第一次个人编程作业(软件工程)
| 软件工程 | https://edu.cnblogs.com/campus/gdgy/informationsecurity1812 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/informationsecurity1812/homework/11155 |
| 作业目标 | |
代码链接(JAVA)
- github链接
- 已上传打包好的jar包到release包内
计算模块接口的设计与实现过程
工程截图
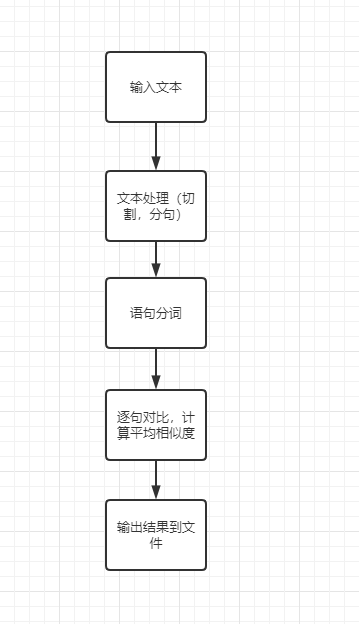
计算流程
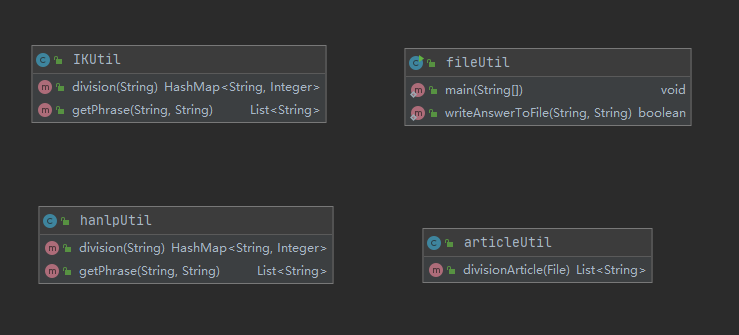
项目中的类:
util包下:
- IKUtil:IK分词器工具类(后被弃用)
- hanlpUtil:hanlp分词器工具类
- fileUtil:文件工具类
- articleUtil:文章处理工具类
service包下:
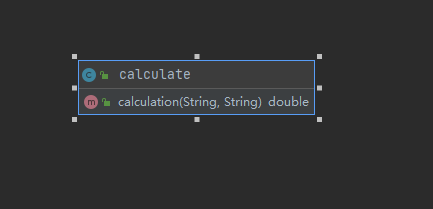
- calculate:计算类,计算两句语句的相似度
application包下:
- application:主类,程序入口
项目中类的各种方法
算法关键:余弦相似度(转载自 (https://blog.csdn.net/u012160689/article/details/15341303),有删改)
余弦计算相似度度量
相似度度量(Similarity),即计算个体间的相似程度,相似度度量的值越小,说明个体间相似度越小,相似度的值越大说明个体差异越大。
对于多个不同的文本或者短文本对话消息要来计算他们之间的相似度如何,一个好的做法就是将这些文本中词语,映射到向量空间,形成文本中文字和向量数据的映射关系,通过计算几个或者多个不同的向量的差异的大小,来计算文本的相似度。
向量空间余弦相似度(Cosine Similarity)
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
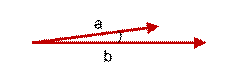
上图两个向量a,b的夹角很小可以说a向量和b向量有很高的的相似性,极端情况下,a和b向量完全重合。
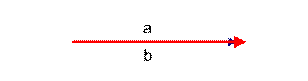
如上图:可以认为a和b向量是相等的,也即a,b向量代表的文本是完全相似的,或者说是相等的。如果a和b向量夹角较大,或者反方向。
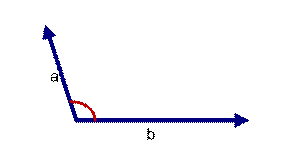
如上图: 两个向量a,b的夹角很大可以说a向量和b向量有很底的的相似性,或者说a和b向量代表的文本基本不相似。
计算公式:
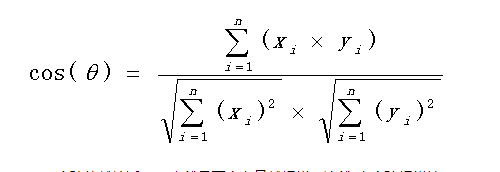
下面举一个例子,来说明余弦计算文本相似度
