【学习笔记】并查集应用
【学习笔记】并查集应用
以 NOI 2001 食物链 为例の两种并查集用法。
题目大意:
规定每只动物有且仅有三种可能的种类 \(A、B、C\),\(A\) 会吃 \(B\),\(B\) 会吃 \(C\),\(C\) 会吃 \(A\)。
给定 \(N\) 只动物,\(K\) 个语句。每个语句有如下两种可能的表达:
-
1 X Y表示动物 \(X\) 与动物 \(Y\) 是同类。 -
2 X Y表示动物 \(X\) 吃 \(Y\)。
每个语句可能是真话也可能是假话,每个语句是假话有三种可能:
-
\(X\) 或 \(Y\) 比 \(N\) 大。
-
表达为 \(X\) 吃 \(X\)。
-
当前的话与前面的某些真的话冲突。
请求出 \(K\) 个语句里假话的总数。
种类并查集(扩展域并查集)
先推一个讲解。
并查集能维护连通性、传递性,通俗地说,亲戚的亲戚是亲戚。
然而当我们需要维护一些对立关系,比如敌人的敌人是朋友时,正常的并查集就很难满足我们的需求。
这时,种类并查集就诞生了。
在同个种类的并查集中合并,表达他们是朋友这个含义。
在不同种类的并查集中合并,表达他们是敌人这个含义。
此题关系有三类(\(A、B、C\)),所以我们考虑建立 3 倍大小的并查集。其中 \(1 \sim n\) 表示种类 \(A\),\(n+1 \sim 2n\) 表示种类 \(B\),\(2n+1 \sim 3n\) 表示种类 \(C\)。
如果两只动物 \(x\) 和 \(y\) 是同类,那么就将 \(A_x\) 与 \(A_y\),\(B_x\) 与 \(B_y\),\(C_x\) 与 \(C_y\) 各并入一个集合内。
如果两只动物 \(x\) 吃 \(y\),那么就将 \(A_x\) 与 \(B_y\),\(B_x\) 与 \(C_y\),\(C_x\) 与 \(A_y\) 各并入一个集合内。
此时如果要表示动物 \(x\) 吃动物 \(y\),就说明 \(A_x\) 与 \(B_y\) 在同一集合中,根据对称性,其它的也一样,所以判断时只需要判一组。
- \(x\) 与 \(y\) 同类与 \(x\) 吃 \(y\) 或 \(y\) 吃 \(x\) 矛盾。
- \(x\) 吃 \(y\) 与 \(x\) 与 \(y\) 同类或 \(y\) 吃 \(x\) 矛盾。
#include <bits/stdc++.h>
using namespace std;
#define ll long long
const int N = 5e4+5;
int fa[N*3];
int find(int x){
if(fa[x] == x) return x;
return fa[x] = find(fa[x]);
}
int main(){
ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
int n, k, ans = 0; cin>>n>>k;
for(int i=1; i<=n*3; i++)
fa[i] = i;
while(k--){
int op, x, y; cin>>op>>x>>y;
if(x==y&&op==2 || x>n || y>n){
ans++;
continue;
}
if(op==1){
if(find(x)==find(y+n) || find(y)==find(x+n)){
ans++;
continue;
}
fa[find(x)] = fa[find(y)];
fa[find(x+n)] = fa[find(y+n)];
fa[find(x+n+n)] = fa[find(y+n+n)];
} else if(op==2){
if(find(x)==find(y) || find(y)==find(x+n)){
ans++;
continue;
}
fa[find(x)] = fa[find(y+n)];
fa[find(x+n)] = fa[find(y+n+n)];
fa[find(x+n+n)] = fa[find(y)];
}
}
cout<<ans;
return 0;
}
带权并查集
每个点与其集合的根都有权重,以此来表达关系。
以此题为例,0 代表 \(x\) 与 \(fa_x\) 同类,1 代表 \(x\) 吃 \(fa_x\),2 代表 \(x\) 被 \(fa_x\) 吃。
重点在于如何更新权值和判断关系。权值更新肯定伴随并查集的更新。在下面的图中就如向量一般计算。
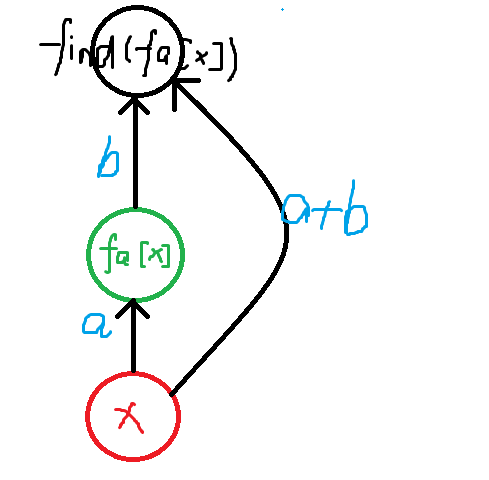
