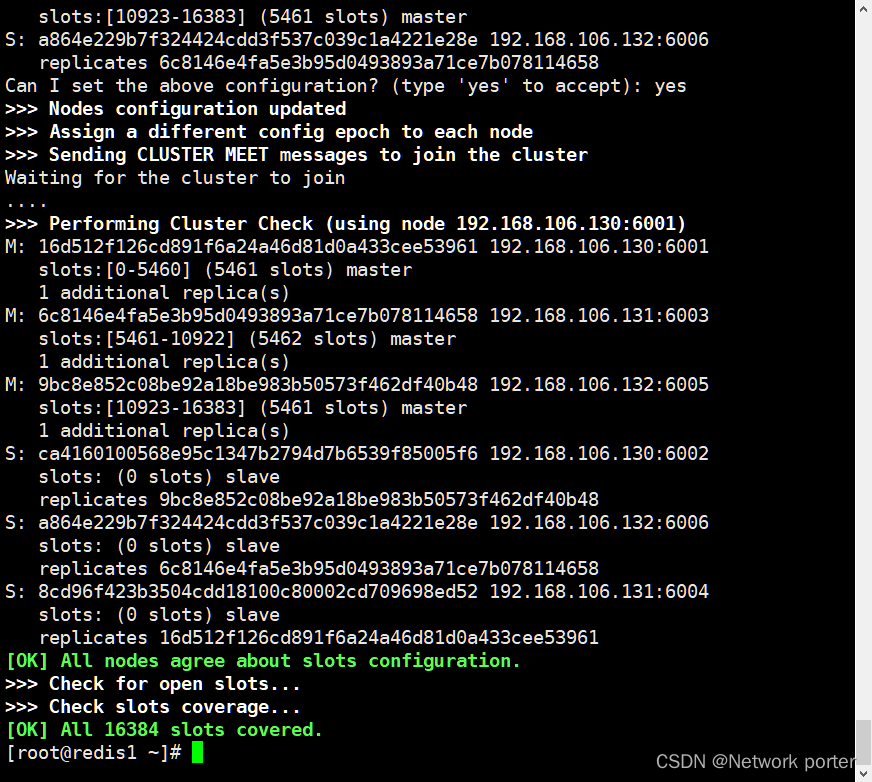
如果你做错了就把这几个配置删除重新检查配置 在 重启重新创建 重启启各个节点
rm -rf appendonly.aof dump.rdb nodes-600* //redis1-3都执行

如果出现create ERR Slot 0 is already busy错误,链接每一个节点,执行下面命令:
flushall //每个库都连接上,然后执行
//cluster reset
再次创建集群!
4.6. 链接测试
语法: ./redis-cli -c -h ip1 -p 端口号
/usr/redis/bin/redis-cli -c -h 192.168.106.130 -p 6001

Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。所以我们在测试的时候看到set 和 get 的时候,直接跳转到了7000端口的节点。
5.集群的使用
5.1.cluster info 显示集群信息
cluster_state: ok状态表示集群可以正常接受查询请求。fail 状态表示,至少有一个哈希槽没有被绑定(说明有哈希槽没有被绑定到任意一个节点) 。.
cluster_slots_assigned: 已分配到集群节点的哈希槽数量(不是没有被绑定的数量)。
cluster_slots_ok: 哈希槽状态不是FAIL 和 PFAIL 的数量.
cluster_slots_pfail: 哈希槽状态是 PFAIL的数量。只要哈希槽状态没有被升级到FAIL状态,这些哈希槽仍然可以被正常处理。PFAIL状态表示我们当前不能和节点进行交互,但这种状态只是临时的错误状态。
cluster_slots_fail: 哈希槽状态是FAIL的数量。如果值不是0,那么集群节点将无法提供查询服务,除非cluster-require-full-coverage被设置为no .
cluster_known_nodes: 集群中节点数量,包括处于握手状态还没有成为集群正式成员的节点.
cluster_size: 至少包含一个哈希槽且能够提供服务的master节点数量.
cluster_current_epoch: 集群本地Current Epoch变量的值。这个值在节点故障转移过程时有用,它总是递增和唯一的。
cluster_my_epoch: 当前正在使用的节点的Config Epoch值. 这个是关联在本节点的版本值.
cluster_stats_messages_sent: 通过node-to-node二进制总线发送的消息数量.
cluster_stats_messages_received: 通过node-to-node二进制总线接收的消息数量.
