
T-SQL切割字符串方法小结
T-SQL切割字符串方法小结,只有表值函数那个是自己的思想,其它都是来源于网络的思想,请大家不要笑话,嘻嘻~网上大牛太多,这点东西虽然上不了台面,但是也算是自己的一个学习吧,能够对一个人有用也行。再不济也可以作为自己的参考笔记。
一、拼接动态SQL方法:
1. 把逗号替换为 ') insert into temptab values(' 讲逗号间的值截出来存入表变量,但是这种有些局限性
CREATE PROCEDURE usp_SplitStr2 @str varchar(8000),@split_Del VARCHAR(10) WITH ENCRYPTION,EXECUTE AS OWNER AS BEGIN DECLARE @strSql varchar(8000) SELECT @strSql='DECLARE @temptab TABLE(id INT IDENTITY(1,1),col varchar(8000)) insert into @temptab(col) values('''+REPLACE(@str,@split_Del,''') insert into @temptab(col) values(''')+''') SELECT col FROM @temptab' exec (@strSql) END -----------测试------- DECLARE @temptab TABLE(id INT IDENTITY(1,1),col varchar(8000)) INSERT INTO @temptab(col) EXEC usp_SplitStr2 'a,b,c,d',',' SELECT * FROM @temptab
----------测试-----
Result:
2. 把逗号替换为 UNION ALL 的方法,类似第一种方法
/*巧生成 UNION ALL SELECT */ declare @str varchar(24)='a,b,c,d,e,f,g,h,i,j,kbac' declare @sql varchar(max)='SELECT ''' ----为 a 加 前一个 单引号 set @sql+=REPLACE(@str,',',''' Union all SELECT ''')+'''' ---为 最后一个 加 单引号 EXEC (@SQL)
二、 利用 SQLServer 的 XQuery node,value方法
declare @str varchar(24)='a,b,c,d,e,f,g,h,j,kafad',@split char(1)=','
SELECT B.id
FROM (
SELECT [value] = CONVERT(XML , '<v>' + REPLACE(@str , @split , '</v><v>')
+ '</v>')
) A
OUTER APPLY ( SELECT id = N.v.value('.' , 'varchar(100)')
FROM A.[value].nodes('/v') N ( v )
) B
依据浅显的理解,自己写了个 SP 去拆分(因为函数内部貌似不允许print/select/raiserror 也不允许嵌套其它函数 真是蛋疼~~)
CREATE PROCEDURE usp_SplitStrByXQuery(@Str VARCHAR(8000),@split_Del VARCHAR(10)) -- 这里定义成 varchar 的原因大家自己想想
WITH ENCRYPTION,EXECUTE AS OWNER
AS
BEGIN
DECLARE @temptab TABLE(oldStr VARCHAR(8000),newStr VARCHAR(8000))
INSERT INTO @temptab
( oldStr ,
newStr
)
SELECT tab.Old_Str ,
LTRIM(RTRIM(xtab.newStr.value('.[1]', 'varchar(8000)')))
FROM ( SELECT @Str AS Old_Str ,
CONVERT(XML, '<xmlroot><v>' + REPLACE(@Str,
@split_Del,
'</v><v>')
+ '</v></xmlroot>') AS xml_Column
) tab
CROSS APPLY xml_Column.nodes('/xmlroot/v') xtab ( newStr );
SELECT * FROM @temptab
END
-----然而瞬间打脸,居然是可以的,顺便把 concatenate 的 for xml path 方法贴出来
CREATE FUNCTION uf_SplitStrByXQuery(@Str NVARCHAR(4000),@split_Del NVARCHAR(10))
RETURNS @temptab TABLE(orderID INT IDENTITY(1,1),splitStr NVARCHAR(4000))
AS
BEGIN
INSERT INTO @temptab( splitStr )
SELECT B.splitStr FROM
(
SELECT CONVERT(XML,'<v>'+REPLACE(@Str,@split_Del,'</v><v>')+'</v>') AS xmlColumn
) A
CROSS APPLY
(