查找(路径压缩):
知道 \(x\) 与其根 \(fa[x]\) 的关系,\(fa[x]\) 与其根 \(fa[fa[x]]\) 的关系,可以推出 \(x\) 与 \(fa[fa[x]]\) 的关系。
注意这里要先更新 \(fa[x]\) 的权值(先 find(fa[x])),在更新 \(x\) 的权值(得先存下 \(fa[x]\),不然 \(fa[x]\) 会变)。
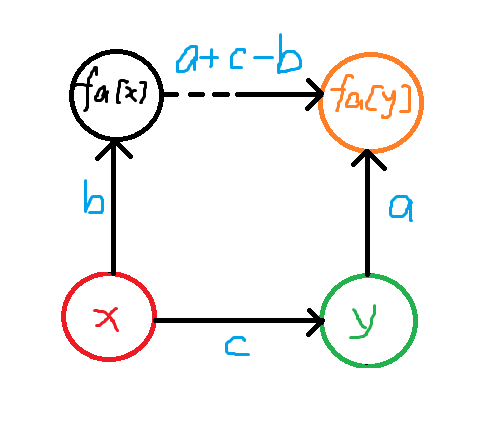
合并:
知道 \(x\) 与 \(fa[x]\) 的关系,\(y\) 与 \(fa[y]\) 的关系,以及 \(x\) 与 \(y\) 之间的关系,就可以知道 \(fa[x]\) 和 \(fa[y]\) 的关系。
注意是 \(fa[x]\) 并到 \(fa[y]\) 上还是 \(fa[y]\) 并到 \(fa[x]\) 上。以下是 \(fa[x]\) 并到 \(fa[y]\) 上。
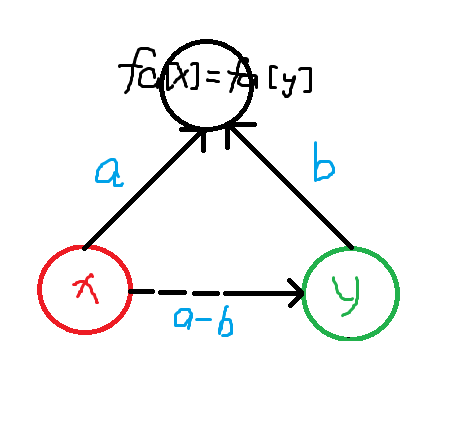
判断关系(是否矛盾):
知道 \(x、y\) 与根的关系,就能推出 \(x\) 与 \(y\) 的关系。(此时 \(x\) 与 \(y\) 已经在同一个集合内)
以上操作取模时注意减法,显然此题模数为 \(3\)。
#include <bits/stdc++.h>
using namespace std;
#define ll long long
const int N = 50005;
int fa[N], rel[N];
// relation 存与根的关系
// 0--同类,1--能吃,2--被吃
const int p = 3;
int n, k, ans;
void init(){
for(int i=1; i<=n; i++){
fa[i] = i;
rel[i] = 0;
// 初始化跟自己的关系是同类
}
}
int find(int x){
if(fa[x] == x) return x;
// 知道 x 与 fa[x] 的关系,fa[x] 与根的关系,可以推出 x 与根的关系
// rel[x->rt] = rel[x->fa]+rel[fa->rt]
int f = fa[x];
fa[x] = find(fa[x]);
rel[x] = (rel[x]+rel[f])%p;
// 必须得分开写,因为原来的 fa[x] 与根的关系会在 find(fa[x]) 的时候更新
return fa[x];
}
void merge(int u, int v, int r){
// U与rtU的关系,V与rtV的关系,以及UV之间的关系,就可以知道rtU和rtV的关系。
// rtU 并到 rtV 上
// rel[ru] = rel[v]-rel[u]+rel[u->v]
int ru = find(u), rv = find(v);
if(ru != rv){
fa[ru] = rv;
rel[ru] = (rel[v]-rel[u]+r+p)%p;
}
}
bool check(int x, int y, int r){
if(x>n || y>n) return false; // 不能比 n 大
if(x==y && r==1) return false; // 不能吃自己
if(find(x)==find(y)){
// 知道x、y与根的关系,就能推出 x 与 y 的关系
// rel[x->y] = rel[x]-rel[y]
return r == (rel[x]-rel[y]+p)%p;
}
return true;
// 还没明确的关系就是可行的
}
int main(){
ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
cin>>n>>k;
init();
while(k--){
int op, x, y; cin>>op>>x>>y;
if(check(x, y, op-1)){
merge(x, y, op-1);
} else{
ans++;
}
}
cout<<ans;
return 0;
}
以上就是这道题的两种并查集写法。
再推荐一题:
P4374 [USACO18OPEN] Disruption P
题目大意:给出一棵 \(n\) 个点的树,边权为 1。给出 \(m\) 个点对,代表一条待选边,有整数边权 \(w_i\) 如果把树上某一条边删掉,则会形成两个不连通的集合。
对于树上所有边,求解把该边删掉后,所有能重新使两个集合联通的待选边中边权最小的是多少?
