
scheduler实例化后,可以启动(start)、暂停(stand-by)、停止(shutdown)。scheduler被停止后,除非重新实例化,否则不能重新启动;只有当scheduler启动后,即使处于暂停状态也不行,trigger才会被触发(job才会被执行)。Scheduler的生命周期,从SchedulerFactory创建它时开始,到Scheduler调用shutdown()方法时结束;Scheduler被创建后,可以增加、删除和列举Job和Trigger,以及执行其他与调度相关的操作(如暂停Trigger)。
SchedulerFactory schedulerFactory=new org.quartz.impl.StdSchedulerFactory(); Scheduler scheduler=schedulerFactory.getScheduler(); //define the job and tie it to our HelloJob class JobDetail jobDetail=JobBuilder.newJob(HelloJob.class) .withIdentity("myJob","myGroup") .build(); //Trigger the job to run now, and then every 40 seconds Trigger trigger=TriggerBuilder.newTrigger() .withIdentity("myTrigger","triggerGroup") .startNow() .withSchedule(simpleSchedule() .withIntervalInSeconds(40) .repeatForever()) .build(); //Tell quartz to schedule the job using the trigger scheduler.scheduleJob(job,trigger); scheduler.start();
Quartz API的关键接口是:
1)Scheduler 与调度程序交互的主要API。
2)Job 由希望由调度程序执行的组件实现的接口。
3)JobDetail 用于定义作业的实例
4)Trigger 定义执行给定作业的计划的组件
5)JobBuilder 用于定义/构建JobDetail实例,用于定义作业的实例。
6)TriggerBuilder 用于定义/构建触发器实例。
Job和Trigger
一个job就是一个实现了Job接口的类,该接口只有一个方法:
package org.quartz; public interface Job{ public void execute(JobExecutionContext context) throws JobExecutionException; }
当Job的一个Trigger被触发时,execute()方法由调度程序的一个工作线程调用。传递给execute()方法的JobExecutionContext对象向作业实例提供有关其“运行时”Job的一个trigger被触发后,execute()方法会被scheduler的一个工作线程调用;传递给execute()方法的JobExecutionContext对象中保存着该job运行时的一些信息:执行job的scheduler的引用,触发job的trigger的引用,JobDetail对象引用,以及一些其他信息。
定义了一个实现Job接口的类,这个类仅仅表明该job需要完成什么类型的任务,除此之外,Quartz还需要知道该job实例所包含的属性;这将由JobDetail类来完成,而JobDetail实例时通过JobBuilder类来创建的。
创建JobDetail时,将要执行的job的类名传给JobDetail,所以scheduler就知道了要执行何种类型的job;每次当scheduler执行job时,在调用execute()方法之前会创建该类的一个新的实例;执行完毕,对该实例的引用就被丢弃掉,实例会被垃圾回收;这种执行策略带来的一个后果是,job必须有一个午餐的构造函数(当使用默认的JobFactory时);另一个后果是,在job类中,不应该定义有状态的数据属性,因为在job的多次执行中,这些属性的值都不会保留。而是通过JobDataMap给job实例增加属性或配置,跟踪job的状态。
JobDataMap中可以包含无限量的(序列化的)数据对象,在job实例执行的时候,可以使用其中的数据;JobDataMap是java Map接口的一个实现,额外增加了一些便于存取剧本类型的数据的方法。
在job执行时,JobExecutionContext中的JobDataMap提供了很多的便利。它是JobDetail中的JobDataMap和Trigger中的JobDataMap的并集,但是如果存在相同的数据,则后者会覆盖前者的值。
只创建一个job类,然后创建多个与该job关联的JobDetail实例,每个实例都有自己的属性集和JobDataMap,最后将所有的实例都加到scheduler中。当一个trigger被触发时,与之关联的JobDetail实例会被加载,JobDetail引用的job类通过配置在Scheduler上的JobFactory进行初始化。
Trigger最常用的的有两种:SimpleTrigger和CronTrigger
Trigger的公共属性:
1)jobKey属性:当trigger触发时被执行的job的身份。
2)startTime属性:设置trigger第一次触发的时间。
3)endTime属性:表示trigger失效的时间点。
4)优先级(Priority):只有同时触发的trigger之间才会比较优先级。如果trigger是可恢复的,在恢复后再调度时,优先级与原trigger是一样的。
