kafka (2)
文章目录
前言
kafka的整体工作流程
消息生产者写入消息过程
消息消费者消费要点
kafka的Java api
一、kafka的主体工作流程
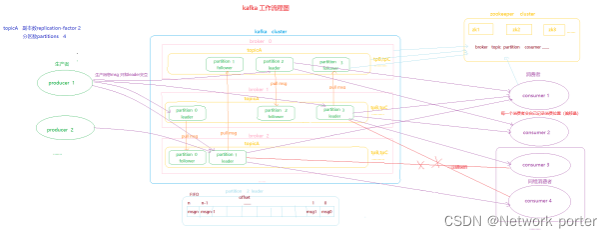
Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是producer生产的数据。Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。
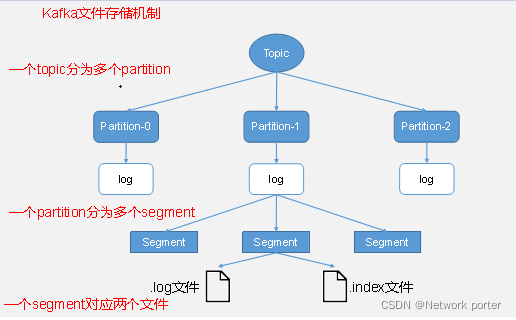
由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。每个segment对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。例如,first这个topic有三个分区,则其对应的文件夹为first-0,first-1,first-2。
00000000000000000000.index
00000000000000000000.log
00000000000000170410.index
00000000000000170410.log
00000000000000239430.index
00000000000000239430.log
index和log文件以当前segment的第一条消息的offset命名。下图为index文件和log文件的结构示意图。
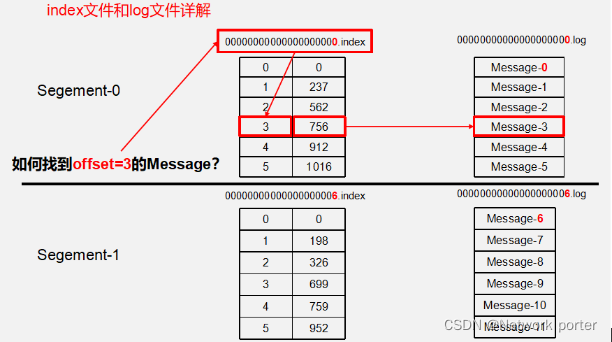
“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中message的物理偏移地址。
1.1. 分区的好处
1,方便集群的伸缩 每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了
2,可以提高并发,可以以Partition为单位读写,提高集群的读写速度
1.2 分区如何分配到broker上
- 保证所有的分区以及副本可以均衡在分布上所有的broker上
- 保证同一个分区及其副本尽量不要分布在同一个broker上
让分区和broker进行排序
partition leader排序: p0 p1 p2 p3
partition 副本: p0r p1r p2r p3r
broker排序: br0 br1 br2
分区怎么分配到broker上: p0随机一个broker topic越多,每个topic都对应有一个p0 越平均的分配到不同的broker
leader p0->br1 p1->br2 p2 ->br0 p3->br1
(p0随机,以后的放入下一个)
副本随机: p0r->br0 p1r->br1 p2r->br1 p3r->br2
1.3 副本(replication)的好处
提高kafka的系统的可靠性和稳定性,
同一个partitation对应一个或者多个副本,创建topic时就可以设置(–replication-factor 2)。没有副本,一旦当前保存消息的服务器宕机,就会造成消息丢失,如果有replication,当保存消 息的服务器宕机后,从新选举新的leader,继续进行消息读写,不会造成消息丢失。