句子A:这只皮靴号码大了。那只号码合适
句子B:这只皮靴号码不小,那只更合适
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
第二步,列出所有的词。
这只,皮靴,号码,大了。那只,合适,不,小,很
第三步,计算词频。
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
第四步,写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
到这里,问题就变成了如何计算这两个向量的相似程度。我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合,这是表示两个向量代表的文本完全相等;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
计算两个句子向量
句子A:(1,1,2,1,1,1,0,0,0)
和句子B:(1,1,1,0,1,1,1,1,1)的向量余弦值来确定两个句子的相似度。
计算过程如下:
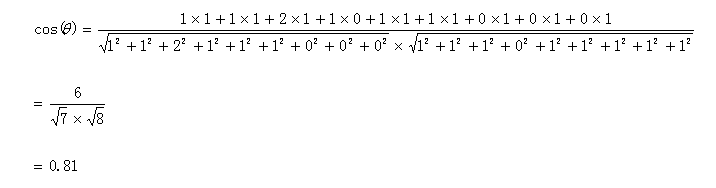
计算结果中夹角的余弦值为0.81非常接近于1,所以,上面的句子A和句子B是基本相似的
算法总结:
- 首先对语句进行分词
- 计算语句中的词频
- 计算余弦值
计算模块接口部分的性能改进
JProfiler性能监控图:
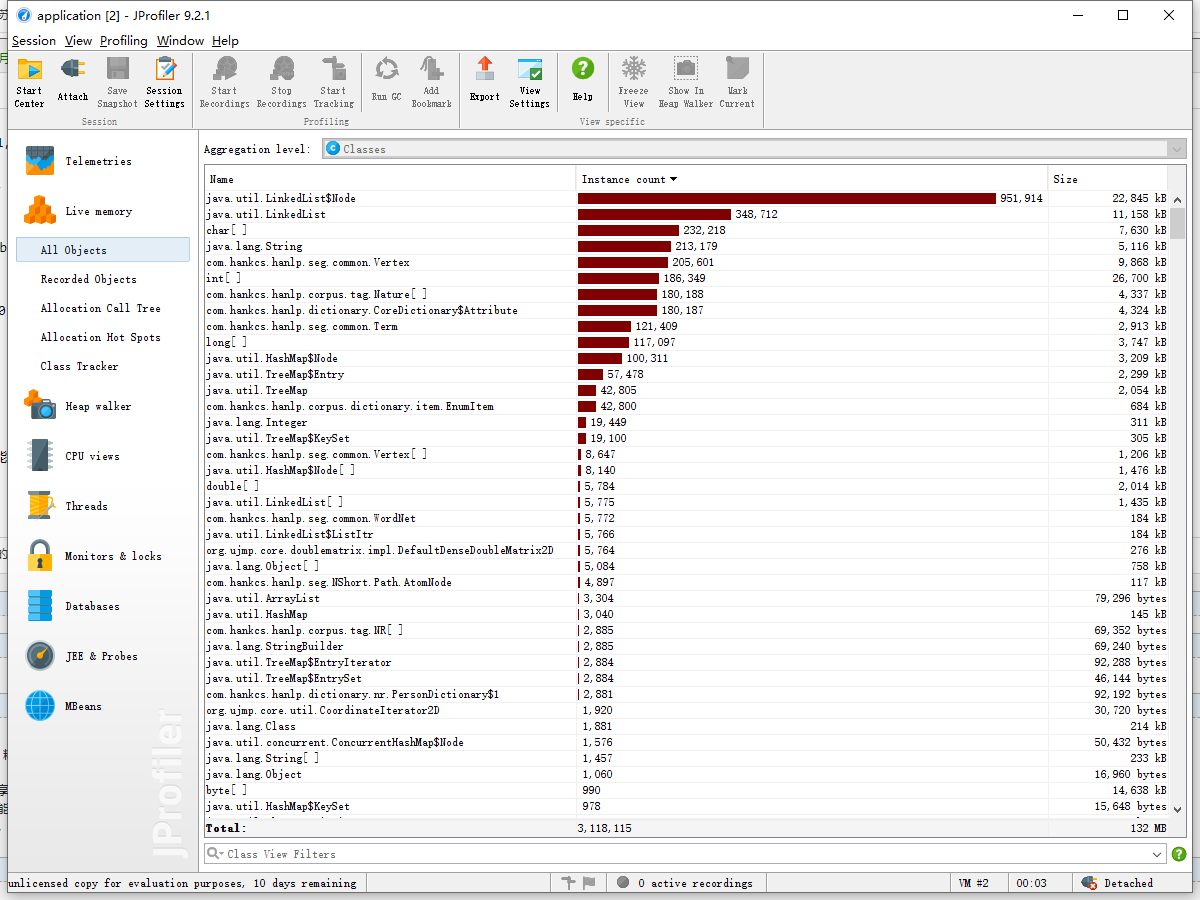
cpu load图(运行时间2s):
内存情况图:
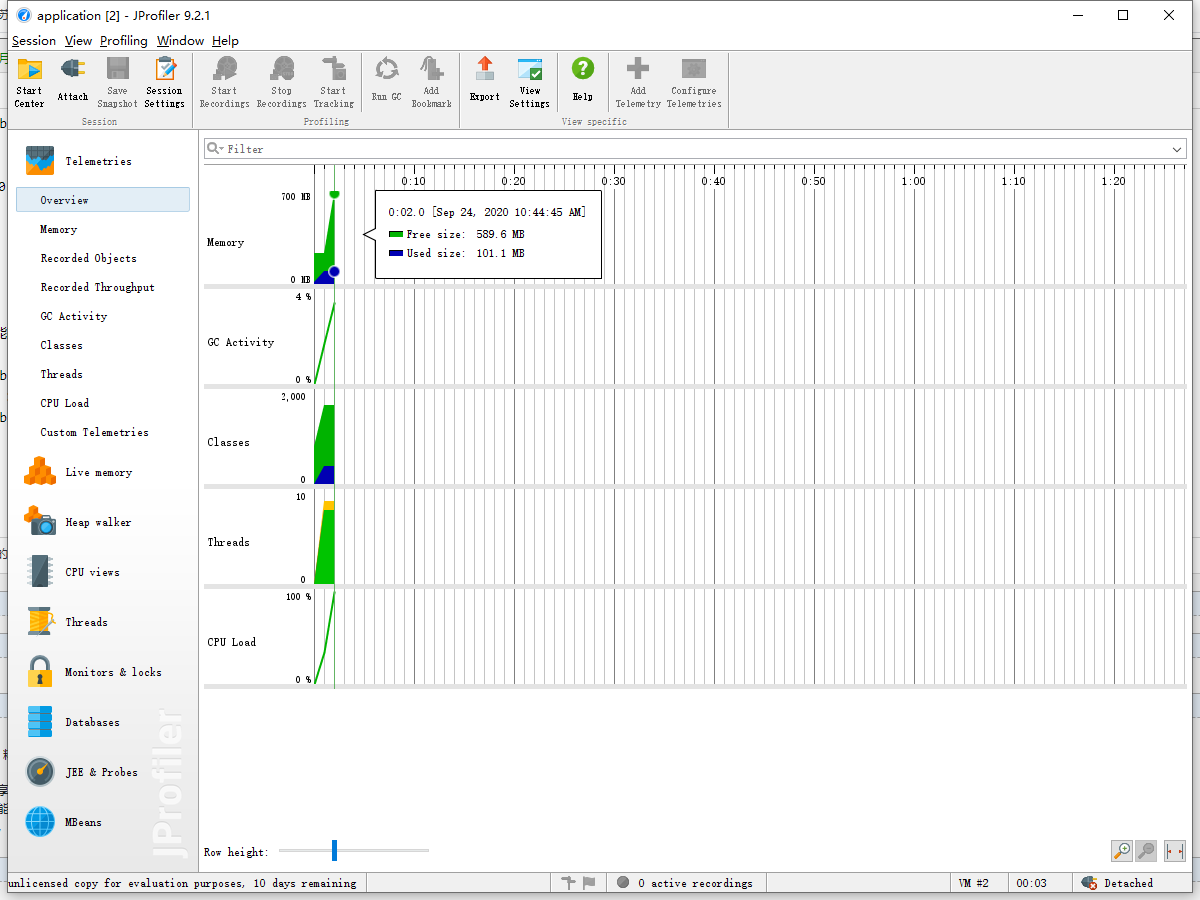
性能改进:
使用逐句对比计算平均相似度,算法复杂度达到O(n^2),运行时间一度需要7s左右。
后来使用fork/join框架,用多线程进行分任务计算,将运行时间减小到2-3s
其实尝试过进行全文词频对比,速度上去了,但是精度不佳。
后边改用hanlp分词器,在极速分词下运行时间可以压缩到1s以内,但是精度大约损失了2%。
计算模块部分单元测试展示
public class test {
@BeforeClass
public static void beforeTest(){
System.out.println("测试即将开始");
}
@AfterClass
public static void afterTest(){
System.out.println("测试结束");
}
//输入错误的路径
@Test
public void test1(){
String [] test={"","",""};
try {
new application.application().main(test);
} catch (IOException e) {
e.printStackTrace();
Assert.fail();
}
}
//输入空文件
