
了解pytorch读取图片的流程和机制。
1,Dataset类
2,制作图片数据的索引
3,构建自定义Dataset类
Dataset类
pytorch读取图片,主要通过Dataset类。Dataset类作为所有的dataset的基类存在,所有的datasets都需要继承它。
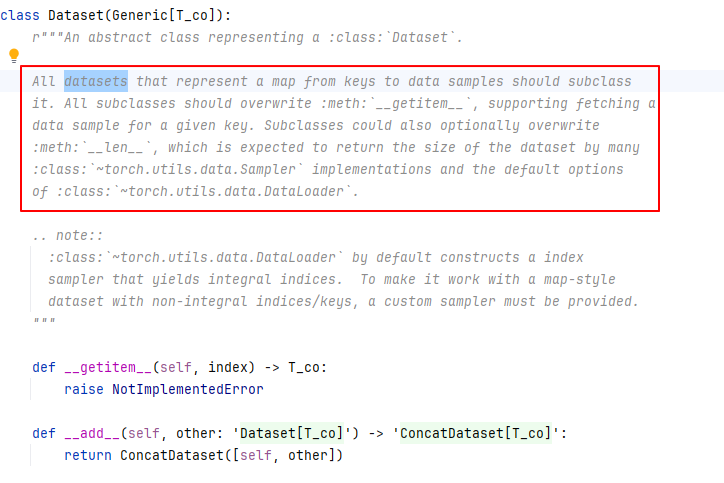
所有的子类,都要重写getitem函数和len函数。
from torch.utils.data import Dataset import os from PIL import Image class mydata(Dataset): def __init__(self,root_dir,label_dir): self.root_dir=root_dir self.label_dir=label_dir self.path=os.path.join(root_dir,label_dir) self.img_path=os.listdir(self.path) def __getitem__(self, idx): img_name=self.img_path[idx] img_item_path=os.path.join(self.root_dir,self.label_dir,img_name) img=Image.open(img_item_path) label=self.label_dir return img,label # 返回图片和标签 def __len__(self): return len(self.img_path) root_dir='dataset/train' label_dir='ants' data=mydata(root_dir,label_dir)
# coding: utf-8 from PIL import Image from torch.utils.data import Dataset """ 构建Dataset子类, pytorch读取图片,主要是通过Dataset类,Dataset类作为所有的datasets的基类存在,所有的datasets都需要继承它,类似于c++中的虚基类。 """ class MyDataset(Dataset): # 继承Dataset类 def __init__(self, txt_path, transform=None, target_transform=None): # 定义txt_path参数 fh = open(txt_path, 'r') # 读取txt文件 imgs = [] # 定义imgs的列表 for line in fh: line = line.rstrip() # 默认删除的是空白符('\n', '\r', '\t', ' ') words = line.split() # 默认以空格、换行(\n)、制表符(\t)进行分割,大多是"\" imgs.append((words[0], int(words[1]))) # 存放进imgs列表中 self.imgs = imgs # 最主要就是要生成这个list, 然后DataLoader中给index,通过getitem读取图片数据 self.transform = transform self.target_transform = target_transform def __getitem__(self, index): fn, label = self.imgs[index] # fn代表图片的路径,label代表标签 img = Image.open(fn).convert('RGB') # 像素值 0~255,在transfrom.totensor会除以255,使像素值变成 0~1 参考:https://blog.csdn.net/icamera0/article/details/50843172 if self.transform is not None: img = self.transform(img) # 在这里做transform,转为tensor等等 return img, label def __len__(self): return len(self.imgs) # 返回图片的长度
img = Image.open(fn).convert('RGB') 如果不使用.convert('RGB')进行转换的话,读出来的图像是RGBA四通道的,A通道为透明通道,该对深度学习模型训练来说暂时用不到,因此使用convert('RGB')进行通道转换。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号