SELECT N.value.value('.[1]','NVARCHAR(4000)') AS splitStr FROM A.xmlColumn.nodes('/v')N(value)
) B
RETURN
END
/* Concatenate String function can be created, using for xml path*/
DECLARE @tmptab TABLE(id INT,strCol NVARCHAR(4000))
INSERT INTO @tmptab( id, strCol )
SELECT * FROM uf_SplitStrByXQuery('a,b,c',',')
--SELECT * FROM @tmptab
SELECT stuff((SELECT ','+strCol FROM @tmptab ORDER BY id FOR XML PATH('')),
1,1,'')
三 、 新颖的方法 摘自技术博客 略微有所修改
declare @split_Del varchar(10)=','
;with StrTab(id,col) as
(
select 'A','LAS,AFE,FJWEO,JDOFW,AFD'
UNION ALL
SELECT 'B','WEOIW,FWOE,[IJWWJ,OIASJOW'
UNION ALL
SELECT 'C','A,B,C,D,E,F,G,H,I,J'
),
Num(orderid)AS (
select rank()over(order by number)
from master..spt_values where number between 1 and 8000 group by number
)
SELECT s.id,ROW_NUMBER()over(partition by s.id order by s.id) as orderid,
SUBSTRING(s.col,n.orderid,
CHARINDEX(@split_Del,s.col+@split_Del,n.orderid)-n.orderid) as splited_Str
FROM NUM n JOIN StrTab s on n.orderid<LEN(s.col) and SUBSTRING(@split_Del+s.col,n.orderid,1)=@split_Del
order by s.id
---再改
create function uf_SplitStr(@str varchar(8000),@split varchar(10))
--with encryption,execute as owner
returns @temptab table(oldStr varchar(8000),newStr varchar(8000))
as
begin
;with num_Recur as
(
select 1 as number
union all
select number+1 from num_Recur where number<=1000
),
tab(strCol) as
(
select @str
)
insert into @temptab(oldStr,newStr)
select t.strCol as oldStr,
SUBSTRING(@str,
number,
CHARINDEX(@split,@str+@split,number)-number) as newStr
from tab t join num_Recur n
on n.number<LEN(t.strCol)
and SUBSTRING(@split+@str,n.number,1)=@split
option(maxrecursion 1000)
return
end
select * from uf_SplitStr('a,b,c',',')
select * from (values('a,b,c,d'),('e,f,h'),('k,i,l')) tab(strcol) cross apply uf_SplitStr(strcol,',') ftab
四、拆分字符串表值函数:
一根指针获取:
CREATE FUNCTION uf_SplitStr(@Str NVARCHAR(4000),@split_Del NVARCHAR(10)) RETURNS @tmpTab TABLE(id INT,col NVARCHAR(4000)) WITH ENCRYPTION,EXECUTE AS OWNER AS BEGIN DECLARE @tmpStr NVARCHAR(4000), @chindex INT=1, @count INT=0 SET @chindex=CHARINDEX(@split_Del,@Str,1) -- first charindex WHILE @chindex>=0 BEGIN SET @count+=1 SET @tmpStr=SUBSTRING(@Str,1,@chindex-1); --PRINT CAST(@count AS VARCHAR)+@tmpStr INSERT INTO @tmpTab (id,col ) VALUES ( @count,@tmpStr ) SET @Str=SUBSTRING(@Str,@chindex+1,LEN(@Str)-@chindex) -- recursively obtain substring of @Str --PRINT @Str SET @chindex=CHARINDEX(@split_Del,@Str,1) IF(@chindex=0 AND LEN(@Str)>0) BEGIN SET @Str=SUBSTRING(@Str,1,LEN(@Str)) -- last not contains comma INSERT INTO @tmpTab ( id, col ) VALUES ( @count+1, -- id - int @Str -- col - nvarchar(4000) ) BREAK -- not exists then break , out of cursor END END RETURN END GO
