Django 框架总结
Django 学习
# 官方文档
https://docs.djangoproject.com/zh-hans/2.2/howto/
https://docs.djangoproject.com/zh-hans/2.2/contents/
# yuan老师
https://www.cnblogs.com/dealdwong2018/p/10192628.html
Django 基础配置
创建 django 项目
创建新的项目
# django-admin startproject + 项目名
django-admin startproject project_name
创建一个 app
# 进入创建的项目
cd project_name
# 创建一个app: python manage.py + app名字
python manage.py startapp app_name
注册app
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01', # 注册app01
]
项目目录
# 文件树
django_project
app01
__init__.py
admin.py
apps.py
models.py
views.py
urls.py # 自己创建的 urls.py
django_project
__init__.py
settings.py
urls.py
wsgi.py
static
静态文件引用
manage.py
配置静态文件
Static 静态文件配置官网 : django
# https://docs.djangoproject.com/en/2.1/howto/static-files/
Static 静态文件配置
# 在 settings.py 文件中配置
# 静态文件的路由 在浏览器中访问即可
STATIC_URL = '/static/'
# 静态文件的文件夹位置(所有文件夹的位置)
STATICFILES_DIRS = [
# 拼接文件位置,BASE_DIR + static
# /opt/django_project/ + static => /opt/django_project/static
os.path.join(BASE_DIR, "static"),
# nginx 反向代理服务器存在的静态文件
'/var/www/static/',
]
Media 配置
- 静态文件种类
/static/ # 服务器需要的静态资源
js/
css/
img/
/media/ # 用户上传的静态资源
- media 上次路径配置
- django 为了不想让以上两种资源 混放 在一起,做一个解耦;
- 配置完成后, 无论以后上传什么文件,都会放在 media 文件夹中
# settings.py
# 让 django 找到 media 文件夹
MEDIA_ROOT = os.path.join(BASE_DIR, "media")
Media 路由配置
# settings.py
MEDIA_URL = '/media/'
# blog/urls.py
from django.views.static import serve
from blog_work import settings
urlpatterns = [
re_path(r'media/(?P<path>.*)$', serve, {'document_root': settings.MEDIA_ROOT})
]
模板文件配置
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
# DIRS 配置 html 所在的文件夹
'DIRS': [os.path.join(BASE_DIR, 'templates')],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
Django url 路由
普通配置
# project/urls.py 中配置文件
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
# 路由分发
path('app01/', include("app01.urls")),
]
# app01/urls.py 中配置文件
from django.urls import path, re_path
from ./ import view
urlpatterns = [
# 简单匹配
re_path('index/1999/$'),
]
无名分组
# app01/urls.py 中配置文件
# 无名分组: 分组中的数值作为参数传入 func 中, 按位置传参
urlpatterns = [
# 将 ([0-9]{4}) 作为参数传入到 func 中
# http://127.0.0.1:8000/app01/1998 func(request, 1998)
re_path('([0-9]{4})/$', view.func),
# http://127.0.0.1:8000/app01/1998/02/ func01(request, 1998, 02)
re_path("([0-9]{4})/([0-9]{2})/$", views.func01),
]
有名分组
# app01/urls.py 中配置文件
# 有名分组 /(?P<参数>正则表达式)/ :对函数进行关键字传参
# 此时 func02 中的参数位置可不按顺序编写
urlpatterns = [
# http://127.0.0.1:8000/app01/1998/23 func02(request, year=1998, month=23)
re_path("(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$", views.func02)
# http://127.0.0.1:8000/app01/1998/23/21 func03(request, year=1998, month=23, day=31)
re_path("(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]{2})/$", views.func03)
]
path 转换器
- 和有名分组一样
urlpatterns = [
# http://127.0.0.1:8000/app01/121 func03(request, id=121)
path("<int:id>/", views.func03),
path("<int:year>/<int:month>", views.func04),
path("<int:year>/<int:month>/<int:day>", views.func05),
path("<str:uuid>/", views.func06),
]
# str - 匹配除了 '/' 之外的非空字符串。如果表达式内不包含转换器,则会默认匹配字符串。
# int - 匹配0或任何正整数。返回一个 int 。
# slug - 匹配任意由 ASCII 字母或数字以及连字符和下划线组成的短标签。比如,building-your-1st-django-site 。
# uuid - 匹配一个格式化的 UUID 。为了防止多个 URL 映射到同一个页面,必须包含破折号并且字符都为小写。比如,075194d3-6885-417e-a8a8-6c931e272f00。返 回一个 UUID 实例。
# path - 匹配非空字段,包括路径分隔符 '/' 。它允许你匹配完整的 URL 路径而不是像 str 那样匹配 URL 的一部分。
反向解析
html 中使用反向解析
- 用于解决更改url后, html原有路由失效问题
urlpatterns = [
path("login/", view.login, name="user_Login")
]
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
/* 此时无论上面的url如何改动, 只要 user_Login 不变, action中的路由就可以一直找到login/ */
<form action="{% url 'user_Login' %}" method="POST">
<input type="text" value="username">
<input type="text" value="password">
<input type="submit" value="提交">
</form>
</body>
</html>
python 代码中使用反向解析
urlpatterns = [
path("login/", view.login, name="user_Login"),
]
# app01/views.py
from django.urls import reverse
def login(request):
return HttpResponse("")
def func05(request):
