论文速读 | 2025年11月
FLOWER: Democratizing Generalist Robot Policies with Efficient Vision-Language-Action Flow Policies
- CORL 2025
- project
Object-Centric Latent Action Learning
- AAAI 2026 dunnolab
Pi0.6: A VLA that Learns from from Experience
- Physical intelligence
- 2025.11
- project
- 人类学习组装的三个阶段
- teach the basiscs: what are the common mistakes.eg
- coach you:correcting mistakes that you make when you do it yourself.
- practice makes perfect.
- robotic learning
- training the robot on demonstrations. (Current research)
- not reliable
- 提出一种RECAP(RL with Experience and Corrections via Advantage-conditioned Policies) that 同时实现了这三步:training the robot with demonstrations, coaching it with corrections ,and enabling it to improve from automous experience.
- pi0.6采用RECAP训练,并在下列复杂任务上测试:
- making espresso drinks
- assembing boxes
- folding diverse laundry items.
- training the robot on demonstrations. (Current research)
- why is imitation not enough?
-监督学习方式在LLM取得了成功,但对于robot leearning 却表现struggling.因为模仿学习训练的VLA必定会犯一些小的错误,而由于它是和真实物理世界做交互,这将导致agent到达一个它在训练集中没有见过的situation,继而会更可能犯错,这种累积误差将导致失败。对于输出是静态的AI系统如LLM并不是大问题,它适用于模型作为控制策略并与外界持续交互的情况。这意味着VLA有时成功完成任务较为容易,但要让他们可靠地成功却相当困难。- 如果我们利用VLA自身行为的额外数据,就能解决这个问题。即允许VLA反复练习来消除累积误差。关键在于用什么作为这类经验的真实标签?实现从经验中学习的关键在于从糟糕的经验数据中提取有效的训练信号。
- Coaching with correctins and practicing with reinforcement
-RECAP支持两种从糟糕经验数据中得到好的训练信号的方法- Coaching: 需要专家级人类遥操作员在robotc policy运行时,观察其行为,在出现错误时,立即切换现有policy到人工操作,进行纠正。
- 这种纠正措施的监督质量取决于人是否能准确把握干预时机并真正提供高质量的纠正。 为了让roboit达到最佳性能——快速、可靠且始终如一地完成任务--机器人需要自主学习,即练习(practice)和强化(reinforcement)
- Reinforcement: 关键在于credit assignment,哪个动作导致结果变好或变差。Recap为了解决credit assignment问题选择训练一个value function: a model that predicts how good a particular situation is relative to others.

- 在已经训练好value function的基础上,选择一种scalable and can be used with large VLA的方法得到一个更好的policy(policy extraction).In RECAP, we condition the policy(VLA) on the change in value,使用所有数据训练(包含坏的和好的),并且告诉VLA哪些是好的/坏的. the change in value in RL is referred to as the advantage.执行时则告诉policy to perform hign-advantage actions, resulting in a policyt that is much better that the data it was trained on.
- Coaching: 需要专家级人类遥操作员在robotc policy运行时,观察其行为,在出现错误时,立即切换现有policy到人工操作,进行纠正。
- Towards real-world tasks.

- 训练过程
- pi_0.5 3b
- pi_0.6 5b same training pipeline with pi_0.5, support heterogeneous prompts and conditioning information.
- pi_0.6* offline RL pretrain
- pi_0.6* offline RL + SFT:继续在特定类型任务上使用演示数据微调
- final pi_0.6*: offline RL +sft+RL:继续使用从机器人收集的额外数据,通过RL进一步训练该模型,训练过程中既会提供专家知道来纠正重大错误,也会利用奖励反馈来改进自主操作经验。
- excellent performance
即使对于目前最好的 VLA 模型来说,这些任务阶段中的每一个阶段都是具有挑战性的,而 π * 0.6 可以以超过 90% 的成功率完成这些阶段
Diffusion guidance is a controllable policy improvement operator
- Sergy Levine
- ICLR2026 underreview
Knowledge insulating vision-language-action models: Train fast, run fast, generalize better.
- Physical Intelligence
- 2025.5
- 类比:VLM是视觉皮层(siglib)+前额叶皮层(LLM),需要相应的运动皮层(Action head/expert)
- 关注点:如何增强 VLM,使其能够产生连续的动作输出,并最大限度地继承网络规模预训练的所有能力?
