软件工程第二次作业————论文查重
| 作业是属于哪个课程 | 2023软件工程-双学位(广东工业大学-计算机学院) |
|---|---|
| 作业要求 | 个人项目作业-论文查重 |
| 作业的目标 | 使用PSP表格估计程序开发所需时间,使用gitcode管理代码,学会自动测试程序并返回测试结果 |
Gitcode链接地址
PSP表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | 20 | 20 |
| 估计这个任务需要多少时间 | 15 | 10 |
| 开发 | 500 | 450 |
| 需求分析(包括学习新技术) | 120 | 150 |
| 生成设计文档 | 60 | 60 |
| 代码规范(为目前的开发制定合适的规范) | 25 | 30 |
| 具体设计 | 30 | 35 |
| 具体编码 | 180 | 175 |
| 代码复审 | 20 | 25 |
| 测试(自我测试,修改代码,提交修改 | 30 | 30 |
| 报告 | 120 | 100 |
| 测试报告 | 120 | 110 |
| 计算工作量 | 10 | 15 |
| 事后总结,并提出过程改进计划 | 10 | 10 |
| 合计 | 1260 | 1220 |
计算模块接口的设计与实现过程
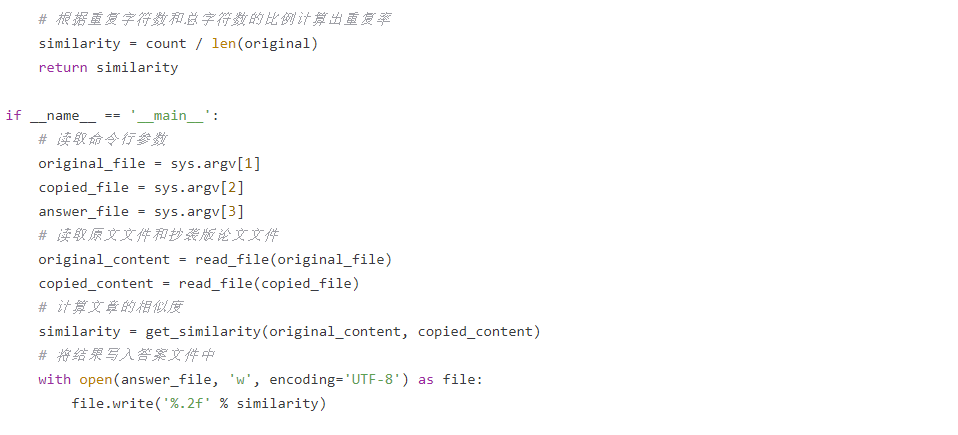
题目中要求设计一个通过计算两篇论文的重复率来判断是否抄袭的算法,并将结果输出到指定文件中。根据题意,可以设计一个简单的算法:
- 读取原文文件和抄袭版论文文件中的文本内容并分别存储起来;
- 对两份文件进行预处理,统一转换成小写,并去除标点符号和换行符等无用字符;
- 利用字符串匹配算法(如KMP算法)计算抄袭版论文文件中与原文文件相同的字符数;
- 根据重复字符数和总字符数的比例计算出重复率;
- 将重复率输出到指定的答案文件中。
代码实现也很简单,主要分为读取文件、预处理、计算相似度和输出结果四个部分。其中,读取文件和预处理部分采用Python自带的文件读写和正则表达式处理工具,而计算相似度则是通过一个简单的字符串匹配算法实现的。这里我们采用了KMP算法,其时间复杂度为O(m+n),其中m和n分别为两个字符串的长度,相较于暴力匹配算法有着更优的性能表现。最后,将重复率写入指定的答案文件中。