1.4 zk保存kafka数据的目录结构 在卡夫卡集群的作用
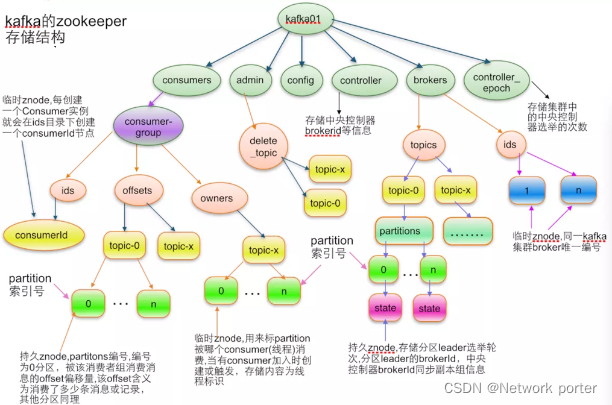
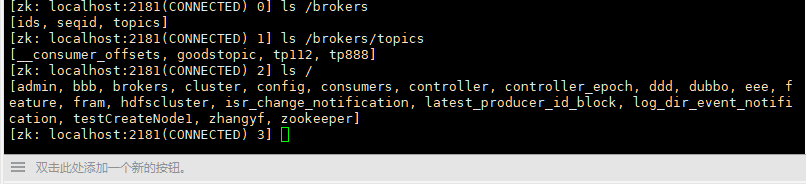
1 ,broker在zk中注册:集群启动时,每个broker都会在/brokers/ids/下注册(创临时节点),如果broker挂掉了,zk就会删除该节点。
2,topick会在zk中注册:创建topic时,每个topic都会在/brokers/topics/下注册,topic删除,节点失效。每个broker和topic的对应关系也是由zk进行维护。
3,consumer(消费者)在zk注册:当新的消费者都会zk进行注册,zk在/consumers/consumer-group/ 创建3个节点 ids offsets(偏移量) owners
ids: 记录当前消费者组所有的消费者id
offsets:消费者在消费topic每个partition时,消费到哪个位置(offset 偏移量)
owners:记录该消费者组消费的topic信息(订阅了哪些topic)
新版本无效
二、生产者怎么写消息
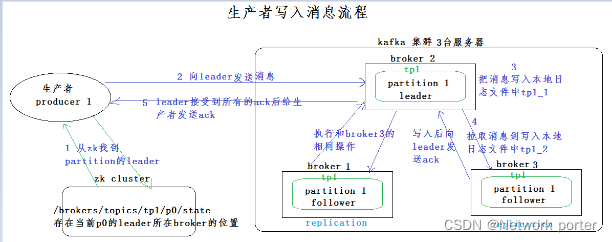
get /brokers/topics/tp888/partitions/0/state

为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。
2.1.消息的写入放入分区的规则
- 指定分区,直接按照指定分区写入
- 没有指定分区,但是消息中含有key(一般消息是key value的方式),通过key的值进行hash运算,计算得到一个partition,写入到这个分区。(aaa hash运算后可能得到一个和aaa没有任何关系的一个数值123132,对分区的总数量取模,根据结果,得到分区)
- 如果没有指定分区,key都没有,使用
轮询(第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin 算法),找出一个分区,并写入。
2.2.ack应答机制
0 producer 不等待broker同步完成的确认,继续发送下一条(批)信息
提供了最低的延迟。但是最弱的持久性,当服务器发生故障时,就很可能发生数据丢失。例如leader已经死亡,producer不知情,还会继续发送消息broker接收不到数据就会数据丢失
1 producer 要等待leader成功收到数据并得到确认,才发送下一条message。此选项提供了较好的持久性较低的延迟性。Partition的Leader死亡,follwer尚未复制,数据就会丢失
-1 意味着producer得到follwer确认,才发送下一条数据
2.3 ISR(IN Sync Replicas):
当ack配置-1时 leader收到数据,所有follower都开始同步数据,但有一个follower,因为某种故障,迟迟不能与leader进行同步,那leader就要一直等下去,直到它完成同步,才能发送ack。这个问题怎么解决呢?