- 第一代:RT-2和OPENVLA,训练 VLA 将动作输出为标记化的数字,将每个机械臂关节角度离散化到固定大小的区间中,并为每个区间分配一个标记,就像问答问题中答案由数字组成一样。(不适用高频、精确、流畅的运动,不适合训练模型,对精确任务来说过于粗糙,并且运行速度非常慢。
- 第二代:pi_0,通过在 VLA 训练过程中添加新的神经模块来生成连续输出,通常采用扩散或流匹配等连续生成建模技术。这些新模块以动作专家或动作头的形式出现,它们既可以关注 VLM 主干中的表征,也可以专门用于连续运动控制。(但在 VLA 微调过程中向模型添加新的运动控制权重会导致复杂的学习动态,这可能会损害 VLM 的内部表征。本质上,以这种粗糙的方式将这个“运动皮层”嫁接到 VLM 上可能会导致一种“遗忘”,显著减慢训练速度,并损害模型最终的语言理解能力。)
-第三代:pi_0.5+KI,利用 FAST 标记化的离散化动作来微调 VLM 主干网络,从而快速学习高质量的表示;同时,调整动作专家,使其能够生成连续动作,而无需将其梯度传播回 VLM 主干网络。训练完成后,动作专家可以通过流匹配生成流畅的连续动作,而离散化的动作则被丢弃。
- 预训练的 VLM 模型本身就能够很好地处理语言输入。然而,来自动作专家的梯度现在严重干扰了模型处理语言的能力,导致模型首先关注其他相关性。