# 无参数的
url = reverse("user_Login")
print(url)
# 有参数的
url = reverse("user_Login", args=(4001, )) # app01/login/([0-9]{4})
print(url)
return HttpResponse("ok")
名称空间
- 防止路由别名重名, 导致反向解析出现异常
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
# django==2.1.2
path('app01/', include(("app01.urls", "app01"))),
path('app02/', include(("app02.urls", "app02"))),
]
from django.shortcuts import render, HttpResponse
from django.urls import reverse
def index(request):
# 反向解析 找到路由地址
url = reverse("app02:index")
print(url) # /app02/index/
return HttpResponse("OK")
Django Templates 模板层
模板语法
变量引用
# views.py
def views(request):
user = "username"
return render(request, 'index.html', locals())
# html
<p>{{ user }}</p>
模板标签
- for 标签
# views.py
def views(request):
user_list = ['u1', 'u2', 'u3', 'u4']
return render(request, 'index.html', locals())
# html
{% for user in user_list %}
<p>{{ user }}</p>
{% endfor %}
# 获取循环序号
{% forloop %}
- if 标签
{% if num > 100 or num < 0 %}
<p>无效</p>
{% elif num > 80 and num < 100 %}
<p>优秀</p>
{% else %}
<p>凑活吧</p>
{% endif %}
过滤器
- default
# 如果一个变量是false或者为空,使用给定的默认值。否则,使用变量的值。例如:
{{ value|default: "nothing" }}
- length
# 返回值的长度。它对字符串和列表都起作用。例如:
{{ value|length }}
# 如果 value 是 ['a', 'b', 'c', 'd'],那么输出是 4。
- filesizeformat
# 将值格式化为一个 “人类可读的” 文件尺寸 (例如 '13 KB', '4.1 MB', '102 bytes', 等等)。例如:
{{ value|filesizeformat }}
# 如果 value 是 123456789,输出将会是 117.7 MB。
- date
# 如果 value=datetime.datetime.now()
{{ value|date:"Y-m-d" }}
- slice:字符串切片
# 如果 value="hello world"
{{ value|slice:"2:-1" }}
- truncatechars
# 如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列(“...”)结尾。
# 参数:要截断的字符数
{{ value|truncatechars:9 }}
- safe
value="<a href="">点击</a>"
{{ value|safe }}
Django model 模型层
ORM 使用
ORM 是: “对象-关系-映射”简称
- 示例
# models.py 文件
from django.db import models
class Table(models.Model):
id = models.AutoField(primary_key=True) # 主键自增
name = models.CharField(max_length=32, default=None) # 字符串类型; 最大长度 32 位; 默认值为 None
sex = models.BooleanField(default=True) # bool 类型 默认值为 True
age = models.IntegerField() # int 类型;长度为11;4个字节
price = models.DecimalField(max_digits=8, decimal_places=2) # 99999.99; 总长度8; 小数点后两位 2;
create_time = models.DateTimeField(auto_now_add=True) # 创建时间 auto_now_add
update_time = models.DateTimeField(auto_now=True) # 更新时间 auto_now
常用字段
<1> CharField
字符串字段, 用于较短的字符串.
CharField 要求必须有一个参数 maxlength, 用于从数据库层和Django校验层限制该字段所允许的最大字符数.
<2> IntegerField
#用于保存一个整数.
<3> FloatField
一个浮点数. 必须 提供两个参数:
参数 描述
max_digits 总位数(不包括小数点和符号)
decimal_places 小数位数
举例来说, 要保存最大值为 999 (小数点后保存2位),你要这样定义字段:
models.FloatField(..., max_digits=5, decimal_places=2)
要保存最大值一百万(小数点后保存10位)的话,你要这样定义:
models.FloatField(..., max_digits=19, decimal_places=10)
admin 用一个文本框(<input type="text">)表示该字段保存的数据.
<4> AutoField
一个 IntegerField, 添加记录时它会自动增长. 你通常不需要直接使用这个字段;
自定义一个主键:my_id=models.AutoField(primary_key=True)
如果你不指定主键的话,系统会自动添加一个主键字段到你的 model.
<5> BooleanField
A true/false field. admin 用 checkbox 来表示此类字段.
<6> TextField
一个容量很大的文本字段.
admin 用一个 <textarea> (文本区域)表示该字段数据.(一个多行编辑框).
<7> EmailField
一个带有检查Email合法性的 CharField,不接受 maxlength 参数.
<8> DateField
一个日期字段. 共有下列额外的可选参数:
Argument 描述
auto_now 当对象被保存时,自动将该字段的值设置为当前时间.通常用于表示 "last-modified" 时间戳.
auto_now_add 当对象首次被创建时,自动将该字段的值设置为当前时间.通常用于表示对象创建时间.
(仅仅在admin中有意义...)
<9> DateTimeField
一个日期时间字段. 类似 DateField 支持同样的附加选项.
<10> ImageField
类似 FileField, 不过要校验上传对象是否是一个合法图片.#它有两个可选参数:height_field和width_field,
如果提供这两个参数,则图片将按提供的高度和宽度规格保存.
<11> FileField
一个文件上传字段.
要求一个必须有的参数: upload_to, 一个用于保存上载文件的本地文件系统路径. 这个路径必须包含 strftime #formatting,
该格式将被上载文件的 date/time
替换(so that uploaded files don't fill up the given directory).
admin 用一个<input type="file">部件表示该字段保存的数据(一个文件上传部件) .
注意:在一个 model 中使用 FileField 或 ImageField 需要以下步骤:
(1)在你的 settings 文件中, 定义一个完整路径给 MEDIA_ROOT 以便让 Django在此处保存上传文件.
(出于性能考虑,这些文件并不保存到数据库.) 定义MEDIA_URL 作为该目录的公共 URL. 要确保该目录对
WEB服务器用户帐号是可写的.
(2) 在你的 model 中添加 FileField 或 ImageField, 并确保定义了 upload_to 选项,以告诉 Django
使用 MEDIA_ROOT 的哪个子目录保存上传文件.你的数据库中要保存的只是文件的路径(相对于 MEDIA_ROOT).