/* Test Script Start*/ IF OBJECT_ID('tempdb..#temptabSplit','U') IS NOT NULL DROP TABLE #temptabSplit GO CREATE TABLE #temptabSplit(uniq_id INT IDENTITY(1,1) ,colStr varchar(8000)) GO INSERT INTO #temptabSplit(colStr) VALUES(',1,2,3,3434,545,,,,'), ('abcafeoijojsefjwoe') SELECT t.*,f.* FROM #temptabSplit t OUTER APPLY uf_SplitStr(t.colStr,',') f /* Test Script End*/
两根指针循环获取:
------以下代码可能有 bug 请慎重
CREATE FUNCTION [dbo].[uf_SplitStr](@str varchar(8000),@split_Del varchar(10))
returns @temptable table(col varchar(4000))
as
begin
--declare @str varchar(max)='a,b,c,d,e,f,g,h,i,j,kbac'
--declare @split_Del varchar(10)=',',
declare @tempstr varchar(4000)=''
declare @chindex_pre int=0,
@chindex_next int=CHARINDEX(@split_Del,@str),@indcnt int=0
while 1=1
begin
if (@chindex_pre<@chindex_next)
BEGIN
set @tempstr=SUBSTRING(@str,@chindex_pre+1,@chindex_next-@chindex_pre-1)
--print @tempstr
insert into @temptable values(@tempstr)
END
--if(@chindex_pre>@chindex_next)
ELSE
begin
set @tempstr=SUBSTRING(@str,@chindex_pre+1,LEN(@str)-@chindex_pre)
--print @tempstr
insert into @temptable values(@tempstr)
break
end
select @chindex_pre=@chindex_next
set @chindex_next=CHARINDEX(@split_Del,@str,@chindex_pre+1)
end
return
end
GO
以前的脚本: 可能有不对
declare @str varchar(8000)='a,b,c,d', 2 @split varchar(10)=',', 3 @Final_Str varchar(max)='', 4 @Temp_Str varchar(128) 5 declare @start int=0 6 declare @location int 7 declare @length int 8 set @str=LTRIM(RTRIM(@str))-- trim begining and end space 9 10 set @location=CHARINDEX(@split,@str)--First location 11 12 SET @Final_Str=SUBSTRING(@str,@start+1,@location-1)-- the string before first loaction 13 14 WHILE 1=1-- loop while exists split in str 15 BEGIN 16 SET @start=@location+1--Second change substr start location 17 --set @length=(LEN(@Str)-@location)--length of new str 18 SET @Str=SUBSTRING(@str,@start,LEN(@Str)) 19 20 SET @location=CHARINDEX(@split,@str)--redefine the location for split in str 21 22 if @location!=0-- check if it is the last one, if so ,another logic to avoid errors. 23 SET @Temp_Str=SUBSTRING(@str,1,@location-1) 24 else set @Temp_Str=SUBSTRING(@str,1,@location+len(@str)) 25 26 SET @Final_Str+=@Temp_Str 27 if @location=0 break 28 END 29 print @Final_Str
