正则表达式
正则表达式是一种很小的编程语言
字符匹配(普通字符, 元字符)
普通字符;
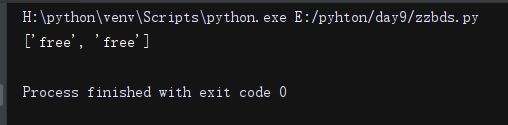
import re #在字符串里找 free li = re.findall('free', 'sjfljaslfreesdfjasdjflafreeefjlf') print(li)
元字符: . ^ $ * + ? {} [] | () \
import re
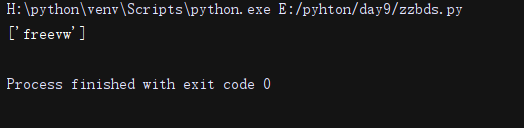
#free.w###.通配任意一个字符
li = re.findall('free.w', 'freevasdaswsdsd')
print(li)
import re
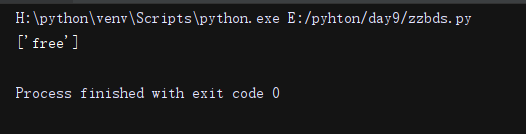
li = re.findall('^free', 'freevwdaswsdsd')#'^'符号表示free在最前面才可以被匹配。
print(li)
import re
li = re.findall('free$', 'wdaswsdsdfree')#$符号表示free在字符串的最后面才可以匹配。
print(li)
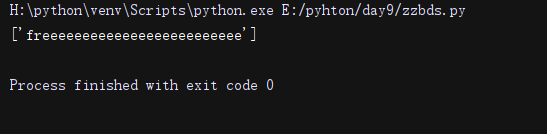
import re
li = re.findall('free*', 'wdaswsdsdfreeeeeeeeeeeeeeeeeeeeeeeee')# *号匹配e 零到多次 。
print(li)
import re
li = re.findall('free*', 'wdaswsdsdfre')
print(li)
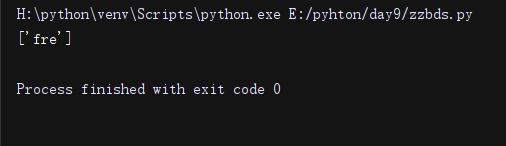
import re
li = re.findall('free+', 'wdaswsdsdfree')#+号匹配 1到多次
print(li)
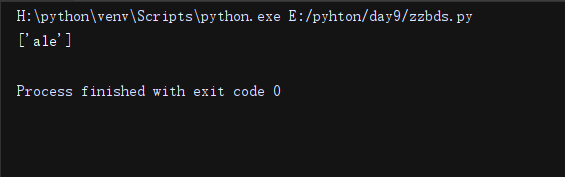
import re
li = re.findall('alex?', 'wwwale')
print(li)
大括号
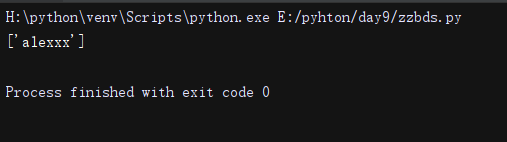
import re
li = re.findall('alex{3}', 'wwwalexxxx')#匹配3个x
print(li)
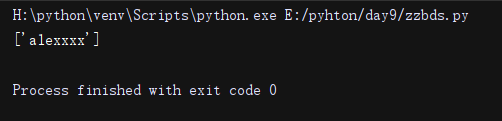
import re
li = re.findall('alex{3,5}', 'wwwalexxxx')#匹配3到5之间个x
print(li)
中括号
import re
li = re.findall('a[bc]d', 'wwwacd')#【b,c】是 或的关系,匹配abd、acd
print(li)
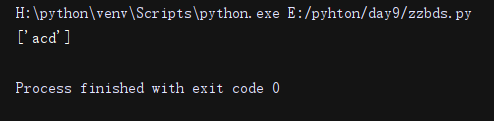
import re
li = re.findall('a[.]d', 'wwwa.d') #元字符. 在字符集里失去意义,回归原来的普通字符
print(li)
import re
li = re.findall('[a-z]', 'wwwa.d')
print(li)

