BUAA_OO_Unit1 表达式化简总结
BUAA_OO_Unit1 表达式化简总结
一、综述
面向对象课程的第一单元的主题是对设定规则的表达式进行规则化的化简,是我们从面向过程编程到面向对象编程思想转变的第一站,主要考察了对Java语言和课程系统的运用以及面向对象思想的初步实践。
本单元共三次作业,每次作业都是在上一次作业基础上做一些更新与迭代,即增加一些新的规则,使表达式的结构更加复杂,有效训练了同学们对问题结构的分析和设计能力。
二、作业分析
1. Homework 1
1.1 作业要求
读入一个只包含单层括号的单变量表达式,输出恒等变形展开括号后的表达式。表达式中只包含运算符加(+)、减(-)、乘(*)和乘方(**),输出的表达式可以在符合输出形式的基础上进行恒等化简。
1.2 架构分析
整体采用对表达式解析,利用栈转化成后缀表达式,利用自己构造的存储结构进行存储,最后进行从下到上的运算过程,最后将得到的表达式输出。
解析>>存储
分析作业,得到表达式的架构,一个表达式由若干个项(可以是一个)通过加号或减号连接,一个项由若干个因子(可以是一个)通过乘号连接。因子包括变量因子、常数因子和表达式因子。实际上,通过分析,所有的表达式都可以表示为
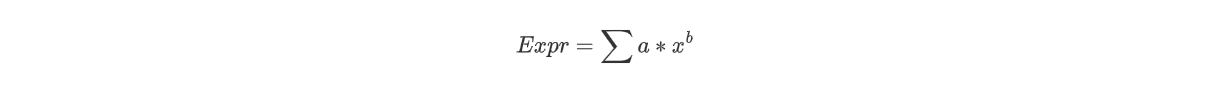
同样地,每一个项可以表示为
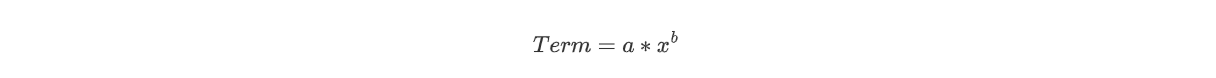
实际上,变量因子和常数因子都可以用上述项的格式表示。
所以我构建了一个 Expr 类,其中包含属性Hashmap<Integer, Term> terms,用来存储每一个项。同时构建了一个Term 类,其中包含属性ceofficient和power,分别表示系数和指数。最后所有的结构运算都可以表示成两个 Expr 之间的运算。
存储>>运算
运算的过程就是拆除括号的过程,同时我将合并同类项的工作放在运算过程中。通过建立一个运算类Operator,Operator类包含属性left和right,表示参与运算的两个表达式(幂运算的right是指数)。下面介绍Operator类的各种方法。
-
public Hashmap<Integer, Term> OpAdd()先将left Expr的Hashmap深拷贝入一个新的Hashmap<Integer, Term> addterms中,然后通过遍历right Expr的Hashmap,取出一个Term,通过遍历addterms去寻找同指数的Term(即寻找同类型),如果找到同类项,则改变addterms中相应Term的系数(系数相加);若未找到同类项则直接向addterms中添加该Term。
-
public Hashmap<Integer, Term> OpSub()和加法的方法类似。
-
public Hashmap<Integer, Term> OpMul()遍历right Expr的Hashmap,取出一个Term,然后遍历left Expr的Hashmap,取出一个Term,将两个Term的指数相加,系数相乘,得到新的coefficient和power,构建新的Term,存入新的Hashmap<Integer, Term> multerms,然后不断复现加法合并同类项的方法。
-
public Hashmap<Integer, Term> OpPower()在这里和上述的运算方法不同,这不是两个Expr的运算,而是一个Expr和一个指数的运算。先建立新的Hashmap<Integer, Term> powerTerms。
这里需要对指数进行特殊判断,如果指数为0,则建立新的Term
1*x^0,存入Hashmap并输出。如果指数为1,则输出Expr的Hashmap;如果指数大于1,则通过循环进行多次OpMul的过程。
运算>>输出
通过运算已经得到了最后的表达式Last Expr,由于缺乏经验,笔者将输出写在MainClass的一个函数里,最后导致MainClass的代码量过大。
笔者在输出时做了一些细节上的化简,包括
- 如果表达式存在系数为正的Term,则表达式第一项输出系数为正的Term时可以省略输出其系数的正号。先将Last Expr的Term根据指数的正负分别存入Arraylist
posTerms 和ArrayListnegTerms ,如果两个容器都为空,则输出0;若不为空则先后输出posTerms和negTerms的内容。 - 一些更加细节的内容,x*x比x**2更短,指数为1时可以省略等等,不在此赘述。
1.3 复杂度分析
方法复杂度:
| methed | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Term.Term(String) | 2.0 | 1.0 | 1.0 | 2.0 |