也是一根指针的,只是把最后一个拿出来做判断了
CREATE FUNCTION dbo.ufn_SplitStringTODT
(
@SourceSql VARCHAR(MAX) ,
@StrSeprate VARCHAR(10)
)
RETURNS @temp TABLE (ID INT IDENTITY(1,1),C1 INT )
AS
BEGIN
DECLARE @i INT
SET @SourceSql = RTRIM(LTRIM(@SourceSql))
SET @i = CHARINDEX(@StrSeprate, @SourceSql)
WHILE @i >= 1
BEGIN
INSERT @temp(C1)
VALUES ( LEFT(@SourceSql, @i - 1) )
SET @SourceSql = SUBSTRING(@SourceSql, @i + 1,
LEN(@SourceSql) - @i)
SET @i = CHARINDEX(@StrSeprate, @SourceSql)
END
IF @SourceSql <> '\'
INSERT @temp(C1)
VALUES ( @SourceSql )
RETURN
END
GO
--=====================================================
--用法:
SELECT * FROM dbo.ufn_SplitStringTODT('13,2,1,3',',')
五. 上递归大法 获取 substring 函数的 起始位置,以及截取字串长度 prePos,subPos 当然还有拆分出的字串的 order (orderid)
DECLARE @temptab TABLE(strCol VARCHAR(8000))
INSERT INTO @temptab ( strCol )
VALUES ( 'a,b,c,d,e,f' -- strCol - varchar(8000)
)
--,
--( 'g,h,i,j,k,l' -- strCol - varchar(8000)
-- )
DECLARE @split_Del VARCHAR(10)=','
--SELECT * FROM @temptab
;WITH tab(strCol,orderid,prePos,subPos) AS (
SELECT strCol,1 AS orderid,1 AS prePos,CHARINDEX(@split_Del,strCol) AS subPos FROM @temptab
UNION ALL
SELECT strCol,orderid+1,subPos+1,CHARINDEX(@split_Del,strCol,subPos+1) AS subPos FROM tab
WHERE CHARINDEX(@split_Del,strCol,subPos+1)>0
)
SELECT tab.strCol,tab.orderid,SUBSTRING(tab.strCol,tab.prePos,tab.subPos-tab.prePos) AS newStr FROM tab OPTION(MAXRECURSION 10)
--issue: the last alpha would be lost
/*
a,b,c,d,e,f 1 a
a,b,c,d,e,f 2 b
a,b,c,d,e,f 3 c
a,b,c,d,e,f 4 d
a,b,c,d,e,f 5 e
*/
Version 2 to fix the issue above
DECLARE @temptab TABLE(strCol VARCHAR(8000))
INSERT INTO @temptab ( strCol )
VALUES ( ',a,b,c,d,e,f' -- strCol - varchar(8000)
)
--,
--( 'g,h,i,j,k,l' -- strCol - varchar(8000)
-- )
DECLARE @split_Del VARCHAR(10)=','
--SELECT * FROM @temptab
;WITH tab(strCol,orderid,prePos,subPos) AS (
SELECT strCol,1 AS orderid,1 AS prePos,CHARINDEX(@split_Del,strCol) AS subPos FROM @temptab
UNION ALL
SELECT strCol,orderid+1,subPos+1,CHARINDEX(@split_Del,strCol+@split_Del,subPos+1) AS subPos FROM tab
WHERE CHARINDEX(@split_Del,strCol+@split_Del,subPos+1)>0
)
SELECT tab.strCol,tab.orderid,SUBSTRING(tab.strCol,tab.prePos,tab.subPos-tab.prePos) AS newStr FROM tab OPTION(MAXRECURSION 10)
--issue: the last alpha would be lost