import re
li = re.findall('[^a-z]', '1wwwa.d') #^在这里是非的意思
print(li)
\:
反斜杠后边跟元字符去除特殊功能。
反斜杠后面跟普通字符实现特殊功能。
引用序号对应的字组所匹配的字符串。
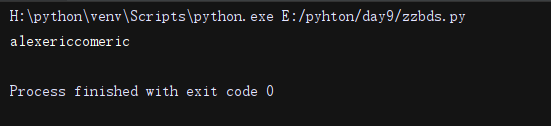
import re
li = re.search(r"(alex)(eric)com\2", "alexericcomeric").group()
print(li)
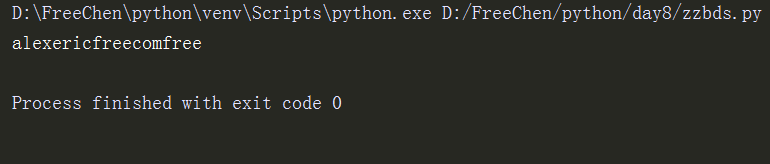
li = re.search(r"(alex)(eric)(free)com\3", "alexericfreecomfreessssss").group()# \1表示第一个括号(alex)需要匹配两次,\2表示第二个括号(eric)需要匹配两次,\3表示第三个括号(eric)需要匹配两次,而且一定是紧跟其后,如\1 , alexericfreeercomalex
以此类推
print(li)

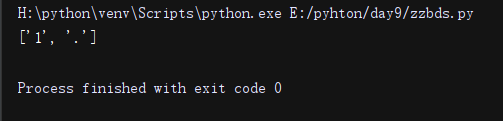
import re
li = re.findall('[\s]', '13333 wwwa.d')
print(li)
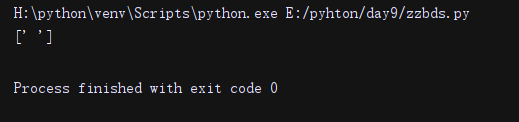
():

import re
li = re.findall(r'(ab)*', 'aba')
print(li)
import re
li = re.findall(r'(ab)*', 'ab') #*号表示,匹配无限个字符,以空字符输出。
print(li)
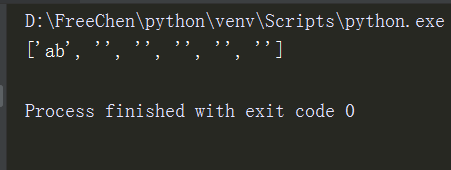
li2= re.search('(ab)*','aba').group()#*号在这里没有效果,没有元字符的特殊功能。
print(li2)
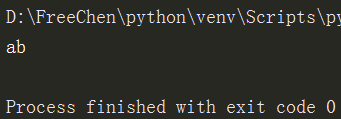
li3= re.match('(ab)*','aba').group()#*号在这里没有效果,没有元字符的特殊功能,
print(li3)
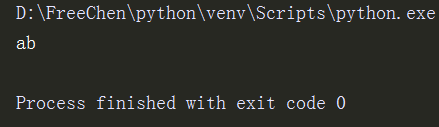
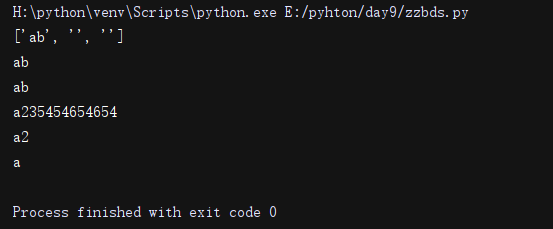
li4= re.search(r'a(\d+)','a235454654654b').group() #贪婪模式,匹配数字
print(li4)
li5= re.search(r'a(\d+?)','a235454654654b').group() #非贪婪模式,只匹配一个数字
print(li5)
li6= re.search(r'a(\d*?)','a235454654654b').group()#只匹配一个a
print(li6)
\b:
import re
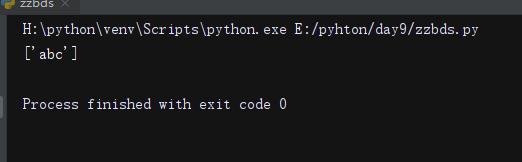
li =re.findall(r'\babc\b',"abc sdsadsa") #匹配单词边界。匹配特殊字符,空格 *号等等。r表示原生字符串
print(li)