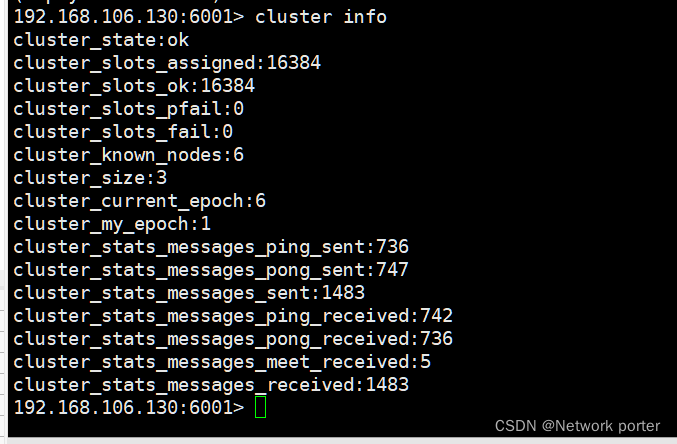
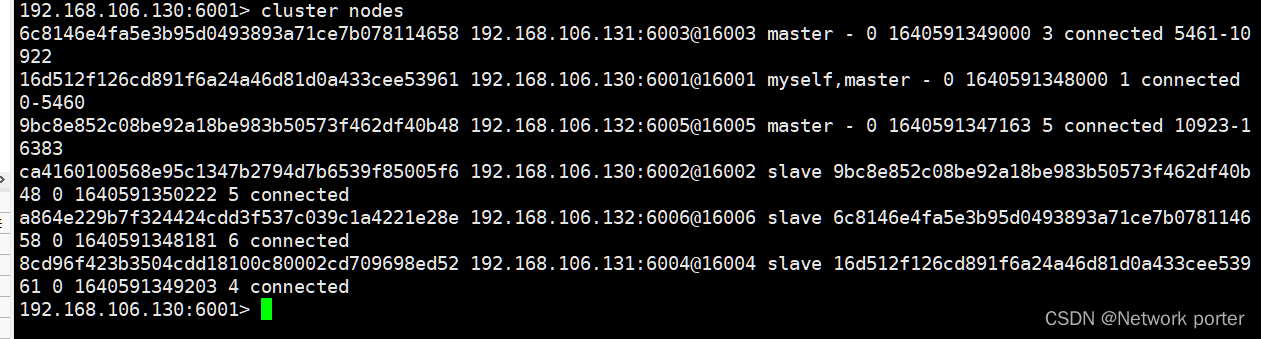

5.2。主节点异常,从节点自动顶替主节点
- 让节点故障
cluster nodes 主 从 6003 6006 6004 6001 6005 6002 - 让任意主节点故障
/usr/redis/bin/redis-cli -h 192.168.170.42 -p 6003 shutdown - 查看进程
ps -ef|grep redis-server|grep -v grep - 再次连接 /usr/redis/bin/redis-cli -h 192.168.170.41 -p 6001 -c
- 发现6006变为主节点 6003 fail cluster nodes
- 再次启动6003:
/usr/redis/bin/redis-server /usr/redis/cluster/6003/redis.conf - 查看进程是否启动成功:
ps -ef|grep redis-server|grep -v grep - 发现6003成为6006的从节点
方法1:
cluster nodes //节点信息的使用
ps -ef|grep redis // 在192.168.182.21
kill -9 主节点进程ID
kill -9 线程id
ps -ef|grep redis
使用客户端链接
./bin/redis-cli -c -h 192.168.182.20 -p 7001
链接集群,查看节点信息
cluster nodes
– 注意: 节点故障修复后,会被集群自动加入
./bin/redis-server cluster/7004/redis.conf //在192.168.182.21上执行
ps -ef|grep redis
5.3.集群的fail
1)集群任意master挂掉,且当前master没有slave.集群进入fail状态,因为集群的slot映射[0-16383]不完整,集群进入fail状态.