/*
,a,b,c,d,e,f 1
,a,b,c,d,e,f 2 a
,a,b,c,d,e,f 3 b
,a,b,c,d,e,f 4 c
,a,b,c,d,e,f 5 d
,a,b,c,d,e,f 6 e
,a,b,c,d,e,f 7 f
*/
-------------------------------- Recursively split Character String -------------------------------------------
CREATE PROCEDURE uf_SplitStrNew(@strCol VARCHAR(8000),@split_Del VARCHAR(10))
WITH ENCRYPTION,EXECUTE AS OWNER
AS
BEGIN
DECLARE @temptab TABLE(strCol varchar(8000))
INSERT INTO @temptab ( strCol ) VALUES(@strCol)
SELECT strCol FROM @temptab
;WITH tab(strCol,orderid,prePos,subPos) AS (
SELECT strCol,1 AS orderid,1 AS prePos,CHARINDEX(@split_Del,strCol) AS subPos FROM @temptab
UNION ALL
SELECT strCol,orderid+1,subPos+1,CHARINDEX(@split_Del,strCol+@split_Del,subPos+1) AS subPos FROM tab
WHERE CHARINDEX(@split_Del,strCol+@split_Del,subPos+1)>0
)
SELECT tab.strCol,tab.orderid,SUBSTRING(tab.strCol,tab.prePos,tab.subPos-tab.prePos) AS newStr FROM tab OPTION(MAXRECURSION 10)
END
GO
EXEC dbo.uf_SplitStrNew 'a,b,c,d,e,f',','
--issue has been fixed
/*
,a,b,c,d,e,f 1
,a,b,c,d,e,f 2 a
,a,b,c,d,e,f 3 b
,a,b,c,d,e,f 4 c
,a,b,c,d,e,f 5 d
,a,b,c,d,e,f 6 e
,a,b,c,d,e,f 7 f
*/
小结:以上方法均亲测,但是不排除有问题,拆分无外乎 1 使用动态拼凑 SQL 将 逗号替换为 INSERT INTO 或者 Union all select 等等能够把分隔符之间字符串取出的表达式,2 转换为 xml 数据,利用XQuery结合CROSS/OUTER APPLY 的优势进行函数取出 3.利用SQL语句的 SELECT 获取定位逗号,然后根据逗号分隔去取出
4.使用 charindex 跟 substring 做成表值函数。 显然 第四种方法最易想到。
5.利用 CTE 递归循环获取 split delimeter 的 position,此法慎用,递归深度太大可能导致内存泄漏
补充:
用户自定义函数可以是确定性的也可以是非确定性的。确定性并不是根据任何参数类型定义的,而是根据函数的功能定义的。如果给定了一组特定的有效输入,每次函数就都能返回相同的结果,那么就说该函数是确定性的。SUM()就是一个确定性的内置函数。3、5、10的总合永远都是18,而GETDATE()的值就是非确定性的,因为每次调用它的时候GETDATE()都会改变。
为了达到确定性的要求,函数必须满足以下4个条件:
[1] 函数必须是模式绑定的。这意味着函数所依赖的任何对象会有一个依赖记录,并且在没有删除这个依赖的函数之前都不允许改变这些对象。
[2] 函数引用的所有其他函数,无论是用户定义的,还是系统定义的,都必须是确定性的。
[3] 不能引用在函数外部定义的表(可以使用表变量和临时表,只要它们是在函数作用域内定义就行)。
[4] 不能使用扩展存储过程。
确定性的重要性在于它显示了是否要在视图或计算列上建立索引。如果可以可靠地确定视图或计算列的结果,那么才允许在视图或计算列上建立索引。这意味着,如果视图或计算列引用非确定性函数,则在该视图或列上将不允许建立任何索引。
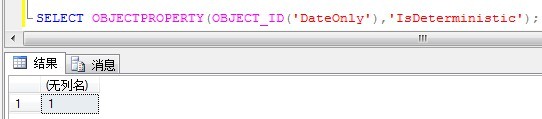
如果判定函数是否是确定性:除了上面描述的规则外,这些信息存储在对象的IsDeterministic属性中,可以利用OBJECTPROPERTY属性检查。
SELECT OBJECTPROPERTY(OBJECT_ID('DateOnly'),'IsDeterministic'); --只是刚才的那个自定义函数
输出结果如下:
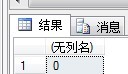
居然是非确定性的。原因在于之前在定义该函数的时候,并没有加上这个"WITH SCHEMABINDING"。

ALTER FUNCTION dbo.DateOnly(@Date date) RETURNS date WITH SCHEMABINDING --当加上这一句之后 AS BEGIN RETURN @Date END
在执行查询,该函数就是确定性的了。
2015-02-13

 浙公网安备 33010602011771号
浙公网安备 33010602011771号