import re
li =re.search('com', "COM" , re.I ).group() #使匹配不敏感大小写
print(li)


sub subn:

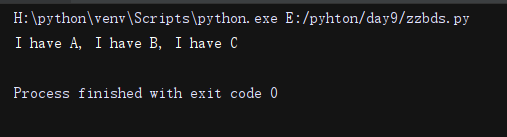
import re
li = re.sub('g.t', 'have', 'I get A, I got B, I gut C')#匹配g.t 替换成have
print(li)
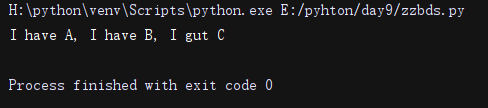
import re
li = re.sub('g.t', 'have', 'I get A, I got B, I gut C', 2)#匹配g.t 替换成have,替换两个
print(li)
import re
li = re.subn('g.t', 'have', 'I get A, I got B, I gut C')#匹配g.t 替换成have,并且返回被替换的次数。
print(li)
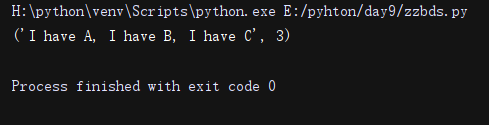
re.compile

import re
p = re.compile(r'\d+')
r = p.split('one1two2three3four4')
print(r)
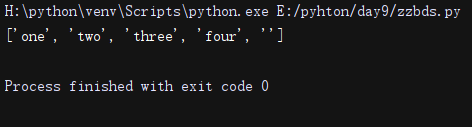
li = re.findall(r'www.(baidu|laonanhai).com', 'sdf www.baidu.com')#优先捕获组的内容
print(li)
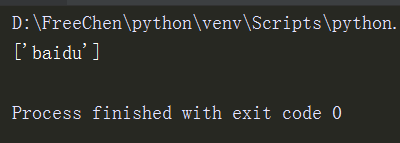
li = re.findall(r'www.(?:baidu|laonanhai).com', 'sdf www.baidu.com')#优先捕获组的内容,组里的前面加上?:把优先捕获组的内容去掉。
print(li)
正则表达式补充;
一、大纲
import re
#从头匹配
re.match() #简单 ; 分组
re.search()
#浏览全部字符串,匹配第一个符合规则的字符串
re.findall()
#将匹配到的所有内容,放置在一个列表中。
re.finditer()
#
re.split()
re.sub()
1.match 无分组:
import re # re.match()无分组实例: origin = 'hello alex bcd alex lge alex acd 19' r = re.match('h\w+', origin) print(r.group()) #获取匹配到的所有结果 print(r.groups()) #获取模型中匹配到的分组结果 print(r.groupdict()) #获取模型中匹配到的分组结果
2. match 有分组
origin = 'hello alex bcd alex lge alex acd 19' r = re.match('h(\w+)', origin) print(r.group()) #获取匹配到的所有结果 print(r.groups()) #获取模型中匹配到的分组结果 print(r.groupdict()) #获取模型中匹配到的分组中所有执行了key的组
2.1 match 有分组
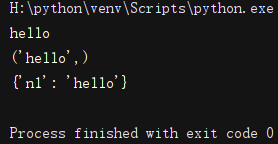
# re.match()有分组实例: origin = 'hello alex bcd alex lge alex acd 19' r = re.match("(?P<n1>hello)", origin) print(r.group()) #获取匹配到的所有结果 print(r.groups()) #获取模型中匹配到的分组结果 print(r.groupdict()) #获取模型中匹配到的分组中所有执行了key的组
findall
#findall 有分组
import re
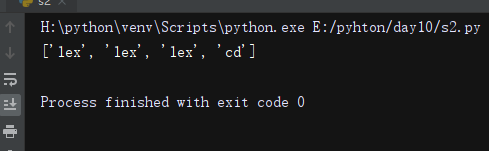
origin = 'hello alex bcd alex lge alex acd 19'
r = re.findall('a(\w+)',origin) #groups ,只拿出组里的内容
print(r)
#findall 有分组
import re
origin = 'hello alex bcd alex lge alex acd 19'
r = re.findall('(a)((\w+)(e))(x)',origin) #groups ,只拿出组里的内容
print(r)