出于习惯你一定很想使用 Django 提供的 get_<#fieldname>_url 函数.举例来说,如果你的 ImageField
叫作 mug_shot, 你就可以在模板中以 {{ object.#get_mug_shot_url }} 这样的方式得到图像的绝对路径.
<12> URLField
用于保存 URL. 若 verify_exists 参数为 True (默认), 给定的 URL 会预先检查是否存在( 即URL是否被有效装入且
没有返回404响应).
admin 用一个 <input type="text"> 文本框表示该字段保存的数据(一个单行编辑框)
<13> NullBooleanField
类似 BooleanField, 不过允许 NULL 作为其中一个选项. 推荐使用这个字段而不要用 BooleanField 加 null=True 选项
admin 用一个选择框 <select> (三个可选择的值: "Unknown", "Yes" 和 "No" ) 来表示这种字段数据.
<14> SlugField
"Slug" 是一个报纸术语. slug 是某个东西的小小标记(短签), 只包含字母,数字,下划线和连字符.#它们通常用于URLs
若你使用 Django 开发版本,你可以指定 maxlength. 若 maxlength 未指定, Django 会使用默认长度: 50. #在
以前的 Django 版本,没有任何办法改变50 这个长度.
这暗示了 db_index=True.
它接受一个额外的参数: prepopulate_from, which is a list of fields from which to auto-#populate
the slug, via JavaScript,in the object's admin form: models.SlugField
(prepopulate_from=("pre_name", "name"))prepopulate_from 不接受 DateTimeFields.
<13> XMLField
一个校验值是否为合法XML的 TextField,必须提供参数: schema_path, 它是一个用来校验文本的 RelaxNG schema #的文件系统路径.
<14> FilePathField
可选项目为某个特定目录下的文件名. 支持三个特殊的参数, 其中第一个是必须提供的.
参数 描述
path 必需参数. 一个目录的绝对文件系统路径. FilePathField 据此得到可选项目.
Example: "/home/images".
match 可选参数. 一个正则表达式, 作为一个字符串, FilePathField 将使用它过滤文件名.
注意这个正则表达式只会应用到 base filename 而不是
路径全名. Example: "foo.*\.txt^", 将匹配文件 foo23.txt 却不匹配 bar.txt 或 foo23.gif.
recursive可选参数.要么 True 要么 False. 默认值是 False. 是否包括 path 下面的全部子目录.
这三个参数可以同时使用.
match 仅应用于 base filename, 而不是路径全名. 那么,这个例子:
FilePathField(path="/home/images", match="foo.*", recursive=True)
...会匹配 /home/images/foo.gif 而不匹配 /home/images/foo/bar.gif
<15> IPAddressField
一个字符串形式的 IP 地址, (i.e. "24.124.1.30").
<16> CommaSeparatedIntegerField
用于存放逗号分隔的整数值. 类似 CharField, 必须要有maxlength参数.
<17> DecimalField
小数 max_digits 为小数的总长度 , decimal_places 为小数点后的长度
常用参数
(1)null
如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False.
(1)blank
如果为True,该字段允许不填。默认为False。
要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。
如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。
(2)default
字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。
(3)primary_key
如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True,
Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为,
否则没必要设置任何一个字段的primary_key=True。
(4)unique
如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的
(5)choices # 枚举 choices=[("male", "男"), ("female", "女")]
由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,默认的表单将是一个选择框而不是标准的文本框,<br>而且这个选择框的选项就是choices 中的选项。
django 连接mysql数据库
settings 配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', # 数据库引擎
'NAME': "django_learn", # 数据库名
"HOST": "10.2.38.195", # 数据库所在主机IP
"PORT": 3306, # 数据库端口号
"USER": "root", # 数据库用户名
"PASSWORD": "Troila12#$" # 数据库密码
}
}
pymysql 配置
- django默认你导入的驱动是MySQLdb,可是MySQLdb 对于py3有很大问题,所以我们需要的驱动是PyMySQL ,我们只需要找到项目名文件下的__init__.py
# django_project/__init__.py
import pymysql
pymysql.install_as_MySQLdb()
数据库迁移
- 数据库迁移命令
# 生成 sql 语句
python manage.py makemigrations
# 将sql语句在mysql数据库中执行
python manage.py migrate
sql 语句输出
# 如果想打印orm转换过程中的sql,需要在settings中进行如下配置:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
model 操作数据表(单表操作)