| Term.Term(BigInteger, Integer) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.subCoefficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.getPower() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.addCoefficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parserTerm(String) | 2.0 | 2.0 | 2.0 | 2.0 |
| Parser.parserStr(String) | 1.0 | 1.0 | 1.0 | 8.0 |
| Parser.parserOp(String) | 7.0 | 7.0 | 6.0 | 7.0 |
| Parser.Parser(HashMap) | 0.0 | 1.0 | 1.0 | 1.0 |
| Operator.opSub() | 5.0 | 1.0 | 4.0 | 4.0 |
| Operator.opPower(Integer) | 7.0 | 3.0 | 5.0 | 5.0 |
| Operator.opMul() | 7.0 | 1.0 | 4.0 | 4.0 |
| Operator.Operator(Expr, Expr) | 0.0 | 1.0 | 1.0 | 1.0 |
| Operator.opAdd() | 5.0 | 1.0 | 4.0 | 4.0 |
| MainClass.out(ArrayList, ArrayList) | 46.0 | 1.0 | 20.0 | 20.0 |
| MainClass.main(String[]) | 5.0 | 1.0 | 5.0 | 5.0 |
| Expr.setTerms(HashMap) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expr.getTerms() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expr.Expr(HashMap) | 0.0 | 1.0 | 1.0 | 1.0 |
| Total | 87.0 | 29.0 | 62.0 | 71.0 |
| Average | 4.35 | 1.45 | 3.1 | 3.55 |
类复杂度:
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Expr | 1.0 | 1.0 | 3.0 |
| MainClass | 12.0 | 19.0 | 24.0 |
| Operator | 3.6 | 5.0 | 18.0 |
| Parser | 4.75 | 9.0 | 19.0 |
| Term | 1.1666666666666667 | 2.0 | 7.0 |
| Total | 71.0 | ||
| Average | 3.55 | 7.2 | 14.2 |
通过分析,因为笔者将输出这一结构放在了MainClass中,导致MainClass中的方法和类的复杂度严重超标,使得这一部分代码过于杂糅,实际上是因为还未从面向过程编码转换到面向对象编程。
2. Homework 2
2.1 作业要求
第二次作业在第一次作业的基础上添加了三角函数、自定义函数和求和函数。
2.2 架构分析
整体同样采用对表达式解析,利用栈转化成后缀表达式,利用自己构造的存储结构进行存储,最后进行从下到上的运算过程,最后将得到的表达式输出。
解析>>存储
实际上,通过分析,对于最终表达式的结构依然可以用一个公式表示:

只不过题目对三角函数内部的因子做了一个限制,只能是常数因子和幂函数因子。
同样地,每一项可以表示为
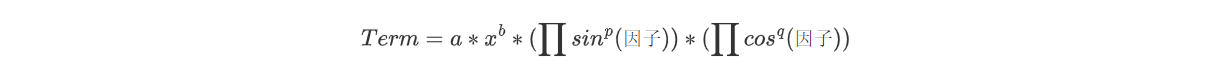
笔者建立了一个Expr类,含有ArrayList
存储>>运算
第二次作业的运算和第一次作业大致相似,不过需要在运算合并同类型时,需要在Term类中重写比较方法,在三角函数类中写一个比较方法。
运算>>输出
因为偷懒,笔者依然将输出写在了MainClass里。第二次作业的输出比第一次作业多了三角函数的部分,所以细节的部分要比第一次作业多很多,特别是笔者比较简单的存储结构带来的 小细节问题就会很多,比如Term中Hashmap为空的情况,或者Hashmap每一项的值全为0(即三角函数的指数为0)的情况等等。
2.3 复杂度分析
方法复杂度:
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Cos.Cos(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Cos.Cos(BigInteger, BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Cos.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| Cos.getPos() | 0.0 | 1.0 | 1.0 | 1.0 |
| Cos.getPower() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expr.Expr(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expr.getTerms() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expr.setTerms(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Operator.Operator(Expr, Expr) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.Parser(HashMap) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.add(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.cons(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.mul(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.neg(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.pos(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.pow(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.sub(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Sin.Sin(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Sin.Sin(BigInteger, BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Sin.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| Sin.getPos() | 0.0 | 1.0 | 1.0 | 1.0 |
| Sin.getPower() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.Term(BigInteger, BigInteger, HashMap) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.addCeofficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.getPower() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.subCeofficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parserStr(String) | 1.0 | 1.0 | 1.0 | 10.0 |
| Parser.parserTerm(String) | 2.0 | 2.0 | 2.0 | 2.0 |
| Term.Term(String) | 2.0 | 1.0 | 1.0 | 2.0 |
| MainClass.judge(HashMap) | 3.0 | 1.0 | 2.0 | 3.0 |
| Term.find(Factor, BigInteger) | 4.0 | 3.0 | 3.0 | 4.0 |
| Cos.Cos(String) | 5.0 | 1.0 | 3.0 | 4.0 |
| Sin.Sin(String) | 5.0 | 1.0 | 3.0 | 4.0 |
| Cos.compareTo(Factor) | 6.0 | 7.0 | 4.0 | 7.0 |
| Parser.cos(String) | 6.0 | 1.0 | 4.0 | 4.0 |