Leader维护了一个动态的in-sync replica set (ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给follower发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由
replica.log.time.max.ms参数设定。Leader发生故障之后,就会从ISR中选举新的leader。
三、消费者消费
消息的消费模式有两种:推送模式(push) 和拉取模式(pull)
kafka采取的拉取模式(pull),由消费者自己记录消费状态(消费者自己记录自己的消费位置(offset偏移量)),每个消费者相互独立的消费每个一个分区的消息。每个消费者消费完了后,对消息本身不做任何处理,决定该消息是否能被删除,跟消费者没有任何关系,与配置的消息过期时间和消息总容量的大小配置参数有关(log.retention.hours=168 log.retention.bytes=1G)。
消费者是以消费者组( consumer group)的方式,由一个或者多个消费者组成一个组,共 同消费一个topic(主题),在同一时刻,只能由同一个组的一个消费者去消费同一个分区。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
四、kafka javaapi 的应用
4.1jarb
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- kafka客户端 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.7.0</version>
</dependency>
<!-- kafka-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>2.7.0</version>
</dependency>
4.2 编写工具类 对topic的查询删除创建
- 配置文件 kafka。properties
#这是一个用于建立初始连接到kafka集群的"主机/端口对"配置列表
bootstrap.servers=cluster1:9092,cluster2:9092,cluster3:9092
#发送应答(0:收到后直接响应成功,1:leader保存则响应成功,-1/all:leader和isr列表保存后才响应成功)
acks=all
# 失败重试次数
retries=0
#批量发送大小(默认:16384,16K)
batch.szie=16384
#发送延迟时间(默认:0)
linger.ms=1
- 加载配置文件工具类编写
package com.aaa.kfk.util;
import java.io.IOException;
import java.io.InputStream;
import java.util.Map;
import java.util.Properties;
import java.util.Set;
/**
* @author zhangyifan
* @version 8.0
* @description: kafka
* @date 2022/1/11 13:17
*/
public class LoadPropertiesUtil {
/**
* 加载配置文件
* @param path
* @return
*/
public static Properties loadProperties(String path){
InputStream inputStream = LoadPropertiesUtil.class.getResourceAsStream("/" + path);
Properties properties =new Properties();
try {
properties.load(inputStream);
return properties;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
public static void main(String[] args) {
Properties properties = loadProperties("kafka.properties");
Set<Map.Entry<Object, Object>> entries = properties.entrySet();
//推荐使用这个方式来遍历
for (Map.Entry<Object,Object> entry:entries){
System.out.println(entry.getKey()+","+entry.getValue());
}
}
}
- 编写topic工具类 KafkaJavaUtil
package com.aaa.kfk.util;
import org.apache.kafka.clients.admin.*;
import org.apache.kafka.common.KafkaFuture;
import java.util.*;
import java.util.concurrent.ExecutionException;
/**
* @author zhangyifan
* @version 8.0
* @description:
* @date 2022/1/11 13:24
*/
public class kafkaJavaUtil {
private AdminClient adminClient;
/**
* 初始化构造
*/
public kafkaJavaUtil() {
Properties properties = LoadPropertiesUtil.loadProperties("kafka.properties");