实例:
cluster nodes // 7002成为7006的从节点 7002和7006一组主从
挂掉任意两个master
/usr/redis/bin/redis-cli -h 192.168.170.42 -p 6004 shutdown
/usr/redis/bin/redis-cli -h 192.168.170.43 -p 6006 shutdown
再次连接 查看集群状态
//查看是否挂掉
/usr/redis/bin/redis-cli -h 192.168.170.41 -p 6001 -c
cluster info
cluster_state 为 fail
5.4.集群的启动和关闭
关闭,就是关闭所有节点
启动,就是启动所有节点(即使虚拟机重启,也不受影响)
编写的固定脚本
#!/bin/bash
rpsnum=`ps -ef|grep redis-server|grep -v grep|wc -l`
echo $rpsnum
if [ $rpsnum -eq 0 ];then
echo'准备启动'
ssh 192.168.106.130 "/usr/redis/bin/redis-server /usr/redis/cluster/6001/redis.conf"
ssh 192.168.106.130 "/usr/redis/bin/redis-server /usr/redis/cluster/6002/redis.conf"
ssh 192.168.106.131 "/usr/redis/bin/redis-server /usr/redis/cluster/6003/redis.conf"
ssh 192.168.106.131 "/usr/redis/bin/redis-server /usr/redis/cluster/6004/redis.conf"
ssh 192.168.106.132 "/usr/redis/bin/redis-server /usr/redis/cluster/6005/redis.conf"
ssh 192.168.106.132 "/usr/redis/bin/redis-server /usr/redis/cluster/6006/redis.conf"
echo 'redis集群启动完毕'
else
echo '准备关闭redis集群'
ssh 192.168.106.130 "/usr/redis/bin/redis-cli -h 192.168.106.130 -p 6001 shutdown"
ssh 192.168.106.130 "/usr/redis/bin/redis-cli -h 192.168.106.130 -p 6002 shutdown"
ssh 192.168.106.131 "/usr/redis/bin/redis-cli -h 192.168.106.131 -p 6003 shutdown"
ssh 192.168.106.131 "/usr/redis/bin/redis-cli -h 192.168.106.131 -p 6004 shutdown"
ssh 192.168.106.132 "/usr/redis/bin/redis-cli -h 192.168.106.132 -p 6005 shutdown"
ssh 192.168.106.132 "/usr/redis/bin/redis-cli -h 192.168.106.132 -p 6006 shutdown"
echo 'redis关闭完毕'
fi
6.集群节点,槽和值的关系
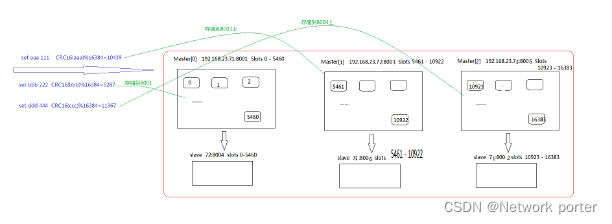
Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有 16384 个哈希槽,每个 key 通过 CRC16
校验后对 16384 取模来决 定放置哪个槽,集群的每个节点负责一部分 hash 槽
节点和槽: node 节点总数量(一共节点和副本数 一主一从 10 5master 5slave) 每个节点分的槽数为: 16384/master总数量
槽和值:
192.168.170.43:6005 master 10923-16383
192.168.170.42:6003 master 5461-10922
192.168.170.41:6001 master 0-5460
set aaa 111 根据key的值计算出一个hash值
hashFunction(‘aaa’) %16384=10439 -> 6003
7.特点
1、无中心架构(不存在哪个节点影响性能瓶颈),少了 proxy 层。
2、数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
3、可扩展性,可线性扩展到 1000 个节点,节点可动态添加或删除。
4、高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本
5、实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave到 Master 的角色提升。
Gossip (疫情传播算法)过程是由种子节点发起,当一个种子节点有状态需要更新到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。
缺点
1、资源隔离性较差,容易出现相互影响的情况(多个应用同时使用一个redis集群时,可能会出现)。
2、数据通过异步复制,不保证数据的强一致性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号