from django.db import models
# Create your models here.
# 作者表
class Author(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32, null=False)
sex = models.CharField(max_length=16, choices=[("male", "男"), ("female", "女")], default='male')
age = models.SmallIntegerField()
# 作者详情
class AuthorDetail(models.Model):
id = models.AutoField(primary_key=True)
address = models.CharField(max_length=32)
wife = models.CharField(max_length=32)
author_id = models.OneToOneField(to="Author", to_field="id", on_delete=models.CASCADE)
# 书籍表
class Book(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
# ForeignKey(related_name="book") related_name:此参数反向查询时调用, 默认值为 book (小写类名)
publish_id = models.ForeignKey(to="Publish", to_field="id", on_delete=models.CASCADE, null=True)
author_id = models.ManyToManyField(to="Author")
# 出版社表
class Publish(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
address = models.CharField(max_length=32)
添加表记录
class() : 用初始化model类进行增加数据
book_obj = Book(b_name="水浒传", pub="人民日报出版社", price=10.4)
book_obj.save()
create() : 用objects工具新增一条数据
# book_obj 是 Book() 的对象
book_obj = Book.objects.create(b_name="红楼梦", pub="清华大学出版社", price=10.4)
print(book_obj)
bulk_create() : 用objects工具批量插入数据
models.Book.objects.bulk_create(object_list, batch_size=100)
查询表记录
all(): 查询所有数据
- all() 的返回值是一个 QuerySet[ ] 对象;
- QuerySet[]: 支持 first() last() 方法
book_ret = Book.objects.all()
print(book_ret) # <QuerySet [<Book: 水浒传>, <Book: 红楼梦>, <Book: 红楼梦>]>
print(book_ret.first(), book_ret.first().b_name, book_ret.first().price) # 水浒传 水浒传 10.40
print(book_ret.last())
filter(): (单或多)条件查找
- filter() 的返回值也是一个 QuerySet[ ] 对象
book_ret = Book.objects.filter(b_name="红楼梦")
print(book_ret) # <QuerySet [<Book: 红楼梦>, <Book: 红楼梦>]>
get(): 唯一值查找
-
唯一条件索引, 只能查找主键、唯一键、唯一值;
-
不存在或超过一个值都会报错
# id=1 存在
book_ret = Book.objects.get(id=1)
print(book_obj)
# b_name="水浒传" 存在且只有一个
book_ret = Book.objects.get(b_name="水浒传")
print(book_ret)
# id = 2 不存在, get() 方法报错
# error: Book matching query does not exist.
book_ret = Book.objects.get(id=2)
print(book_ret)
values(): 查询某些字段
- 返回值为 QuerySet[ { }, { } ]
book_ret = Book.objects.all().values("id", "b_name")
print(book_ret) # <QuerySet [{'id': 1, 'b_name': ' '}, {'id': 3}, {'id': 4}]>
value_list():查询某些字段
- 返回值为 QuerySet[ (, ) , ( , ) ]
book_ret = Book.objects.all().values_list("id")
print(book_obj) # <QuerySet [(1,), (3,), (4,)]>
distinct(): 剔除查询后的重复数据
- 所有数据进行剔除没有意义 因为主键一定不重复
- 常配合 values() value_list() 方法使用
# 剔除重复的书名
book_ret = Book.objects.all().values("b_name").distinct()
print(book_ret) # <QuerySet [{'b_name': '水浒传'}, {'b_name': '红楼梦'}]>
查询API
# **kwargs 关键字传参;*field 按位置传参;
<1> all(): 查询所有结果 # 返回值类型 QuerySet[]
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 # 返回值类型 QuerySet[]
<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,
如果符合筛选条件的对象超过一个或者没有都会抛出错误。 # 返回值类型 model 类对象
<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 # 返回值类型 QuerySet[]
<5> order_by(*field): 对查询结果排序 # 调用者: QuerySet[], 返回值类型 QuerySet[]
<6> reverse(): 对查询结果反向排序 # 调用者: QuerySet[], 返回值类型 QuerySet[]
<8> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 # 调用者: QuerySet[], 返回值类型 int
<9> first(): 返回第一条记录 # 调用者: QuerySet[], 返回值类型 model 类对象
<10> last(): 返回最后一条记录 # 调用者: QuerySet[], 返回值类型 model 类对象
<11> exists(): 如果QuerySet包含数据,就返回True,否则返回False # 调用者: QuerySet[], 返回值类型 Bool
<12> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列
model的实例化对象,而是一个可迭代的字典序列 # 调用者: QuerySet[], 返回值类型 QuerySet[{}, {}]
<13> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
# 调用者: QuerySet[], 返回值类型 QuerySet[(), ()]
<14> distinct(): 从返回结果中剔除重复纪录
model.objects.all().filter().order_by().filter().reverse().first()
模糊查询
__gt : 大于
__lt : 小于
__gte : 大于等于
__lte : 小于等于
__in : 或 # __in=[1, 2, 3]
__range : 在...之间,顾头也顾尾 # __range=(1, 10)
__contains :模糊查询,区分大小写 # __contains="a"
__icontains :模糊查询,不区分大小写 # __contains="A"
__year : 查询年份
__month : 查询月份
__startswith : 以 ... 开头
- 示例
# 查询价格大于 12.1 的书
book_ret = Book.objects.filter(price__gt=12.1) # <QuerySet [<Book: 红楼梦>]>
# 查询价格小于 12.1 的书
book_ret = Book.objects.filter(price__lt=12.1) # <QuerySet [<Book: 水浒传>, <Book: 红楼梦>]>
# 查询价格为 12.1 或者 13.4 的书
book_ret = Book.objects.filter(price__in=[12.1, 13.4])
# 查询价格为 10.1 到 13.4 之间的书
book_ret = Book.objects.filter(price__range=(10.1, 13.4))
# 查询书名包含 “水” 的书籍
book_ret = Book.objects.filter(b_name__contains="水")
# 查询书名包含 “水” 的书籍
book_ret = Book.objects.filter(b_name__icontains="水")
删除表记录
# delete() 调用者: QuerySet对象 或者 model对象
# model对象
book_ret = Book.objects.get(id=1)
# model对象
ret = book_ret.delete()