| Sin.compareTo(Factor) | 6.0 | 7.0 | 4.0 | 7.0 |
| Operator.opPower(Integer) | 7.0 | 3.0 | 5.0 | 5.0 |
| Parser.sin(String) | 7.0 | 1.0 | 6.0 | 6.0 |
| Parser.parserOp(String) | 9.0 | 9.0 | 8.0 | 9.0 |
| MainClass.main(String[]) | 10.0 | 1.0 | 8.0 | 8.0 |
| Operator.opMul() | 13.0 | 5.0 | 6.0 | 6.0 |
| Operator.opAdd() | 15.0 | 4.0 | 9.0 | 9.0 |
| Operator.opSub() | 15.0 | 4.0 | 9.0 | 9.0 |
| Term.compareTo(Term) | 18.0 | 6.0 | 5.0 | 6.0 |
| MainClass.outneg(ArrayList, StringBuilder) | 21.0 | 1.0 | 10.0 | 10.0 |
| MainClass.outpos(ArrayList, StringBuilder) | 22.0 | 1.0 | 11.0 | 11.0 |
| MainClass.print(HashMap, StringBuilder) | 29.0 | 1.0 | 11.0 | 11.0 |
| Operator.mulTri(ArrayList>) | 39.0 | 1.0 | 17.0 | 17.0 |
| Total | 245.0 | 90.0 | 160.0 | 182.0 |
类复杂度:
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Cos | 2.2857142857142856 | 7.0 | 16. |
| Expr | 1.0 | 1.0 | 3.0 |
| MainClass | 8.4 | 11.0 | 42.0 |
| Operator | 7.666666666666667 | 16.0 | 46.0 |
| Parser | 3.076923076923077 | 11.0 | 40.0 |
| Sin | 2.2857142857142856 | 7.0 | 16.0 |
| Term | 1.8888888888888888 | 6.0 | 17.0 |
| Total | 180.0 | ||
| Average | 3.6 | 8.428571428571429 | 25.714285714285715 |
由于第一次作业残留的问题没有改变导致MainClass的复杂度依旧很高,同时,由于结构的单一化和计算和化简的耦合,同时第二次作业的结构更加复杂,使得计算类中的四种方法的复杂度也很大。
3. Homework 3
3.1 作业要求
第三次作业和第二次作业相比添加嵌套括号,取消三角函数和自定义函数内参数的类型限制,取消部分嵌套限制。
3.2 架构分析
第三次作业我认为和第二次作业的迭代效果最为明显,总体结构在第二次作业上需要做的修改相对要少,主要是增加了多次递归调用的思想和方法。
解析>>存储
表达式:

项:
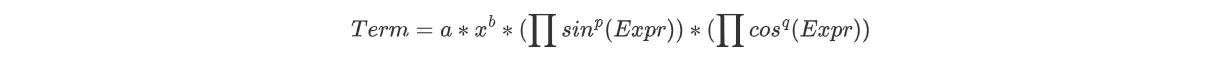
在计算的过程中,合并同类项需要调用三角函数的比较方法,三角函数的比较需要调用Expr的比较方法,Expr的比较又需要调用Term的比较方法,以此递归进行比较。
存储>>输出
因为存储出现了递归的情况,需要对输出端做一些优化,即实现输出方法的递归调用。最终要实现的是表达式的输出,由于Expr中含有三角函数,三角函数中又含有Expr,所以需要递归调用输出。同时在三角函数类的输出方法上做一些判断,如果三角函数中的Expr符合表达式因子的定义,则需要加上括号输出。
3.3 复杂度分析
方法复杂度:
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Operator.mulTri(ArrayList>) | 39.0 | 1.0 | 17.0 | 17.0 |
| Expr.type() | 28.0 | 9.0 | 9.0 | 11.0 |
| Lexer.outTri(HashMap, StringBuilder) | 35.0 | 1.0 | 11.0 | 11.0 |
| Term.compareTo(Term) | 28.0 | 10.0 | 6.0 | 10.0 |
| Lexer.outPos(ArrayList, StringBuilder) | 20.0 | 1.0 | 9.0 | 9.0 |
