[嵌入式学习] XV6Lab 2025笔记--page tables
Speed up system calls(easy)
加速系统调用,原理是通过一个只读区域来共享内核的数据,取消了执行一些系统调用进行内核交叉的必要性,以优化getpid()为例子。
要做的事情:在创建进程时,在USYSCALL(一个另外定义的虚拟地址)下映射一个只读页面。在只读页面存储当前进程的pid。
ugetpid()函数被定义在了ulib.c内:
#ifdef LAB_PGTBL
int
ugetpid(void)
{
struct usyscall *u = (struct usyscall *)USYSCALL;
return u->pid;
}
#endif
可以看到本质上很简单,就是访问USYSCALL这个地址而已。而要将这个数据存放在这个虚拟地址,本质上是对进程创建时的函数进行修改。
在proc.c文件的pagetable_t proc_pagetable(struct proc *p)内,添加USYSCALL虚拟地址的映射,并且在其中放入pid数据:
struct usyscall * pidpa = kalloc();
if(pidpa==0)
return 0;
pidpa->pid = p->pid;
//核心,将物理地址映射到实际地址
if(mappages(pagetable, USYSCALL, PGSIZE, (uint64)pidpa, PTE_R|PTE_U) < 0){
uvmfree(pagetable, 0);
return 0;
}
与此同时,要在进程销毁时将其free:
void
proc_freepagetable(pagetable_t pagetable, uint64 sz)
{
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
uvmunmap(pagetable, USYSCALL, 1, 0);//新添加的内容
uvmfree(pagetable, sz);
}
问题:exec和fork对应的代码是否需要进行修改?
Print a page table (easy)
打印页表,用户空间添加了系统调用kpgtbl(),会实际调用sys_kpgtbl(),其中本质上是需要我们实现vmprint()函数:
#if defined(LAB_PGTBL) || defined(SOL_MMAP) || defined(SOL_COW)
uint64 factor[3]={PGSIZE,PGSIZE*512,PGSIZE*512*512};
static void
_vmprint(pagetable_t pagetable,uint level,unsigned long long l){
for(int i=0;i<512;i++){
pte_t pte = pagetable[i];
if((pte & PTE_V)){
for(int j=0;j<3-level;j++)
printf(" ..");
printf("%p:pte %p pa %p\n",(void*)(l+i*factor[level]),(void *)pte,(void *)PTE2PA(pte));
if(level>0)
_vmprint((pagetable_t)PTE2PA(pte),level-1,l+i*factor[level]);
}
}
}
void
vmprint(pagetable_t pagetable) {
printf("page table %p\n",(void *)pagetable);
_vmprint(pagetable,2,0);
}
#endif
这里是递归进行打印,一旦遍历到PET_V的页表就将其打印出来。
Use superpages (moderate)/(hard)
题目要求我们在系统调用sbrk时,如果分配的内存量满足可以使用大页的情况下,需要给进程分配大页的内存,当对内存进行回收时,如果没有回收满大页的内存量,需要将大页分解成小页。
这里的superpage指的是只用二级页表,
虚拟地址的结构为:
| L2(38:30) | L1(29:21) | offset(20:0) |
而传统页表的虚拟地址结构为:
| L2(38:30) | L1(29:21) | L0(20:12) | offset(11:0) |
传统页表从虚拟地址到物理地址的流程:
硬件读取stap寄存器内的物理地址->
一级页表->使用L2内的数据作为索引在一级页表查询到物理地址->
二级页表->使用L1内的数据作为索引在二级页表查询到物理地址->
三级页表->使用L0内的数据作为索引在三级页表查询到物理地址->
页表内的物理地址+offset即为最终对应的物理地址。
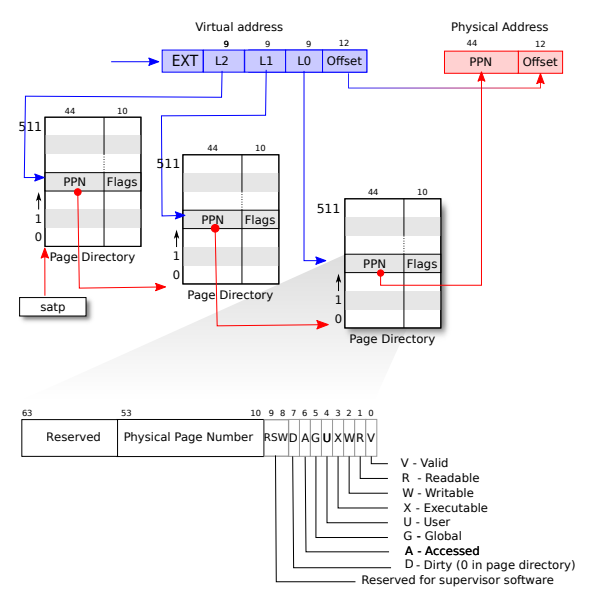
图 RISCV虚拟地址到物理地址的流程。
而大页则是减少一次寻址,将L0的空间合并到offset,使得一个页从4k空间上升到2M。
实现
物理空间分配
首先是物理内存的分配,xv6的物理内存分配函数kalloc()只能实现对齐4kb空间大小的分配。需添加分配大页的函数ksuperalloc(),并且在kinit()中添加对大页内存空间的初始化。其内容在kalloc.c中。这些照着原有的抄写一些就可以,关键要自己设定一个位置给大页和普通页进行切分。
void
kinit()
{
initlock(&ksupermem.lock, "ksupermem");
superfreerange(end, end + SUPERPGSIZE*SUPERPAGES);
initlock(&kmem.lock, "kmem");
freerange(end + SUPERPGSIZE*SUPERPAGES, (void*)PHYSTOP);
}
/* 大页内存初始化 */
void
superfreerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)SUPERPGROUNDUP((uint64)pa_start);
for(; p + SUPERPGSIZE <= (char*)pa_end; p += SUPERPGSIZE)