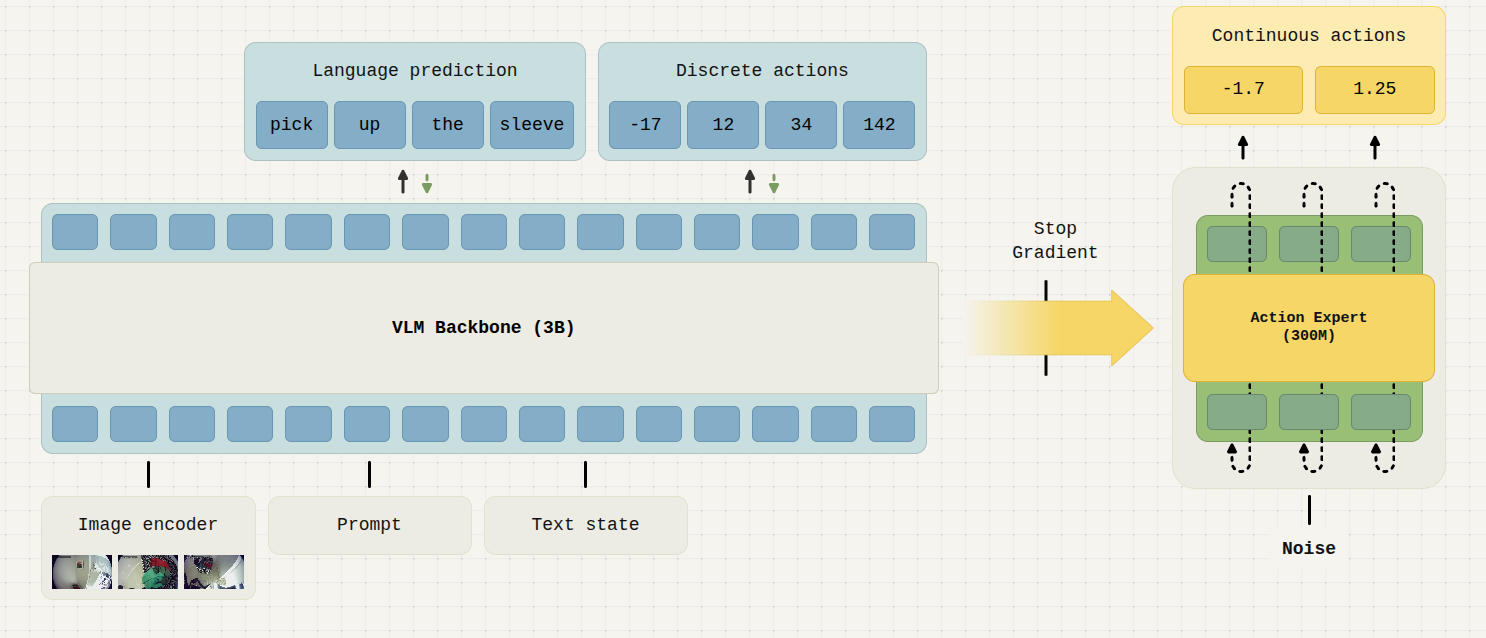
- 训练时阻止action expert 梯度影响VLM backbone.支持VLM输出Fast-tokenized token(离散动作),并将其作为训练目标之一。这同样讲帮助加速flowmatching action expert生成连续动作
- 用以下方式训练 VLM 骨干网络:π 0-FAST token。 这样,我们就为 VLM 主干网络配备了运动控制的表征,而动作专家无需任何额外操作即可使用这些表征。 不得不反向传播其训练信号,这会破坏骨干网络。π 0-FAST 动作标记使模型能够更快地获取运动表征,并且交叉熵损失对 VLM 主干的预训练知识的干扰要小得多。
π0.5: a VLA with Open-World Generalization
- Physical Intelligence
- 2025.4
- 重点在于异构数据的协同训练:协同训练的概念很简单:由于视觉语言模型(VLA)源自通用视觉语言模型(VLM),因此可以使用包含动作、图像、文本和其他多模态标注(例如边界框)任意组合的示例进行训练。这包括通用的多模态任务,例如图像描述、视觉问答或目标检测,以及面向机器人的任务,例如带有动作的机器人演示,以及“高级”机器人示例,这些示例由带有相应语义行为标签的观察结果组成(例如,对一张未整理的床的观察,并标注“拿起枕头”)。