| Operator.opAdd() | 15.0 | 4.0 | 9.0 | 9.0 |
| Operator.opSub() | 15.0 | 4.0 | 9.0 | 9.0 |
| Parser.parserStr(String) | 9.0 | 1.0 | 9.0 | 9.0 |
| Term.isSimilar(Term) | 27.0 | 9.0 | 6.0 | 9.0 |
| Lexer.outNeg(ArrayList, StringBuilder) | 19.0 | 1.0 | 8.0 | 8.0 |
| Expr.compareTo(Expr) | 9.0 | 3.0 | 5.0 | 6.0 |
| Operator.opMul() | 13.0 | 5.0 | 6.0 | 6.0 |
| Operator.opPower(Integer) | 7.0 | 3.0 | 5.0 | 5.0 |
| Lexer.Lexer(Expr) | 4.0 | 1.0 | 4.0 | 4.0 |
| Lexer.out() | 5.0 | 2.0 | 4.0 | 4.0 |
| Parser.cos(String) | 6.0 | 1.0 | 4.0 | 4.0 |
| Parser.sin(String) | 6.0 | 1.0 | 4.0 | 4.0 |
| Cos.compareTo(Factor) | 2.0 | 3.0 | 1.0 | 3.0 |
| Expr.count(HashMap) | 3.0 | 1.0 | 2.0 | 3.0 |
| Expr.getNew() | 3.0 | 1.0 | 3.0 | 3.0 |
| Lexer.judge(HashMap) | 3.0 | 1.0 | 2.0 | 3.0 |
| Sin.compareTo(Factor) | 2.0 | 3.0 | 1.0 | 3.0 |
| Term.find(ArrayList) | 3.0 | 3.0 | 2.0 | 3.0 |
| MainClass.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| Parser.parserTerm(String) | 2.0 | 2.0 | 2.0 | 2.0 |
| Term.Term(String) | 2.0 | 1.0 | 1.0 | 2.0 |
| Cos.Cos(Expr) | 0.0 | 1.0 | 1.0 | 1.0 |
| Cos.getExpr() | 0.0 | 1.0 | 1.0 | 1.0 |
| Cos.getPos() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expr.Expr(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expr.getTerms() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expr.setTerms(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Operator.Operator(Expr, Expr) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.Parser(HashMap) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.add(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.mul(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.neg(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.nul(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.pos(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.pow(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.sub(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Sin.Sin(Expr) | 0.0 | 1.0 | 1.0 | 1.0 |
| Sin.getExpr() | 0.0 | 1.0 | 1.0 | 1.0 |