adminClient = KafkaAdminClient.create(properties);
}
/**
* 获取topic列表
*/
public List<String> getTopic(){
try {
//初始化一个对象
ListTopicsOptions options = new ListTopicsOptions();
//是否列出kafka内部使用的Topic 。 true 列出 false 不列出
options.listInternal(true);
//options.listInternal(false);
//获取 topic
ListTopicsResult listTopicsResult = adminClient.listTopics(options);
//获取名称
KafkaFuture<Set<String>> names = listTopicsResult.names();
Set<String> strings = names.get();
List<String> topicNames = new ArrayList<>();
for (String s:strings){
topicNames.add(s);
}
return topicNames;
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}finally {
if (adminClient!=null){
adminClient.close();
}
}
return null;
}
/**
* 创建topic
*/
public boolean createTopic(String topicName,int partitions,short replications){
try {
NewTopic newTopic = new NewTopic(topicName, partitions, replications);
adminClient.createTopics(Arrays.asList(newTopic));
return true;
}catch (Exception e){
e.printStackTrace();
}finally {
if (adminClient!=null){
adminClient.close();
}
}
return false;
}
/**
* 删除topic
*/
public boolean deleteTopic(String topicName){
try {
adminClient.deleteTopics(Arrays.asList(topicName));
return true;
}catch (Exception e){
e.printStackTrace();
}finally {
if (adminClient!=null){
adminClient.close();
}
}
return false;
}
}
- 设置测试类kafkaJavaUtilTest
![在这里插入图片描述]()
package com.aaa.kfk.test;
import com.aaa.kfk.util.kafkaJavaUtil;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.util.List;
import static org.junit.Assert.*;
public class kafkaJavaUtilTest {
private com.aaa.kfk.util.kafkaJavaUtil kafkaJavaUtil;
@Before
public void setUp() throws Exception {
kafkaJavaUtil = new kafkaJavaUtil();
}
@After
public void tearDown() throws Exception {
}
@Test
public void getTopic() {
List<String> topic =
kafkaJavaUtil.getTopic();
for (String s:topic
) {
System.out.println(s);
}
}
@Test
public void createTopic() {
boolean tp112 = kafkaJavaUtil.createTopic("tp888", 3, Short.valueOf("3"));
System.out.println(tp112);
if (tp112){
System.out.println("成功");
}else {
System.out.println("失败");
}
}
@Test
public void deleteTopic() {
boolean goodstopic = kafkaJavaUtil.deleteTopic("goodstopic");
if (goodstopic){
System.out.println("成功");
}else {
System.out.println("失败");
}
}
}
测试: 先启动 zk, 再启动kafka集群,然后测试
在allsession操作:
cd /usr/kafka
kafka-server-start.sh -daemon config/server.properties
jps
查看状态
4.3 编写生产者,写入消息(带回调的写入,测试消息写入时,放入的分区规则)
- 生产者配置文件 producer.properties
#建立初始连接到kafka集群的"主机/端口对"配置列表
bootstrap.servers=cluster1:9092,cluster2:9092,cluster3:9092
#序列化