re.slit():
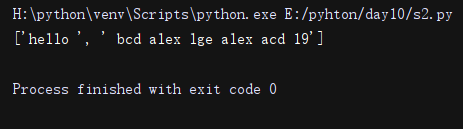
origin = 'hello alex bcd alex lge alex acd 19'
n = re.split('a\w+', origin)

origin = 'hello alex bcd alex lge alex acd 19'
n = re.split('a\w+', origin, 1) #只分割一次
print(n)
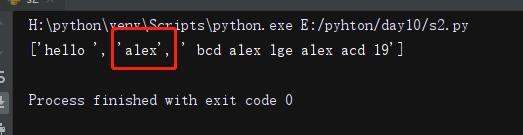
origin = 'hello alex bcd alex lge alex acd 19'
n = re.split('(a\w+'), origin, 1) #加上组,能获取到被分割的本身的字符串、
print(n)
计算机:
import re #计算器 def f1(ex): return 1 origin = '1-2*3*((5*68)+(88/2*(44+88)))' while True: print(origin) n = re.split('\(([^()]+)\)', origin, 1) if len(n) == 3: before = n[0] content = n[1] after = n[2] r = f1(content) new_origin = before + str(r) + after origin = new_origin else: final = f1(1+4) print(final) break
#!usr/bin/env python # -*- coding:utf-8 -*- #findall 有分组 import re #计算器 def f1(*ex): # i1 =[] # total = 0 # i1 = re.split('(\*|\+|/|-)',ex ) num = eval(*ex) return num origin = input('请输入算数题目:') while True: n = re.split('\(([^()]+)\)', origin, 1) if len(n) == 3: before = n[0] content = n[1] after = n[2]
#上面三行可以这么写:before,content,after = n r = f1(content) new_origin = before + str(r) + after origin = new_origin else: jieguo = f1(origin) print(jieguo) break
正则表达是☞sub
sub替换
import re ret = '45dfs6sdfasdf4sdfa61dfa' new_str = re.sub('\d+','KKK', ret ,1 ) #('\d+',#匹配数字。'KKK',#匹配成功后替换成KKK。 ret ,#被替换的字符串。1#替换的次数,默认是替换全部。) print(new_str)
subn 替换
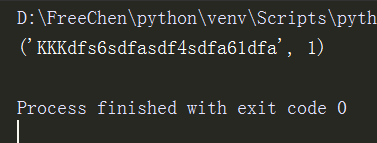
import re ret = '45dfs6sdfasdf4sdfa61dfa' new_str = re.subn('\d+','KKK', ret ,1 ) #('\d+',#匹配数字。'KKK',#匹配成功后替换成KKK。 ret , # #被替换的字符串。1#替换的次数,默认是替换全部。)返回值是元组,且返回被替换的次数。 print(new_str)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号