我们还包括“口头指令”演示,其中人通过逐步指导机器人完成复杂任务(使用自然语言)。该模型既可以对要执行的下一个语义步骤进行高级推理(类似于思维链推理),也可以进行低级预测,从而向机器人的关节输出运动指令:
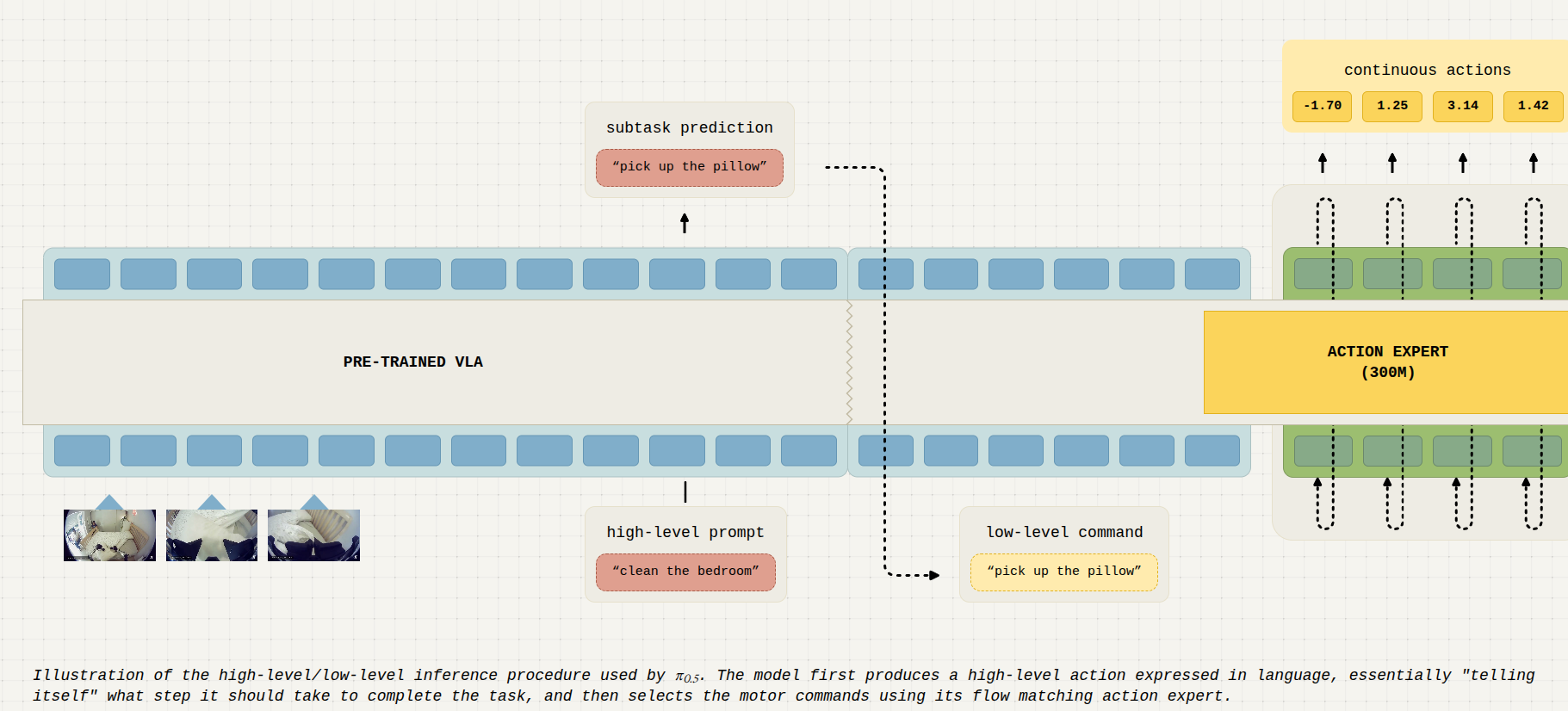
- 伪代码
Real-Time Action Chunking with Large Model
- Physical Intelligence
- 2025.6
- 在 π 0 、 π 0 -FAST 和 π 0.5 中,我们没有采用实时策略。我们同步执行动作,这意味着我们会完成一个动作块的执行,等待模型推理完成,然后再开始执行下一个动作块。这样,机器人每次执行动作块时都是从静止状态开始,从而避免了运动过程中切换动作块所带来的问题(如果新数据块与前一个数据块存在显著差异(这种情况很常见),切换到新数据块会导致灾难性的后果。)
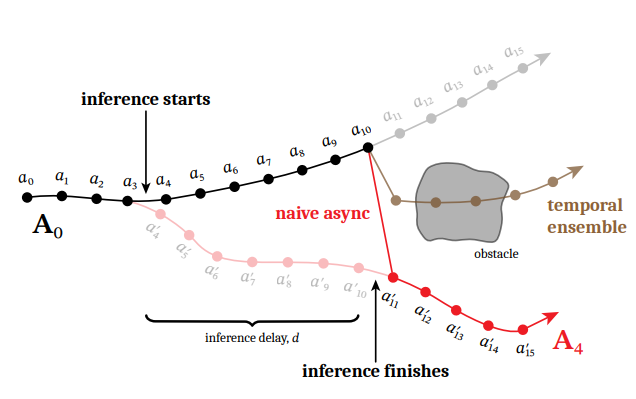
- 然而,这种方法会在动作块之间引入停顿,而这些停顿仍然是有害的——训练数据中并没有这些停顿。更不用说:它们会降低速度,影响美观,并且会阻碍我们扩展模型规模。
- 自然而然地,我们想到利用overlapping timesteps.一个优秀的实时算法应该生成一个与这些重叠动作一致的新数据块,同时保持模型对新信息的反应能力和做出智能决策的能力。