print(ret) # (1, {'app03.Book': 1})
# QuerySet对象
book_ret = Book.objects.filter(id=1)
ret = book_ret.delete()
修改表记录
# update() 调用者: QuerySet对象
# 只能是 QuerySet 对象可以调用 update 方法, model对象不可以
book_ret = Book.objects.filter(id=6)
book_ret.update(price=11.1)
model 操作数据表( 多表操作)
多表关联
一对一映射
- 作者 和 作者详情信息
class Author(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32, null=False)
sex = models.CharField(max_length=4, choices=[("male", "男"), ("female", "女")], default='male')
age = models.SmallIntegerField()
class AuthorDetail(models.Model):
id = models.AutoField(primary_key=True)
address = models.CharField(max_length=32)
wife = models.CharField(max_length=32)
author_id = models.OneToOneField(to="Author", to_field="id", on_delete=models.CASCADE)
一对多、多对多映射
- 书 和 出版社 : 一本书只能有一个出版社,一个出版社可以有多本书
- 书 和 作者: 一本书可以有多个作者, 一个作者可以出多本书
class Book(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
# django 创建外键字段,会自动添加 _id 后缀
# 如 publish_id 在数据库中会成为 publish_id_id
publish_id = models.ForeignKey(to="Publish", to_field="id", on_delete=models.CASCADE)
author_id = models.ManyToManyField(to="Author")
class Publish(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
address = models.CharField(max_length=32)
多表增加
一对一映射:
-
本质上是 外键ForeignKey 加了 unique 约束的一对多映射
# way01: 方式一
author_ret = models.Author.objects.create(name="老舍", sex="male", age=67)
models.AuthorDetail.objects.create(address="北京", wife="胡洁清", author_id=author_ret) # 不加_id 后面赋值为 对象
# way02: 方式二
author_ret = models.Author.objects.create(name="杨绛", sex="female", age=105)
models.AuthorDetail.objects.create(address="北京", wife="钱钟书", author_id_id=author_ret.id) # 加 _id 后面赋值为 model对象.id
一对多映射
# way02: 方式一
pub_ret = models.Publish.objects.filter(name="清华大学出版社").first()
models.Book.objects.create(name="骆驼祥子", price=10.2, publish_id=pub_ret)
# way02: 方式二
pub_ret = models.Publish.objects.filter(name="清华大学出版社").first()
models.Book.objects.create(name="骆驼祥子", price=10.2, publish_id_id=pub_ret.id)
多对多映射
"""
将 骆驼祥子 这本书添加 老舍、冰心两个作者
思路: 1 找到具体的这本书,得到这本书的model对象
2 找到这本书的作者
3 通过这本书的model对象,找到这个 author_id 的字段,进行add添加
"""
ret_book = models.Book.objects.filter(name="骆驼祥子").first()
# 或者 ret_book = mdoels.Book.objects.create(name="骆驼祥子", price=10.2, publish_id_id=1)
ret_author1 = models.Author.objects.filter(name="老舍").first()
ret_author2 = models.Author.objects.filter(name="冰心").first()
ret_book.author_id.add(ret_author1, ret_author1)
多表查询
一对一映射
- 正向查询
# 由于 一对一映射的字段写在了作者详情表中 所以正向查询为 详情 ——> 作者
ret_author = models.AuthorDetail.objects.filter(wife="钱钟书").first()
author_name = ret_author.author_id.name
print(author_name)
- 反向查询
"""
思路: 找到作者(models对象)
models_obj.映射表的类名(全小写).字段名
"""
ret_author = models.Author.objects.filter(name="老舍").first()
author_address = ret_author.authordetail.address
print(author_address)
一对多映射
-
外键所在的表 向 另一个表查询为正向查询
-
正向查询
"""
找到 骆驼祥子 这本书的 出版社
字段名.属性
"""
ret_book = models.Book.objects.filter(name="骆驼祥子").first()
publish_name = ret_book.publish_id.name
publish_addr = ret_book.publish_id.address
print(publish_name, publish_addr)
- 反向查询
"""
通过 出版社 查看此出版社出的所有 书籍
表名_set.all()
"""
ret_book = models.Publish.objects.filter(name="清华大学出版社").first()
books = ret_book.book_set.all()
for book in books:
print(book.name)
多对多映射
- 正向查询 models_obj.字段.all( ) 或者 models.字段.filter( )
"""
查看 一本书 的 所有作者
"""
ret_book = models.Book.objects.filter(name="骆驼祥子").first()
authors = ret_book.author_id.all()
for author in authors:
print(author.name)
- 反向查询 model_obj.小写类名_set.all( )
"""
查询 作家老舍 出的所有书籍
"""
ret_book = models.Author.objects.filter(name="老舍").first()
books = ret_book.book_set.all()
for books in books:
print(books.name)
return HttpResponse("ok")
多表下滑线查询
- 正向查询按字段,反向查询按表名小写用来 ORM 引擎 join 哪张表
- 关联字段在哪个表下,从哪个表开始查询,哪个就是正向
一对一映射
- 正向查询
# 查询作者的住址
ret = models.Author.objects.values("name", "authordetail__address")
print(ret[0]["name"], ret[0]["authordetail__address"])
- 反向查询
# 查询作者的住址
ret = models.AuthorDetail.objects.values("author_id__name", "address")
print(ret)
一对多映射
- 正向查询
# 查询 book_01 这本书所在的出版社的名字
ret = models.Book.objects.filter(name="book01").values("publish_id__name")
print(ret) # <QuerySet [{'publish_id__name': '出版社1'}]>
- 反向查询
# 查询 book01 这本书所在的出版社的名字
ret = models.Publish.objects.filter(book__name="book01").values("name")
print(ret) # <QuerySet [{'name': '出版社1'}]>
多对多映射
- 正向查询
# 查询 book03 这本书的所有作者
ret = models.Book.objects.filter(name="book03").values("author_id__name")
# print(ret) # <QuerySet [{'author_id__name': '作者1'}, {'author_id__name': '作者2'}, {'author_id__name': '作者4'}]>
- 反向查询