| Sin.getPos() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.Term(BigInteger, BigInteger, HashMap) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.addCeofficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.getPower() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.subCeofficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Total | 306.0 | 97.0 | 165.0 | 183.0 |
类复杂度分析:
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Cos | 1.5 | 3.0 | 6.0 |
| Expr | 3.5714285714285716 | 11.0 | 25.0 |
| Lexer | 6.333333333333333 | 11.0 | 38.0 |
| MainClass | 2.0 | 2.0 | 2.0 |
| Operator | 7.666666666666667 | 16.0 | 46.0 |
| Parser | 2.25 | 9.0 | 27.0 |
| Sin | 1.5 | 3.0 | 6.0 |
| Term | 3.0 | 10.0 | 30.0 |
| Total | 180.0 | ||
| Average | 3.6 | 8.125 | 22.5 |
通过观察,不难发现存储结构的单一会造成一些类和方法的复杂度呈现惊人的数值。这说明我的结构并没有体现更加多元和具体的层次化。
4. UML类图和评价
三次作业的架构大体相同,在这里附上第三次作业的UML类图:
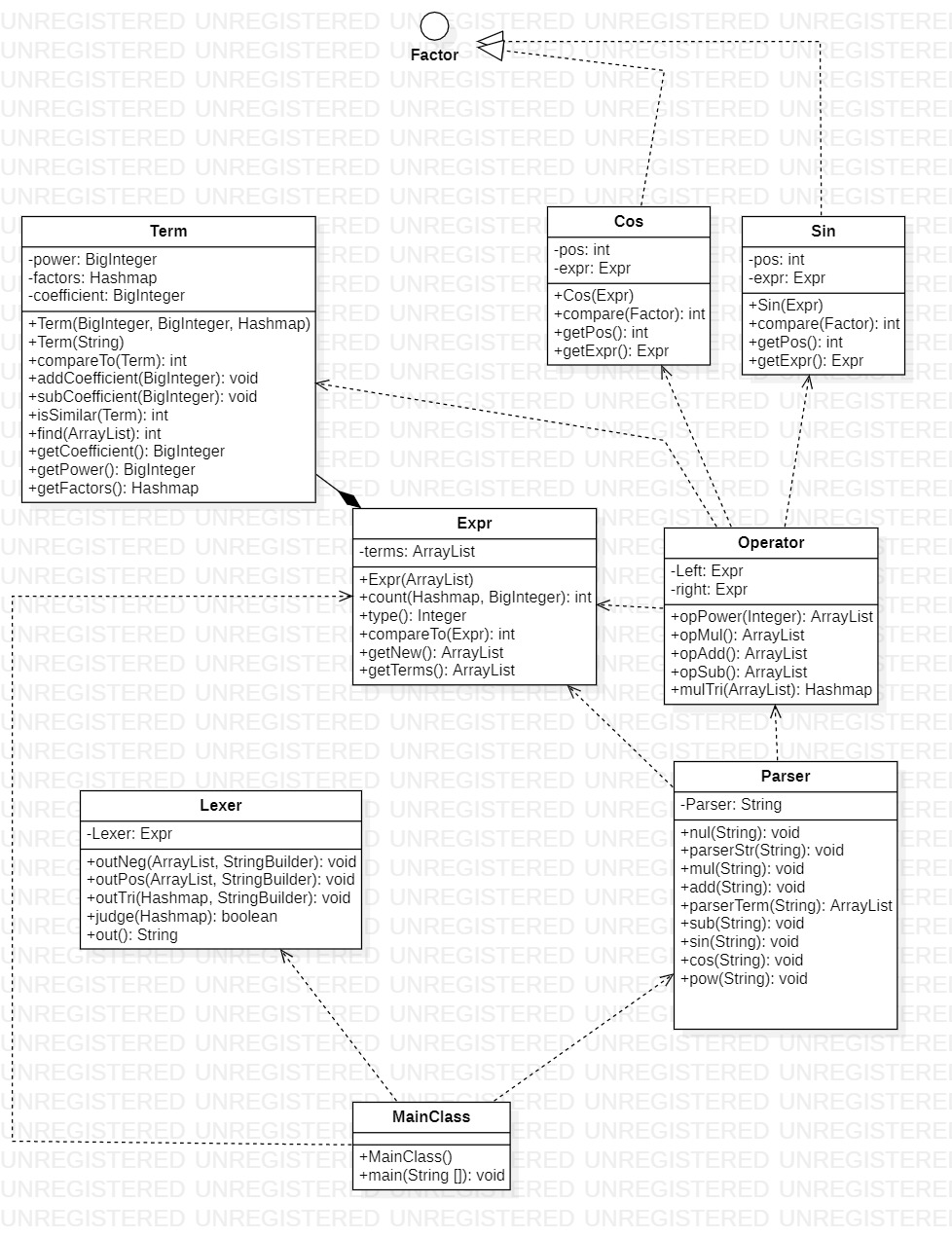
三、Bug分析
1.Bug
1.1 分析bug策略
1.先利用指导书上的基本样例测试程序的基本功能。
2.出现bug时,将代码分成三个部分,即解析、存储(包含计算过程)和输出,分别设置断点,观察三部分的容器内的对象是否是自己想要的,再进行细致寻找bug。
1.2 三次作业的bug
Homework 1: 因为还未弄清深克隆和浅克隆的区别,导致计算时各种数据的管理没做好。通过讨论区解决了问题;
Homework 2: 由于第一次提交的版本延用了第一次作业的指数用Integer类型,导致在跑同学给的测试点时出问题了,对整个程序的相关类型都进行了BigInteger的替换。
Homework 3: 第一次由于疏忽没有注意合并同类项时并不是相等的项进行合并(系数可以不一样)。
2.Debug
拿到代码后,先测试几组自己测试代码的样例,确保代码的基本功能(基本没问题),然后还是从解析、计算和优化三个方面测试,特别是优化的地方(不仅优化的地方容易出现逻辑上的bug,也可以学习同学优化的方法)。最后就是数据边界点的测试。
四、架构设计体验
从第一次作业到第三次作业的迭代,我充分体验到了“从无到有”的过程。我觉得三次作业里面,第一次作业的架构与设计的过程是最让我煎熬的一次,由于刚刚接触这类问题,脑子里面虽然有很多想法,比如以什么样的结构进行存储、如何进行简化等等,但是在实现起来都充满困难。第一次作业我的架构设计持续了四天,直到周五才开始写代码。
第二次作业和第三次作业相对于第一次作业有了新的元素添加,但是我似乎只是添加了一些新的类和新的方法,在大体上的架构没有做出很大的变动。
从这三次作业看来,我的架构可以解决课程上的问题,但是从复杂度和层次化分析,我的架构看似逻辑清晰,实际上并没有很好地给更多的表达式结构分具体的层次,导致很多地方的耦合度非常高、代码量非常大,如果出现了更多的形式上的变动,我的架构可能就无法实现。同时,我并未完全地理解面向对象的思想,这看似面向对象的程序本质上保留着面向过程的痕迹。比如其实可以对各种计算分别建立一个类,我却把四种计算全部杂糅在一个类里。
五、心得体会
1.在编写代码前要充分设计架构,在设计架构时比较要考虑本次作业的功能,还要适当思考下次作业可能新加的功能。设计架构能为编写代码时带来很多便利。
2.通过本单元的学习,明白了可以通过细化结构来降低各部分的复杂度,可以更少地出现错误。
3.测试的重要性,希望能够在未来学习自动化测试。
4.面向对象的思维模式,通过代码数据合理封装、系统性处理,从而实现数据的安全性、重用性以及程序的可扩展性。这是我在本单元对面向对象思维的简单思考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号