ksuperfree(p);
}
/* 大页分配 */
void *ksuperalloc(void){
struct run *r;
acquire(&ksupermem.lock);
r = ksupermem.freelist;
if(r)
ksupermem.freelist = r->next;
release(&ksupermem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
/* 大页释放 */
void ksuperfree(void *pa){
struct run *r;
if(((uint64)pa % SUPERPGSIZE) != 0 || (char*)pa < end || (char*)pa >= end + SUPERPAGES*SUPERPGSIZE)
panic("ksuperfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, SUPERPGSIZE);
r = (struct run*)pa;
acquire(&ksupermem.lock);
r->next = ksupermem.freelist;
ksupermem.freelist = r;
release(&ksupermem.lock);
}
内存分配
xv6使用sbrk()系统调用来分配空间,其中使用了growproc()函数,其中会对输入函数的正负分为申请空间和释放空间两个分支。
申请空间为uvmalloc()释放空间为uvmdealloc(),其中需要再针对的添加mapsuperpages和改进uvmunmap来适配大页分配的情况。
uvmalloc()函数将页表映射的大小从oldsz扩大到newsz,这里通过对大页空间对齐分出了可能的三段空间,进行了分段的物理空间申请和页表映射。普通页照旧使用mappages(),而针对大页另外建立了一个mapsuperpages()函数来进行映射。
uint64
uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz, int xperm)
{
char *mem;
uint64 a;
int sz;
int sz1=newsz,sz2=oldsz;
if(newsz < oldsz)
return oldsz;
oldsz = PGROUNDUP(oldsz);
if(SUPERPGROUNDUP(oldsz) <= newsz){
sz1 = SUPERPGROUNDUP(oldsz);
}
if(SUPERPGROUNDUP(oldsz) < SUPERPGROUNDDOWN(newsz)){
sz2 = SUPERPGROUNDDOWN(newsz);
}
/* 段1,前面部分的小页 */
sz = PGSIZE;
for(a = oldsz; a < sz1; a += sz){
mem = kalloc();
if(mem == 0){
uvmdealloc(pagetable, a, oldsz);
return 0;
}
#ifndef LAB_SYSCALL
memset(mem, 0, sz);
#endif
if(mappages(pagetable, a, sz, (uint64)mem, PTE_R|PTE_U|xperm) != 0){
kfree(mem);
uvmdealloc(pagetable, a, oldsz);
return 0;
}
}
/* 段2,中间部分的大页 */
sz = SUPERPGSIZE;
for(; a < sz2; a += sz){
mem = ksuperalloc();
if(mem == 0){
uvmdealloc(pagetable, a, oldsz);
return 0;
}
#ifndef LAB_SYSCALL
memset(mem, 0, sz);
#endif
if(mapsuperpages(pagetable, a, sz, (uint64)mem, PTE_R|PTE_U|xperm) != 0){
ksuperfree(mem);
uvmdealloc(pagetable, a, oldsz);
return 0;
}
}
/* 段3,最后部分的小页 */
sz = PGSIZE;
for(; a < newsz; a += sz){
mem = kalloc();
if(mem == 0){
uvmdealloc(pagetable, a, oldsz);
return 0;
}
#ifndef LAB_SYSCALL
memset(mem, 0, sz);
#endif
if(mappages(pagetable, a, sz, (uint64)mem, PTE_R|PTE_U|xperm) != 0){
kfree(mem);
uvmdealloc(pagetable, a, oldsz);
return 0;
}
}
return newsz;
}
这是mapsuperpages()的实现
int
mapsuperpages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
if((va % SUPERPGSIZE) != 0)
panic("mapsuperpages: va not aligned");
if((size % SUPERPGSIZE) != 0)
panic("mapsuperpages: size not aligned");
if(size == 0)
panic("mapsuperpages: size");
a = va;
last = va + size - SUPERPGSIZE;
for(;;){
if((pte = superwalk(pagetable, a, 1)) == 0)
return -1;
if(*pte & PTE_V)
panic("mapsuperpages: remap");
*pte = PA2PTE(pa) | perm | PTE_R | PTE_V;
if(a == last)