# 查询 book03 这本书的所有作者
ret = models.Author.objects.filter(book__name="book03").values("name")
# print(ret) # <QuerySet [{'name': '作者1'}, {'name': '作者2'}, {'name': '作者4'}]>
多表跨表下划线查询
# 查询 出版社1 出的所有书、书籍的作者和、作者的地址
ret = models.Book.objects.filter(publish_id__name="出版社1").values("name", "author_id__name", "author_id__authordetail__address")
print(ret)
models 聚合查询 与 分组查询
聚合
- SQL --> model
select Count(price) from Book;
-- ==> models.Book.objects.all().aggregate(Avg('price'), Count('id'))
- model
from django.db.models import Avg, Count, Max, Min
# 计算所有书的平均价格
ret = models.Book.objects.all().aggregate(Avg('price'), Count('id'))
# 统计书的数量
ret = models.Book.objects.all().aggregate(Count('id'))
# 统计所有书中的最高价格
ret = models.Book.objects.all().aggregate(Max('price'))
# 统计所有书中的最低价格
ret = models.Book.objects.all().aggregate(Min('price'))
分组
- SQL
# 此 sql 不精准
select Count(author.id) from book_author
inner join
book
on
book_author.book_id = book.id
inner join
author
on
book_author_id.author_id = author.id
group by
book.name
- model
# 查询 每本书的 作者的 个数
# 此处以每本书进行分组 annotate() nums:可以不写
ret = models.Book.objects.annotate(nums=Count("author_id__name")).values("name", "nums")
print(ret)
# 查询 每本以 "book" 开头的书 的作者个数
ret = models.Book.objects.filter(name__startswith="book").annotate(nums=Count("author_id__name")).values("nums")
print(ret) # <QuerySet [{'nums': 2}, {'nums': 2}, {'nums': 3}, {'nums': 1}, {'nums': 1}]>
# 查询 每本书的价格超过20元的书的作者
ret = models.Book.objects.filter(price__gt=20).annotate(nums=Count("author_id__name")).values("name")
print(ret) # <QuerySet [{'name': 'book05'}]>
model: F 查询 和 Q 查询
- F 查询 和 Q 查询是为了解决两个字段之间比较问题
F 查询
- sql
select * from table where table.good > table.collection
- model
from django.db.models import F
# 查询 喜欢数 大于 收藏数的书籍 (虚构的)
ret = Book.objects.filter(good__gt=F("collection"))
Q 查询
-
filter() 方法中, 关键字参数都是 AND , 如果想执行 OR 语句, 可以使用 Q 查询
-
Q 查询是按位置传参, 当Q 查询和 其他查询混合时, 需要放在前面
Book.objects.filter(Q(name="book01")|Q(name="book02"), Q(price__gt=20)|Q(price__lt=40), id__lt=10) -
sql
select * from table where table.name="a" or table.name="b";
- model
from django.db.models import Q
# 查询一本书 书名为 book01 或者为 book02
ret = models.Book.objects.filter(Q(name="book01")|Q(name="book02"))
django 事务
# django 中的事务使用
from django.db import transaction
# 执行要么全成功 要么全失败
with transaction.atomic():
comment_obj = models.Comment.objects.create(article_id=int(article_id), user_id=request.user.pk,
content=content, parent_comment_id=pid)
models.Article.objects.filter(pk=article_id).update(comment_count=F("comment_count") + 1)
django 执行原生 mysql
# 第一种方式,类似 pymysql;
from django.db import connection
with connection.cursor() as cursor:
cursor.execute("select * from table_name")
# cursor.execute("select * from table_name where id=%s", [id])
row = cursor.fetchall()
print(row)
# 第二种方式
ret = models.Book.objects.raw('select * from table_name');
# ret = models.Book.objects.raw('select * from table_name where id=%s', [id]); 防止sql注入
Django views 视图层
请求对象
def index(request):
print(request)
print(request.GET.get("username"))
print(request.GET.get("password"))
print(request.POST.get("username"))
print(request.POST.get("password"))
print(request.MATE)
# url示例: /index?name=1&password=2
print(request.path) # /index
print(request.get_full_path) # /index?name=1&password=2
return HttpResponse("ok")
Django 组件-分页器
Django 组件-Form 表单
Ajax 提交表单数据
$('#register_btn').click(function () {
var formdata = new FormData();
formdata.append("username", $("#username").val());
formdata.append("password", $("#password").val());
formdata.append("re_password", $("#re_password").val());
formdata.append("email", $("#email").val());
// 上传文件
formdata.append("user_picture", $("#user_picture")[0].files[0]);
formdata.append("csrfmiddlewaretoken", $("[name='csrfmiddlewaretoken']").val());
$.ajax({
url: '/register/',
type: 'post',
data: formdata,
contentType: false,
processData: false,
success: function (data) {
console.log(data)
}
})
})
# 自定义表单
class UserRegisterForm(forms.Form):
username = forms.CharField(max_length=32, error_messages={"required": "该字段不能为空"})
password = forms.CharField(max_length=32, error_messages={"required": "该字段不能为空"})
re_password = forms.CharField(max_length=32, error_messages={"required": "该字段不能为空"})
email = forms.EmailField(error_messages={"required": "该字段不能为空", "invalid": "邮箱格式不正确"})
# 局部钩子函数
def clean_username(self):
user = self.cleaned_data.get("username")
ret = models.UserInfo.objects.filter(username=user).first()
if not ret:
return user
raise ValidationError("该用户已经存在!")