key.serializer=org.apache.kafka.common.serialization.StringSerializer
value.serializer=org.apache.kafka.common.serialization.StringSerializer
#此配置是 Producer 在确认一个请求发送完成之前需要收到的反馈信息的数量。
#ack =acknowledge反馈信息 值=0 1 -1 分别代表什么意思
#acks=0 如果设置为0,则 producer 不会等待服务器的反馈。该消息会被立刻添加到 socket buffer 中并认为已经发送完成。
#acks=1 如果设置为1,leader节点会将记录写入本地日志,并且在所有 follower 节点反馈之前就先确认成功。
#acks=all acks=-1与acks=all是等效的。 如果设置为all,这就意味着 leader 节点会等待所有同步中的副本确认之后再确认这条记录是否发送完成。
acks=all
#若设置大于0的值,则客户端会将发送失败的记录重新发送,尽管这些记录有可能是暂时性的错误。
retries=3
#当将多个记录被发送到同一个分区时, Producer 将尝试将记录组合到更少的请求中。
batch.size=323840
#控制消息发送延时行为的,该参数默认值是0。表示消息需要被立即发送,无须关系batch是否被填满。
linger.ms=10
#Producer 用来缓冲等待被发送到服务器的记录的总字节数。
buffer.memory=33554432
#该配置控制 ProducerKafka.send()和KafkaProducer.partitionsFor() 允许被阻塞的时长。这些方法可能因为缓冲区满了或者元数据不可用而被阻塞。
max.block.ms=3000
- 消费者配置文件 consumer.properties
#建立初始连接到kafka集群的主机端口对配置列表
bootstrap.servers=cluster1:9092,cluster2:9092,cluster3:9092
#反序列化 消费者
key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
#消费者组id 测试是否同组 可以设置的 同时起多个消费者应该改个试试
group.id=groupOne
#如果为真,则用户的偏移量将在后台定期提交
enable.auto.commit=true
#使用者偏移自动提交到Kafka的频率(毫秒)
auto.commit.interval.ms=1000
#当kafka中没有初始偏移或服务器上不再存在当前偏移量
# earliest:自动将偏移重置为最早偏移
#latest:自动将偏移重置为最新偏移
# none:如果未找到使用者组的先前偏移量,则向使用者引发异常
#anything else: throw exception to the consumer.直接给消费者抛出异常
auto.offset.reset=earliest
topicName=tp888
- 消费者 ConsumerKafka
package com.aaa.kfk.demo;
import com.aaa.kfk.util.LoadPropertiesUtil;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.lang.reflect.Array;
import java.util.Arrays;
import java.util.Properties;
/**
* @author zhangyifan
* @version 8.0
* @description:
* @date 2022/1/12 9:32
*/
public class ConsumerKafka {
public static void main(String[] args) {
KafkaConsumer kafkaConsumer = null;
try {
//加载配置文件
Properties properties = LoadPropertiesUtil.loadProperties("consumer.properties");
//实例化
kafkaConsumer= new KafkaConsumer(properties);
//指定当前消费者订阅列表 可以是多个
kafkaConsumer.subscribe(Arrays.asList(properties.getProperty("topicName")));
//提示
System.out.println("消费者已经启动,等待生产生产信息》》》》");
//通过循环来消费信息
while(true){
//如果没有生产信息就会没隔500毫米拉取一次
ConsumerRecords<String,String> consumerRecords = kafkaConsumer.poll(500);
//循环拉取集合结果 iter快捷键
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println("信息的key:"+consumerRecord.key()+","+consumerRecord.value()
+",offset偏移量"+consumerRecord.offset()+",partition信息在分区"+consumerRecord.partition());
}
}
} catch (Exception e) {
e.printStackTrace();
}finally {
if (kafkaConsumer!=null){
kafkaConsumer.close();
}
}
}
}
- 生产者ProducerKafka.class
package com.aaa.kfk.demo;