\(1\leq n,m\leq10^6\text{,}1\leq w_i\leq10^9\)
思路:
对特殊边按边权升序排序。考虑特殊边 \((u,v)\) 能成为哪些树上边的答案。去掉一条边加上 \((u,v)\) 后原图仍为树,不难发现去掉的这条边必须在 \([u,v]\) 的树上路径上。其次,当这条树边的答案已经确定后,不需要再考虑这条边断开的情况,于是可以用并查集合并两个端点。
设 \(f_i\) 表示 \(i\) 到根的路径中第一个未被覆盖的边,那么每次加边操作,我们就暴力跳并查集。覆盖了一条边后,将这条边对应结点的 \(f\) 与父节点合并。这样,每条边至多被覆盖一次。
#include <bits/stdc++.h>
using namespace std;
#define ll long long
const int N = 50005;
#define pii pair<int, int>
#define fi first
#define se second
vector<pii> g[N];
int dep[N], son[N], dad[N], sz[N], pos[N];
int top[N], dfn[N], T;
void dfs1(int u, int f){
dep[u] = dep[f]+1;
sz[u] = 1;
dad[u] = f;
int maxson = -1;
for(auto [v, id] : g[u]){
if(v == f) continue;
pos[id] = v;
dfs1(v, u);
sz[u] += sz[v];
if(maxson < sz[v]){
maxson = sz[v];
son[u] = v;
}
}
}
void dfs2(int u, int topf){
dfn[u] = ++T;
top[u] = topf;
if(!son[u]) return;
dfs2(son[u], topf);
for(auto [v, id] : g[u]){
if(!dfn[v])
dfs2(v, v);
}
}
int LCA(int u, int v){
while(top[u] != top[v]){
if(dep[top[u]] < dep[top[v]])
swap(u, v);
u = dad[top[u]];
}
return dep[u]<dep[v] ? u : v;
}
struct node{
int u, v, w;
}e[N];
int fa[N], ans[N];
int find(int x){
if(x == fa[x]) return x;
return fa[x] = find(fa[x]);
}
int main(){
ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
int n, m; cin>>n>>m;
for(int i=1; i<n; i++){
int u, v; cin>>u>>v;
g[u].push_back({v, i});
g[v].push_back({u, i});
}
dfs1(1, 0);
dfs2(1, 1);
for(int i=1; i<=m; i++)
cin>>e[i].u>>e[i].v>>e[i].w;
sort(e+1, e+m+1, [&](node a, node b){
return a.w < b.w;
});
for(int i=1; i<=n; i++){
fa[i] = i;
ans[i] = -1;
}
for(int i=1; i<=m; i++){
int fu = find(e[i].u), fv = find(e[i].v);
int lca = LCA(e[i].u, e[i].v);
while(dep[fu] > dep[lca]){
ans[fu] = e[i].w;
fa[fu] = dad[fu];
fu = find(fu);
}
while(dep[fv] > dep[lca]){
ans[fv] = e[i].w;
fa[fv] = dad[fv];
fv = find(fv);
}
}
for(int i=1; i<n; i++)
cout<<ans[pos[i]]<<"\n";
return 0;
}
此外,这题还能树剖线段树:区间修改求最小 + 区间查询最小值来解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号