# 全局钩子函数
def clean(self):
password = self.cleaned_data.get("password")
re_password = self.cleaned_data.get("re_password")
if password == re_password:
return self.cleaned_data
else:
raise ValidationError("两次密码不一致")
# 视图函数
class Register(View):
def post(self, request):
form_obj = UserRegisterForm(request.POST)
if form_obj.is_valid():
cleaned_data = form_obj.cleaned_data
avatar = request.FILES.get('user_picture')
cleaned_data.pop('re_password')
if avatar:
cleaned_data['avatar'] = avatar
models.UserInfo.objects.create_user(**cleaned_data)
return JsonResponse("ok")
Django 组件-cookie 与 session
cookie
说明
Cookie:
1:key_value 结构, 类似一个字典
2:由服务器创建,通过响应发送到浏览器客户端,浏览器会保存 Cookie
3:当浏览器再次访问服务器时,会将 Cookie 发送给服务器,达到识别客户端的目的
Cookie 规范
Cookie大小上限为4KB
一个服务器最多在浏览器中保存 20 个 Cookie
一个浏览器最多保存300个 Cookie
Django 中使用 Cookie
设置 cookie
- set_cookie 需要 HttpResponse 中设置, set_cookie(key, value) 它来源于 HttpResponse的基类
def cookie_learn(request):
ret = HttpResponse("")
# ret = redirect("")
# ret = render(request, "index.html", local())
ret.set_cookies("key", "value")
return ret
- 示例:
# 示例 浏览器利用 cookie 记录上次登录时间
def learn_cookies(request):
now = datetime.now().strftime("%Y-%m-%d %H-%M-%S")
get_last_time = request.COOKIES.get("last_upload_time")
if get_last_time is not None:
ret = HttpResponse("上次登录时间:{}".format(get_last_time))
else:
ret = HttpResponse("第一次登陆")
ret.set_cookie("last_upload_time", now)
return ret
- set_cookie() 参数
def set_cookie(key, value='',
max_age=None,
expires=None,
path='/',
domain=None,
secure=False,
httponly=False,
samesite=None)
key, 键
value='', 值
max_age: None, 超时时间 # ret.set_cookie("key", "value", max_age=10)
expires=None, 超时时间 (IE 浏览器使用此参数) # ret.set_cookie("key", "value", expires=10)
path='/' , Cookie 的有效路径, '/' 为所有路径下都有效 '/' 为默认值 # ret.set_cookie("key", "value", path="/time") 只在 /time 路径下有效
### 以下不太明白 没有用过
domain=None, Cookie生效的域名
secure=False, https传输
httponly=False 只能http协议传输,无法被JavaScript获取(不是绝对,底层抓包可以获取到也可以被覆盖)
获取 COOKIE
- request.COOKIES.get("cookie_key")
def get_cookie(request):
cookie_value = request.COOKIE.get("cook_key")
return HttpResponse(cookie_value)
删除 Cookie
def delete_cookie(request):
ret = HttpResponse("delete_cookies")
ret.delete_cookie("cookie_key")
return ret
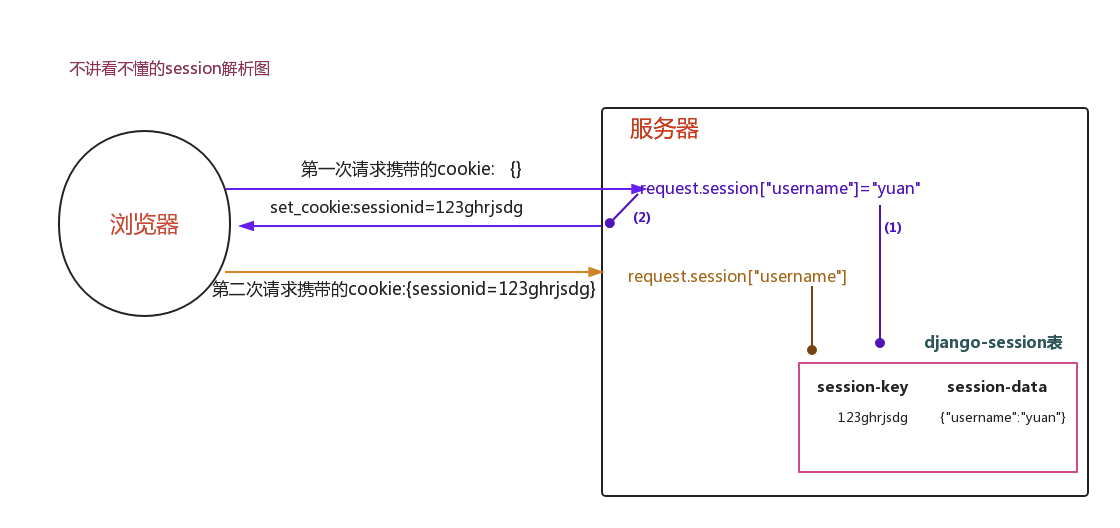
session
说明
session 是存在服务器中的;
django 的 session 存放在 django_session 表中;
mysql > desc django_session ;
+--------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+-------+
| session_key | varchar(40) | NO | PRI | NULL | |
| session_data | longtext | NO | | NULL | |
| expire_date | datetime(6) | NO | MUL | NULL | |
+--------------+-------------+------+-----+---------+-------+
sessino_key: 存放django 随机生成的字符串
session_data: 存放设置的session 键值; ps: {"key01": "value01", "key02": "value02"}
 h
h
Django 中 session 的使用
设置 session
- request.session['key'] = value
这一句代码干的事情:
1.django 内部会自动生成一个随机字符串
2.去 django_session 表中存储数据 键就是随机字符串 值是要保存的数据(中间件干的)
3.将生成好的随机字符串返回给客户端浏览器 浏览器保存键值对 sessionid 随机字符串
def set_session(request):
# 设置一个 session
request.session['key'] = "value"
return HttpResponse("set session")
获取 session
- request.session.get("key")
这一句代码干的事情:
1.django会自动取浏览器的 cookie, 查找 sessionid 键值对 获取随机字符串
2.拿着该随机字符串取 django_session 表中比对数据
3.如果比对上了 就将随机字符串对应的数据获取出来并封装到 request.session 供用户调用
def get_session(request):
value = request.session.get('key', None)
return HttpResponse("get session")
删除 session
# 删除当前会话的所有session数据
def del_cookie(request):
request.session.delete()
return = HttpResponse("delete cookies")
# 删除 session 的某数据
del request.session['key']
其他操作
# 获取 session 中数据
request.session['key']
request.session.get('key')
# 设置 session 数据
request.session['key'] = 'value'
requst.session.setdefault('key', 'value') # 存在则不设置
# 所有 键、值、键值对
request.session.keys()
request.session.values()
request.session.items()
# 会话 session 的 key
request.session.session_key