import com.aaa.kfk.util.LoadPropertiesUtil;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* @author zhangyifan
* @version 8.0
* @description:
* @date 2022/1/12 10:11
*/
public class ProducerKafka {
public static void main(String[] args) {
KafkaProducer kafkaProducer = null;
try {
//加载配置文件
Properties properties = LoadPropertiesUtil.loadProperties("producer.properties");
//实例化
kafkaProducer = new KafkaProducer(properties);
for (int i = 0; i < 100; i++) {
System.out.println("发送信息"+"hello"+i);
ProducerRecord producerRecord = new ProducerRecord(properties.getProperty("topicName"),"hello"+i);
// ProducerRecord producerRecord1 = new ProducerRecord("tp888","aaa","111");
//ProducerRecord producerRecord2 = new ProducerRecord("tp888",1,"aaa","111");
//发送消息
kafkaProducer.send(producerRecord);
//设置时间间隔 200 毫米
Thread.sleep(200);
}
} catch (Exception e) {
e.printStackTrace();
}finally {
if (kafkaProducer!=null){
kafkaProducer.close();
}
}
}
}
- 带会调函数的生产者
package com.aaa.kfk.demo;
import com.aaa.kfk.util.LoadPropertiesUtil;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
/**
* @author zhangyifan
* @version 8.0
* @description:
* @date 2022/1/12 10:11
*/
public class ProducerKafkaWithClallback {
public static void main(String[] args) {
KafkaProducer kafkaProducer = null;
try {
//加载配置文件
Properties properties = LoadPropertiesUtil.loadProperties("producer.properties");
//实例化
kafkaProducer = new KafkaProducer(properties);
for (int i = 0; i < 100; i++) {
System.out.println("发送信息"+"hello"+i);
// ProducerRecord producerRecord = new ProducerRecord(properties.getProperty("topicName"),"helloQy141"+i);
// ProducerRecord producerRecord1 = new ProducerRecord("tp888","aaa","111");
//指定分区和 key 好value无关 因为我的kafka只设置了三个 只有 三个分区 0 1 2
ProducerRecord producerRecord2 = new ProducerRecord("tp888",1,"key"+1,"111");
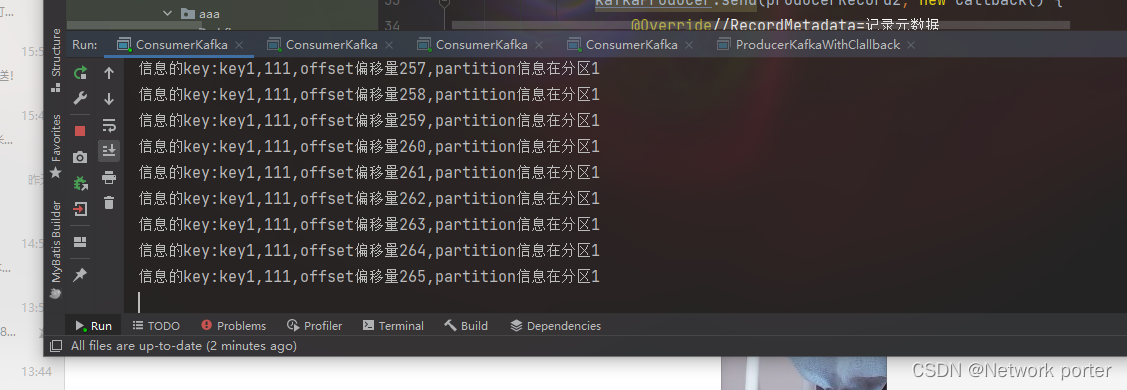
//发送消息并带会调函数(根据会调函数可以看到该消息被存放的分区和偏移量等信息)
kafkaProducer.send(producerRecord2, new Callback() {
@Override//RecordMetadata=记录元数据
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println("----------该消息的分区为:+"+recordMetadata.partition()+",偏移量为,"+recordMetadata.offset());
}
});
//设置时间间隔 200 毫米
Thread.sleep(200);
}
} catch (Exception e) {
e.printStackTrace();
}finally {
if (kafkaProducer!=null){
kafkaProducer.close();
}
}
}
}
测试
默认轮询
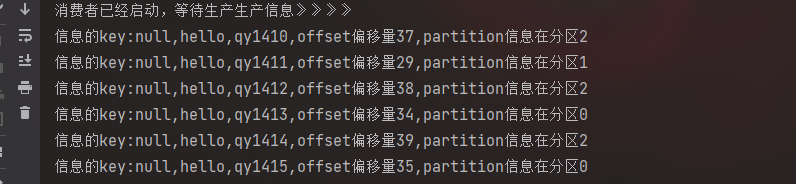
同分区设置分区后
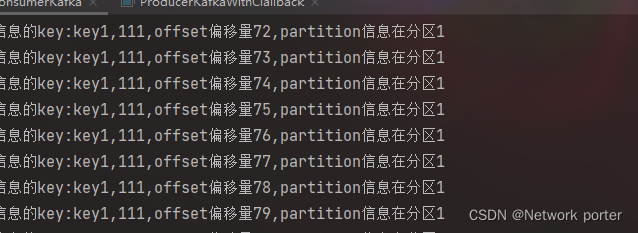
注意偏移量

会记录下来

测试同组和不同组消费者的消费情况)
结果是 同组只会有一个消费到
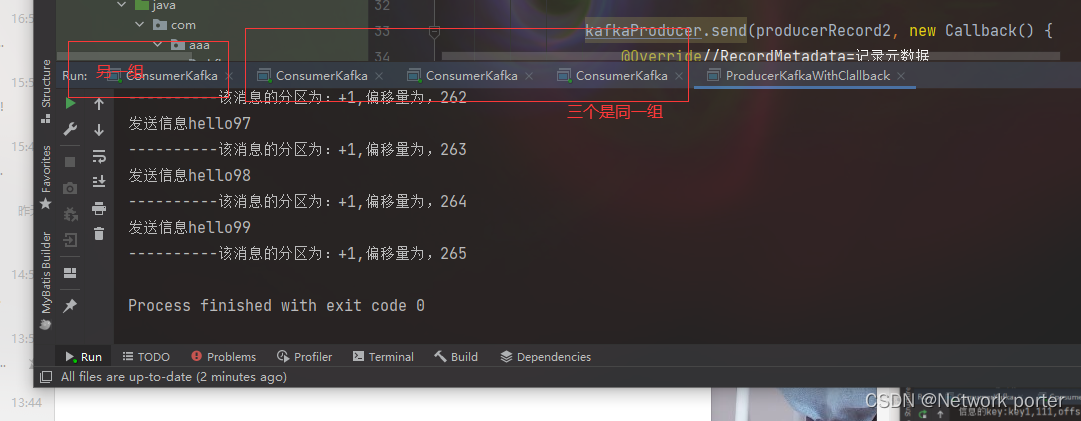
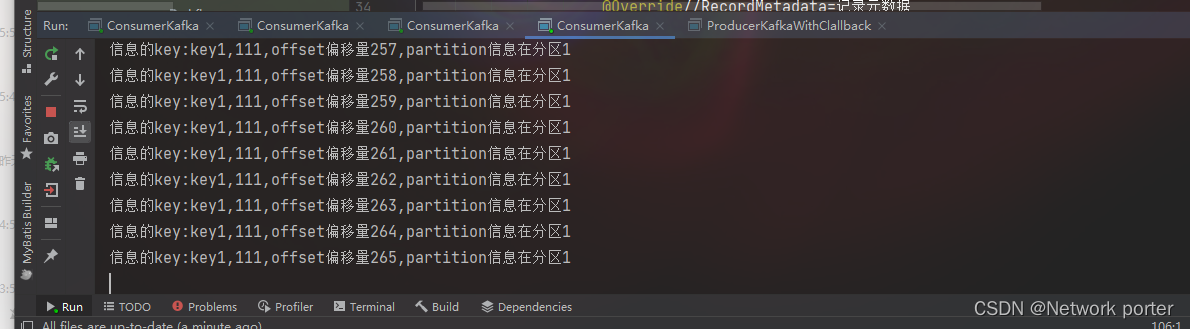


 浙公网安备 33010602011771号
浙公网安备 33010602011771号