【论文阅读】Transformer-XL
Transformer-xl: Attentive language models beyond a fixed-length context.ACL 2019
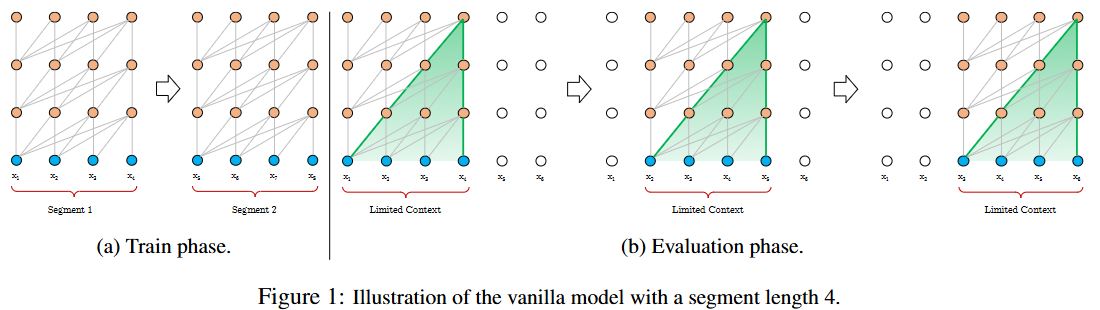
其是对Transformer架构的改造。
Transformer-XL 使学习依赖性超过固定长度而不破坏时间连贯性(450% longer than vanilla Transformers).它由段级递归机制和新颖的位置编码方案组成.
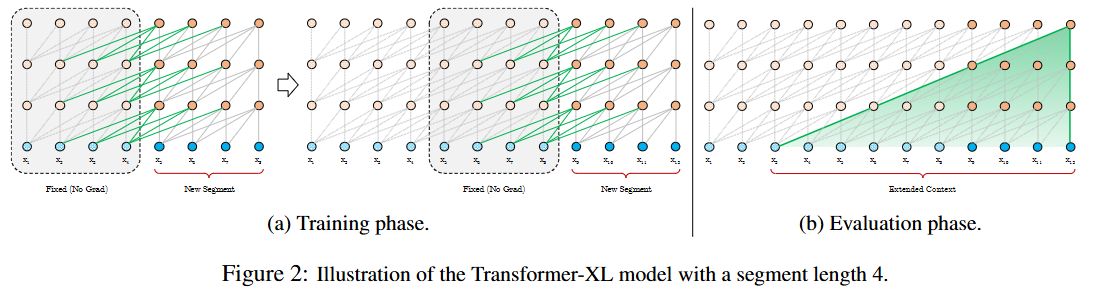
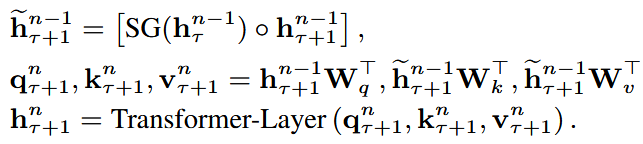
其中函数SG(.)表示stop-gradient,符号[\(h_{\mu} \dot h_v\)]表示两个隐藏层沿着length dimension级联,W表示模型参数。
另外,为了保证在重用state信息时位置编码信息的连续性(vanilla transformer中绝对位置编码在segment复用时会出现位置相同问题),提出了相对位置编码(Relative Positional Encodings)
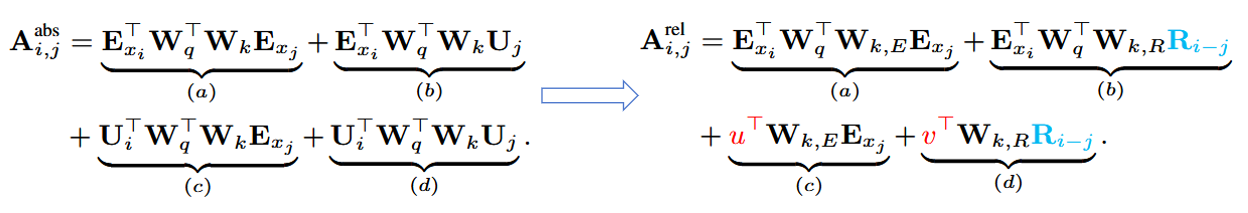
上式中做了如下改动:将所有绝对位置编码\(U_j\)替代为相对距离(正弦编码矩阵)\(R_{i-j}\);由于所有的query位置的query向量都相同,因此不同词之间的注意力偏差与query 位置无关,所以使用可训练参数\(u\in R^d\)替代query\(U^T_i W^T_q\);将权重矩阵W分为基于内容的key向量\(W_{k,E}\)和基于位置的key向量\(W_{k,R}\)
综合上述segment-level recurrence mechanism和relitive positional encoding scheme,我们总结了N层的带一个注意力头的Transformer-XL,对于n=1,...,N:

其中\(h^0_{\tau}:=E_{s_{\tau}}\)被定义为词嵌入序列。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号