# 检查会话 session 的 key 在数据库中是否存在
request.session.exists("session_key")
# 删除当前会话的所有session数据
request.session.delele()
# 删除当前的会话数据并删除会话的 cookie
reqiest.session.flush()
# 设置会话Session和Cookie的超时时间
request.session.set_expiry(value)
* 如果value是个整数,session会在些秒数后失效。
* 如果value是个datatime或timedelta,session就会在这个时间后失效。
* 如果value是0,用户关闭浏览器session就会失效。
* 如果value是None,session会依赖全局session失效策略。
Session 在 django setting.py 的配置
1. 数据库Session
SESSION_ENGINE = 'django.contrib.sessions.backends.db' # 引擎(默认)
2. 缓存Session
SESSION_ENGINE = 'django.contrib.sessions.backends.cache' # 引擎
SESSION_CACHE_ALIAS = 'default' # 使用的缓存别名(默认内存缓存,也可以是memcache),此处别名依赖缓存的设置
3. 文件Session
SESSION_ENGINE = 'django.contrib.sessions.backends.file' # 引擎
SESSION_FILE_PATH = None # 缓存文件路径,如果为None,则使用tempfile模块获取一个临时地址tempfile.gettempdir()
4. 缓存+数据库
SESSION_ENGINE = 'django.contrib.sessions.backends.cached_db' # 引擎
5. 加密 Cookie Session
SESSION_ENGINE = 'django.contrib.sessions.backends.signed_cookies' # 引擎
其他公用设置项:
SESSION_COOKIE_NAME = "sessionid" # Session的cookie保存在浏览器上时的key,即:sessionid=随机字符串(默认)
SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径(默认)
SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名(默认)
SESSION_COOKIE_SECURE = False # 是否Https传输cookie(默认)
SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输(默认)
SESSION_COOKIE_AGE = 1209600 # Session的cookie失效日期(2周)(默认)
SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 是否关闭浏览器使得Session过期(默认)
SESSION_SAVE_EVERY_REQUEST = False # 是否每次请求都保存Session,默认修改之后才保存(默认)
Django 用户相关自带功能模块使用
auth 方法大全
模块导入
from django.contrib import auth
from . import models
创建用户
models.User.objects.create() # 创建普通用户,密码是明文
models.User.objects.createuser() # 创建普通用户,密码是密文,基本都用它
models.User.objects.createsuperuser() # 创建超级用户,邮箱需要给数据
校验用户名和密码是否正确
# 用户名和密码一个都不能少,该方法返回值,
# 当用户名和密码正确时,返回用户对象
# 不正确时返回 None
auth.authenticate(username=username, password=password)
保持登录状态
auth.login(request, user_obj) # 这一句执行之后 request.user 就能获取当前登录的用户对象
判断当前用户是否登录
request.user.is_authenticated() # 判断是否登录 bool值
request.user # 登录用户对象
校验用户是否登录
from django.contrib.auth.decorators import login_required
# 局部配置 # 优先使用局部配置
@login_required(login_url='/login/') # 没有登录则跳转到路由 /login/
def views(request):
return HttpResponse('ok')
# 全局配置 settings
# 配置文件中写下以下代码
LOGIN_URL = '/login/' # 没有登录则跳转到路由 /login/
@login_required
def views(request):
return HttpResponse('ok')
修改密码
request.user.check_password()
request.user.set_password(new_password)
request.user.save() # 保存是必要的过程
注销功能
auth.logout(request) # 删除对应的session值
auth 模块的扩展使用
from django.contrib.auth.models import User,AbstractUser
from django.db import models
class UserInfo(AbstractUser):
phone = models.BigIntegerField()
avatar = models.FileField()
# 扩展字段
# 配置文件
AUTH_USER_MODEL = '应用名.表名'
"""
django就会将userinfo表来替换auth_user表
并且之前auth模块所有的功能不变 参照的也是userinfo表
"""
Django 中间件和五个方法
七个 django 中间件
# 自定义中间件
django_project/ # 项目目录
app01/ # 应用
app02/
middleware/ # 创建中间件文件
my_middleware.py # 中间件 py 文件
django_project/ # 主配置文件
__init__.py
urls.py
wsgi.py
settings.py
static/ # 静态文件目录
templates/ # 模板文件目录
manage.py
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
# 自定义中间件
'middleware.my_middleware.中间件类01',
'middleware.my_middleware.中间件类02',
]
五个方法
中间件的使用
# 在此文件夹下编写自定义的中间件
# django_project/
# middleware/
# my_middleware.py
from django.utils.deprecation import MiddlewareMixin
class M1(MiddlewareMixin):
def process_request(self, request):
print('在进入视图函数前执行此函数')
def process_response(self, request, response):
print('在响应前执行此函数')
return response
class M2(MiddlewareMixin):
def process_request(self, request):
print('在进入视图函数前执行此函数')
def process_response(self, request, response):
print('在响应前执行此函数')
return response
# process_request 如果使用 return 会立刻跳入此 process_response 函数中
# process_response 必须要使用 return
中间件执行流程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号