5)错过触发(misfire Instructions):如果scheduler关闭了,或者Quartz线程池中没有可用的线程来执行job,此时持久性的trigger就会错过(miss)其触发时间,即错过触发(misfire)。不同类型的trigger,有不同的misfire机制,它们默认使用“智能机制(smart policy)”,即根据trigger的类型和配置动态调整行为。当scheduler启动的时候,查询所有错过触发(misfire)的持久性trigger。然后根据它们各自的misfire机制更新trigger的信息。
6)日历示例(calendar):Quartz的Calendar对象(不是java.util.Calendar对象)可以在定义和存储trigger的时候与trigger进行关联。Calendar用于从trigger的调度计划中排除时间段。
Calendar接口如下:
package org.quartz; public interface Calendar { public boolean isTimeIncluded(long timeStamp); public long getNextIncludedTime(long timeStamp); }
Calendar必须先实例化,然后通过addCalendar()方法注册到scheduler。如果使用HolidayCalendar,实例化后,需要调用addExcludedDate(Date date)方法从调度计划中排除时间段。
HolidayCalendar cal = new HolidayCalendar(); cal.addExcludedDate( someDate ); cal.addExcludedDate( someOtherDate ); sched.addCalendar("myHolidays", cal, false); Trigger t = newTrigger() .withIdentity("myTrigger") .forJob("myJob") .withSchedule(dailyAtHourAndMinute(9, 30)) // execute job daily at 9:30 .modifiedByCalendar("myHolidays") // but not on holidays .build(); // .. schedule job with trigger Trigger t2 = newTrigger() .withIdentity("myTrigger2") .forJob("myJob2") .withSchedule(dailyAtHourAndMinute(11, 30)) // execute job daily at 11:30 .modifiedByCalendar("myHolidays") // but not on holidays .build(); // .. schedule job with trigger2
Simple Trigger
SimpleTrigger可以满足的调度需求是:在具体的时间点执行一次,或者在具体的时间点执行,并且以指定的间隔重复执行若干次。
SimpleTrigger的属性包括:开始时间、结束时间、重复次数以及重复的间隔。重复次数,可以是0、正整数,以及常量SimpleTrigger.REPEAT_INDEFINITELY。重复的间隔,必须是0,或者是long型的正数,表示毫秒。注意,如果重复间隔为0,trigger将会以重复次数并发执行(或者以scheduler可以处理的*似并发数)。
CronTrigger
cronTrigger基于日历的概念进行重新启动的作业启动计划。CronTrigger有一个startTime,它指向何时生效,以及一个(可选的)endTime,用于指定何时停止计划。
Cron Expressions
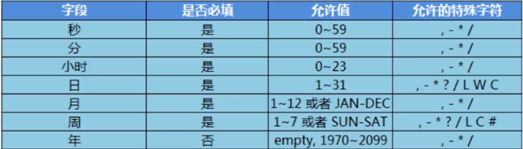
Cron-Expressions用于配置CronTrigger的实例。Cron Expressions是由七个子表达式组成的字符串,用于描述日程表的各个细节。
1.Seconds 有效值(0~59)
2.Minutes 有效值(0~59)
3.Hours 有效值(0~23)
4.Day-of-Month 有效值(1~31)
5.Month 有效值(0~11 或使用字符串JAN,FEB,MAR,APR,MAY,JUN,JUL,AUG,SEP,OCT,NOV和DEC)
6.Day-of-Week 有效值(1~7或者使用字符串SUN,MON,TUE,WED,THU,FRI和SAT) 1对应的是星期日
7.Year(optional filed)
'/'字符可用于指定值的增量。例如,如果在“分钟”字段中输入“0/15”,则表示“每隔15分钟,从零开始”。如果您在“分钟”字段中使用“3/20”,则意味着“每隔20分钟,从三分钟开始” - 换句话说,它与“分钟”中的“3,23,43”相同领域。请注意“ / 35”的细微之处并不代表“每35分钟” - 这意味着“每隔35分钟,从零开始” - 或者换句话说,与指定“0,35”相同。
'?' 字符是允许的日期和星期几字段。用于指定“无特定值”。当您需要在两个字段中的一个字段中指定某个字符而不是另一个字段时,这很有用。
“L”字符允许用于月日和星期几字段。这个角色对于“最后”来说是短暂的,但是在这两个领域的每一个领域都有不同的含义。例如,“月”字段中的“L”表示“月的最后一天” - 1月31日,非闰年2月28日。如果在本周的某一天使用,它只是意味着“7”或“SAT”。但是如果在星期几的领域中再次使用这个值,就意味着“最后一个月的xxx日”,例如“6L”或“FRIL”都意味着“月的最后一个星期五”。您还可以指定从该月最后一天的偏移量,例如“L-3”,这意味着日历月份的第三个到最后一天。
“W”用于指定最*给定日期的工作日(星期一至星期五)。例如,如果要将“15W”指定为月日期字段的值,则意思是:“最*的*日到当月15日”。
'#'用于指定本月的“第n个”XXX工作日。例如,“星期几”字段中的“6#3”或“FRI#3”的值表示“本月的第三个星期五”。
可以通过一些Cron在线工具非常方便的生成Cron-Expressions。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号