RLChina2024 | 汪军 LLM and AI Agents: A Roadmap and Vision towards AGI
本文记录此次报告的key point(个人向)
llm时代的几点difficulity

Inference-time computation scalling
-
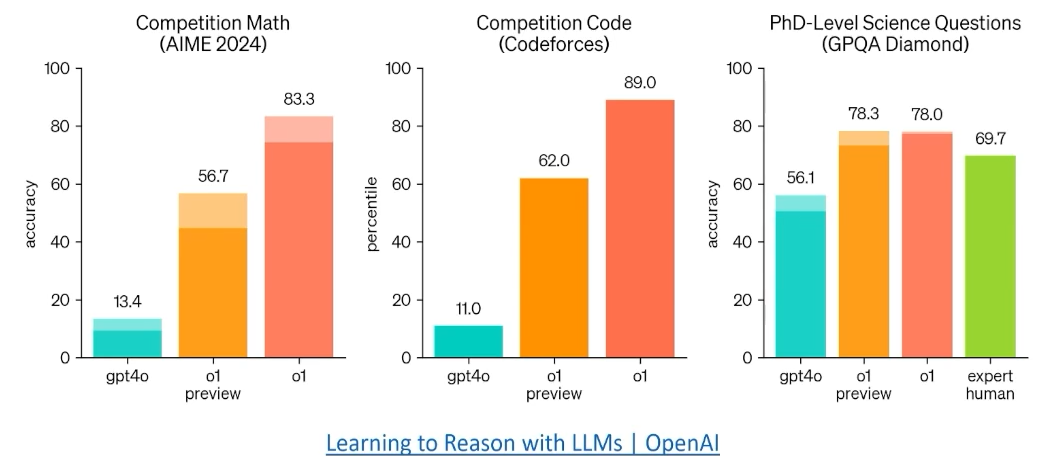
OpenAI o1 利用RL来显式整合inference期间推理的step(inference-time computation) (从predicte next-token范式到RL解决问题范式)
-
predict next token是监督学习,受限于训练数据集水平。但可以将其用于理解规则,从而超出数据集水平。(将数据作为world model而不是拟合)
-
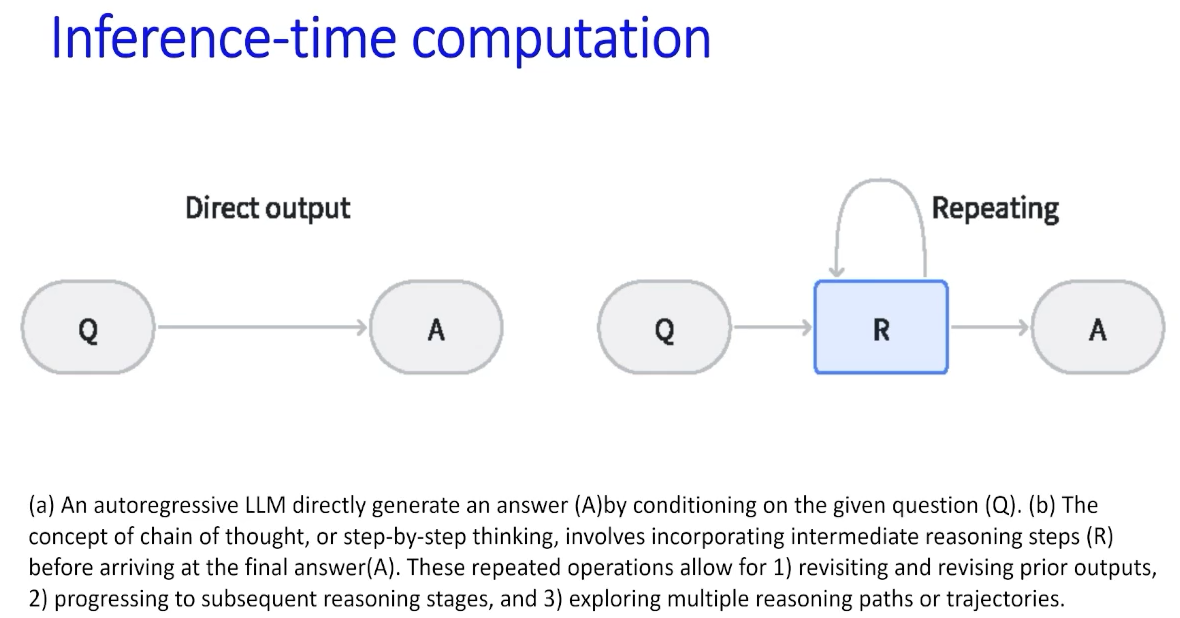
自回归LLM对某些问题决策计算量不够
-
从未整理的书籍文本中进行策略学习:Policy Learning from Books: Playing Football with Textual Tutorials, NIPS2024
- 使用MDP决策建模推理
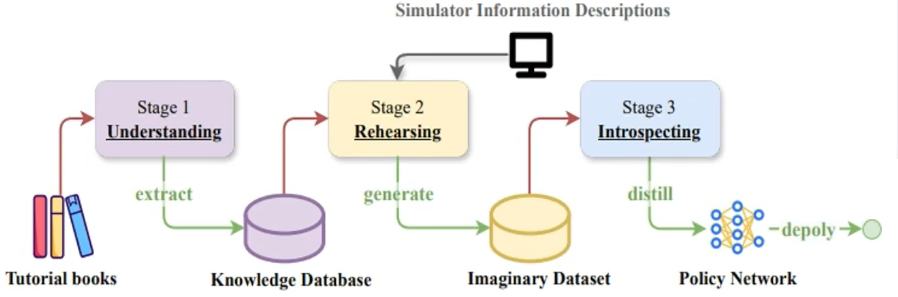
- 使用MDP决策建模推理
-
基于PRM的Non-autoregressive reasoning
- 1)sampling multiple reasoning trajectories
-
- 在潜在推理路径结构上执行蒙特卡洛搜索
- 3)结合上面两种方法
conclusion


 浙公网安备 33010602011771号
浙公网安备 33010602011771号