@Test
public void test2(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_add.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException e) {
e.printStackTrace();
Assert.fail();
}
}
//输入错误的输出文件路径
@Test
public void test3(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_add.txt","E:/test"};
try {
new application.application().main(test);
} catch (IOException e) {
e.printStackTrace();
Assert.fail();
}
}
//测试添加20%的文本
@Test
public void test4(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_add.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException e) {
e.printStackTrace();
Assert.fail();
}
}
//测试删除20%的文本
@Test
public void test5(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_del.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException e) {
e.printStackTrace();
Assert.fail();
}
}
//测试调换语序文本
@Test
public void test6(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_dis_1.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException e) {
e.printStackTrace();
Assert.fail();
}
}
//测试调换语序文本
@Test
public void test7(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_dis_10.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException e) {
e.printStackTrace();
Assert.fail();
}
}
//测试调换语序文本
@Test
public void test8(){
String [] test={"E:/test/orig.txt","E:/test/orig_0.8_dis_15.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException e) {
e.printStackTrace();
Assert.fail();
}
}
//测试相同文本
@Test
public void test9(){
String [] test={"E:/test/orig.txt","E:/test/orig.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException e) {
e.printStackTrace();
Assert.fail();
}
}
//测试相同文本
@Test
public void test10(){
String [] test={"E:/test/orig_0.8_dis_15.txt","E:/test/orig_0.8_dis_15.txt","E:/test/answer.txt"};
try {
new application.application().main(test);
} catch (IOException e) {
e.printStackTrace();
Assert.fail();
}
}
}
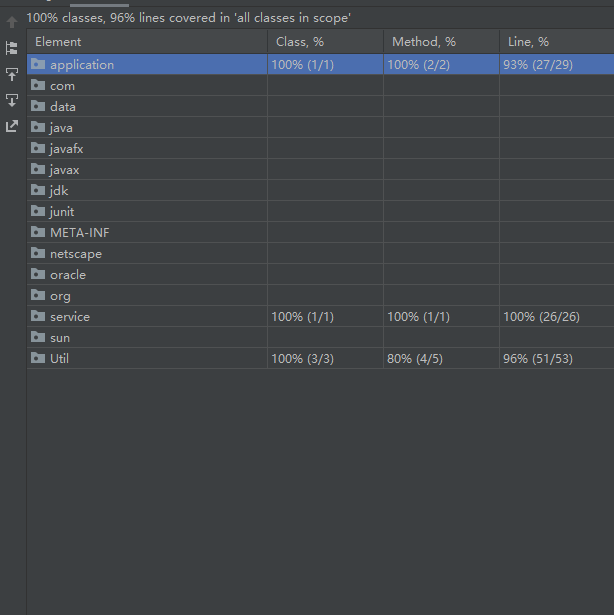
代码覆盖率
异常处理
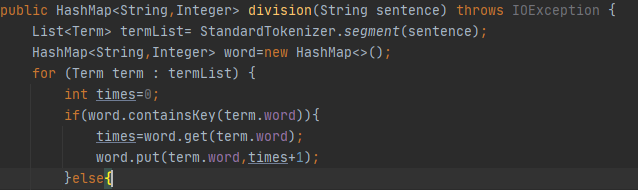
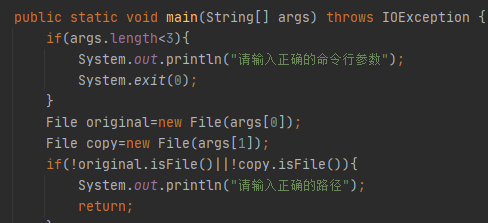
整个程序最主要的就是IOException,在读写文件时,若文件为空或者读写不到文件就会引发该异常。
PSP表格
| PSP 各个阶段 | 自己预估的时间(分钟) | 实际的记录(分钟) |
|---|---|---|
| 计划 | 30 | 35 |
| 需求分析 (包括学习新技术) | 30 | 35 |
| 生成设计文档 | 20 | 25 |
| 设计复审 | 10 | 15 |
| 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| 具体设计 | 20 | 25 |
| 具体编码 | 100 | 110 |
| 代码复审 | 60 | 50 |
| 测试(自我测试,修改代码,提交修改) | 30 | 35 |
| 报告 | 60 | 50 |
| 测试报告 | 20 | 25 |
| 计算工作量 | 20 | 25 |
| 事后总结, 并提出过程改进计划 | 60 | 65 |
| 合计 | 465 | 500 |
小结
通过这个个人作业还是学到不少的,掌握了测试方法,学到不少新的好玩的包。
个人能力还是有待提高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号