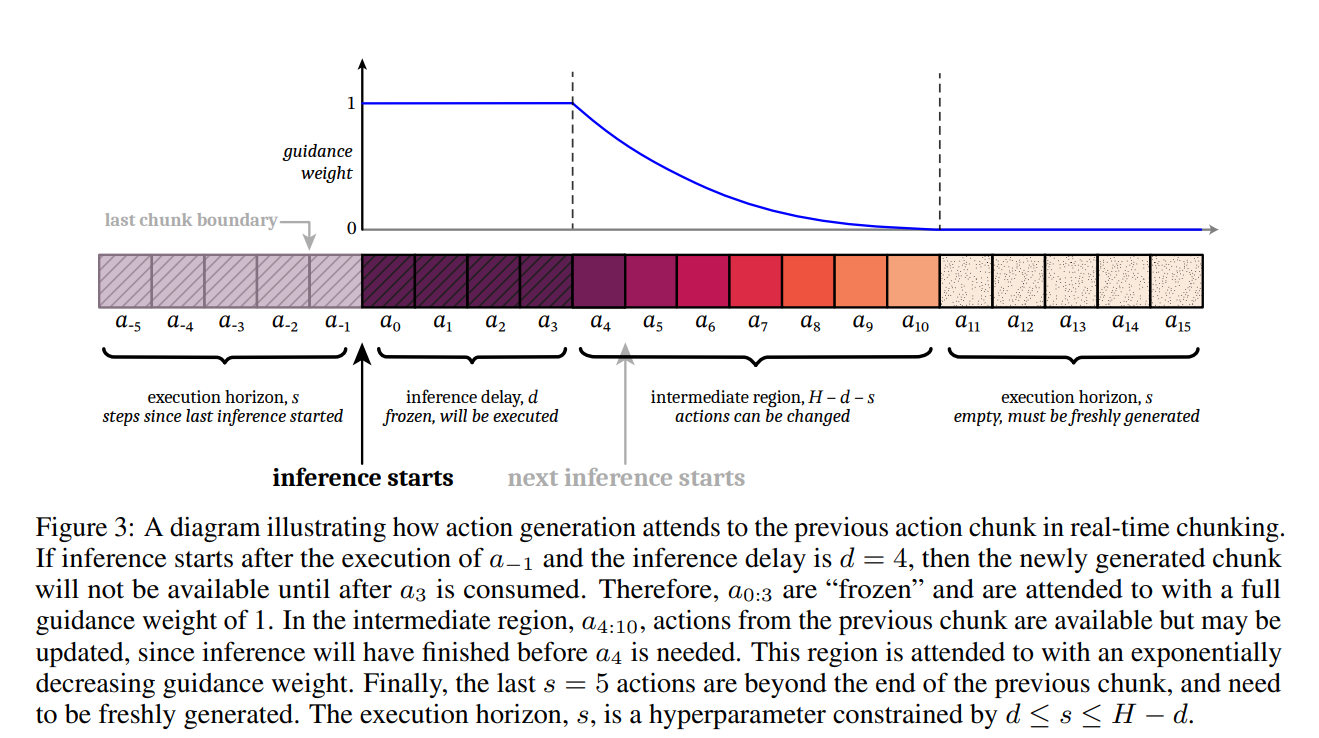
- 该算法修改flow matching,添加提出的“部分注意力思想”,可以在不改变训练时间的情况下解决块一致性问题
Flow matching policy gradients
Simple policy optimization.
- ICML2025
Efficient online reinforcement learning with offline data
- pi_0.6 RL训练的数据策略
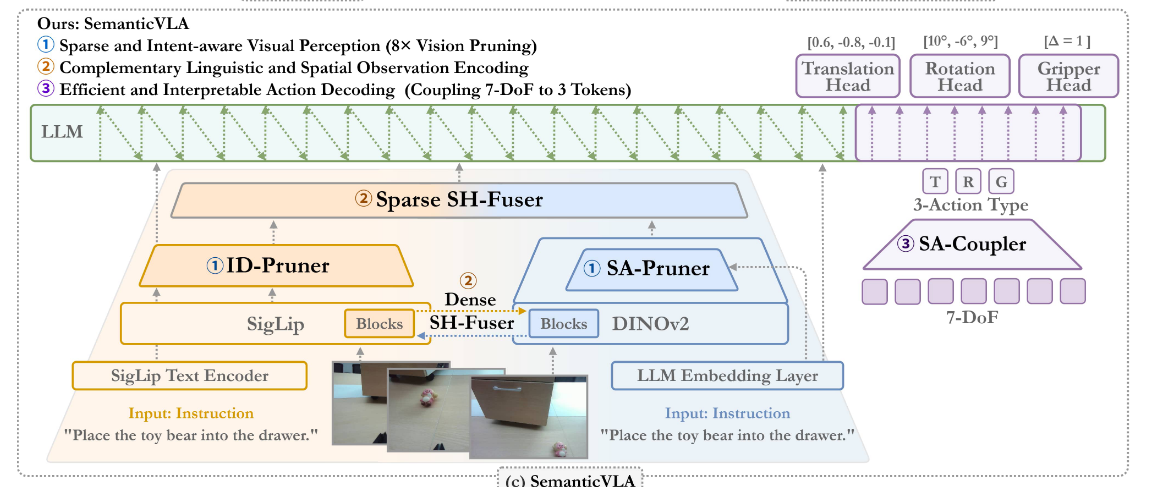
SemanticVLA: Semantic-Aligned Sparsification and Enhancement for Efficient Robotic Manipulation
- aaai 2026
- 加强版Film,鼓励vision encoder关注与文本相关的内容,进行视觉剪枝,降低训练成本,相比于Openvla-oft,推理延迟降低2.7倍,视觉token压缩8~16倍,动作token压缩为原来的3/7,提升吞吐量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号