break;
a += SUPERPGSIZE;
pa += SUPERPGSIZE;
}
return 0;
}
mapsuperpages()里涉及到了superpage需要的walk,也需要进行实现。
pte_t *
superwalk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("superwalk");
for(int level = 2; level > 1; level--) {
pte_t *pte = &pagetable[PX(level, va)];
if(*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte);
#ifdef LAB_PGTBL
if(PTE_LEAF(*pte)) {
return pte;
}
#endif
} else {
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V;
}
}
return &pagetable[PX(1, va)];
}
对于释放空间,需要使用uvmdealloc(),其本是进行空间对齐后使用uvmunmap(),该函数需要实现的功能是:如果大页的部分空间被释放,需要将其拆分为普通页,及尽可能多的释放出空间来。核心判断是否为大页内存方是直接通过判断地址大小,来确定该内存是位于大页还是普通页区域。
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
uint64 a;
pte_t *pte;
int sz = PGSIZE;
if((va % PGSIZE) != 0)
panic("uvmunmap: not aligned");
// printf("va:%lx,npages:%ld\n",va,npages);
for(a = va; a < va + npages*PGSIZE; a += sz){
if((pte = walk(pagetable, a, 0)) == 0) // leaf page table entry allocated?
continue;
if((*pte & PTE_V) == 0) // has physical page been allocated?
continue;
sz = PGSIZE;
if(PTE_FLAGS(*pte) == PTE_V)
panic("uvmunmap: not a leaf");
if(do_free){
uint64 pa = PTE2PA(*pte);
if(pa < (uint64)(end + SUPERPAGES*SUPERPGSIZE)){//判断是否是大页
if(a == SUPERPGROUNDUP(a)){//如果这里是刚好回收一个大页
sz = SUPERPGSIZE;
}
else {//如果不是刚好回收一个大页,需要把大页的内容拆成小页装入
int flags = PTE_FLAGS(*pte);
uint64 ppa = pa;
*pte = 0;//需要把大页对应位置先置0否则mappages里会remap错误
for(uint64 vva = SUPERPGROUNDDOWN(a);vva < a;vva += sz,ppa += sz){
void * mem = kalloc();
mappages(pagetable, vva, sz, (uint64)mem, flags);
memmove(mem,(void *)ppa,PGSIZE);
}
a = SUPERPGROUNDUP(a)-sz;
ksuperfree((void*)pa);
continue; // 直接到下一步循环是因为这里*pte不能被置0
}
ksuperfree((void*)pa);
}
else
kfree((void*)pa);
}
*pte = 0;
}
}
除了这些问题以外,还存在fork的场景,即需改进uvmcopy()函数,该函数实现的是将旧页表内的空间遍历全部拷贝到新页表,这就需要分为普通页和大页的情况进行考虑。
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
char *mem;
int szinc = PGSIZE;
for(i = 0; i < sz; i += szinc){
if((pte = walk(old, i, 0)) == 0)
continue;
if((*pte & PTE_V) == 0) {
continue;
}
szinc = PGSIZE;
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
if(pa < (uint64)(end + SUPERPGSIZE*SUPERPAGES)){
if((mem = ksuperalloc()) == 0)
goto err;
memmove(mem, (char*)pa, SUPERPGSIZE); // * 这里是重点,真正发生实际地址拷贝的地方
if(mapsuperpages(new, i, SUPERPGSIZE, (uint64)mem, flags) != 0){
ksuperfree(mem);
goto err;
}
szinc = SUPERPGSIZE;
}
else{
if((mem = kalloc()) == 0)
goto err;
memmove(mem, (char*)pa, PGSIZE); // * 这里是重点,真正发生实际地址拷贝的地方
if(mappages(new, i, PGSIZE, (uint64)mem, flags) != 0){
kfree(mem);
goto err;
}
}
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
问题:这样将实际物理内存划分为大页区和普通页区的做法是否全面?如果一直只是申请小片内存,那最后只剩下大页可用怎么办?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号