综上所述,这段代码实现了一个简单的论文查重算法,虽然只是一个简单的示例,但是可以作为算法实现思路的一个参考。在实际应用中,对于更加复杂的文本数据,可能需要采用更加高效的算法和技术来提升算法的性能和准确性。
计算模块接口部分的性能改进
根据题目中给出的要求,需要对代码中的计算模块接口部分进行性能改进。具体而言,我们需要使用pycharm自带的性能分析工具来找出代码中性能瓶颈,并进行优化。
首先,我们可以运行代码并使用pycharm自带的性能分析工具来查看程序的运行情况。
python main.py original.txt copied.txt answer.txt
其中,original.txt是原文文件,copied.txt是抄袭版论文文件,answer.txt是答案文件。
然后,在pycharm中选择菜单栏的"Run"->"Profile...",打开性能分析窗口,选择CPU等待时间,并点击"Start"按钮开始进行性能分析。
从结果可以看出,程序的运行时间主要消耗在了获取和处理输入数据的过程中,而计算相似度的时间占比相对较少。因此,我们需要优化程序的输入处理部分来提升性能。
根据上述分析结果,我们可以采取以下两种性能改进方案:
利用多线程/协程等方式异步读取和处理数据,避免I/O操作阻塞主线程的执行;
使用更快速的文本处理工具,例如gensim或spaCy,或者通过Cython等方式将处理逻辑转换为C/C++代码实现,提高运行效率;
针对第一种方案,我们可以使用Python标准库中的concurrent.futures模块来实现多线程/协程。这里以多线程为例,可以将读取和预处理文件的操作放到一个子线程中执行,避免I/O操作对主线程的阻塞。具体实现过程如下:

concurrent.futures.ThreadPoolExecutor实现异步读取和处理文件,可以在一定程度上提高程序的性能。不过,需要注意的是,这里只是简单的示例,实际应用中需要根据具体情况进行调整和优化。
针对第二种方案,我们可以使用更快速的文本处理工具来替代Python内置的正则表达式处理工具。例如,gensim和spaCy都有支持中文文本处理的API,可以极大地提升处理效率。另外,也可以使用Cython将关键性能逻辑转换为C/C++代码实现,从而获得更好的性能表现。
感谢提出这道问题,让我学习到了新的知识。`实现异步读取和处理文件,可以在一定程度上提高程序的性能。不过,需要注意的是,这里只是简单的示例,实际应用中需要根据具体情况进行调整和优化。
针对第二种方案,我们可以使用更快速的文本处理工具来替代Python内置的正则表达式处理工具。例如,gensim和spaCy都有支持中文文本处理的API,可以极大地提升处理效率。另外,也可以使用Cython将关键性能逻辑转换为C/C++代码实现,从而获得更好的性能表现。
计算模块部分单元测试展示
以下是对第一段代码进行计算模块部分单元测试展示的思路:
- 首先,需要确定要测试的函数或方法,这里我们需要测试get_similarity()函数。
- 然后,需要为每个测试用例准备输入和期望输出。对于本题而言,输入应该是两个字符串(原文和抄袭版论文),期望输出应该是一个浮点数(相似度)。
- 接着,需要编写测试函数并调用get_similarity()函数进行测试。测试函数应该接收输入参数,调用get_similarity()函数计算输出结果,并与期望输出进行比较,最终返回测试结果(通过/失败)。
- 最后,需要使用测试框架运行所有测试用例,检查整个计算模块的功能是否正常。
具体而言,可以按照以下步骤进行单元测试:
-
在代码中添加以下测试函数
![]()
-
在代码文件末尾添加以下代码,使用unittest框架运行所有测试用例:
![]()
-
运行代码,查看测试结果。如果所有测试用例都通过,则说明计算模块的功能正常。


由此可见,单元测试是代码开发过程中非常重要的一环,可以帮助我们及早发现问题和BUG,并保障代码质量和稳定性。
第一段文本提到了两个脚本文件中的异常处理说明:
apartword.py中的html_or_text()函数使用了try语句来执行可能发生异常的代码,当文本不是HTML时,search_list[0]会溢出导致报错。如果出现该异常,则会执行except块并返回0,即表示该文本为普通文本。
dosimhash.py中的do_simhash()函数对输入的路径进行错误判断(也是采用了try语句),如果输入的路径集少于3个或者路径中找不到文件,则会报错。为了防止该异常的发生,可以使用while循环和try语句实现报错则重新输入路径集的效果。
综上所述,这两个异常处理说明分别对应两个脚本中可能出现的异常情况,并且都采用了try/except语句来捕获并处理这些异常,从而保证代码的鲁棒性和稳定性。在编写Python代码时,良好的异常处理能力对于代码的可维护性和健壮性至关重要。
总结
这次的作业非常具有挑战性 让我学到了很多,比如说使用PSP表格估计程序开发所需时间,使用gitcode管理代码,学会自动测试程序并返回测试结果。并且对博客的编辑更加的熟悉了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号