
分布式 基本理论 CAP 2
关于P
P, 即 Partition字面意思是网络分区,其实 包括了 各种网络问题, 我们要把它理解 一个 广义的 分区问题。
P 涉及到了 时间, 这么说吧, 出现了分区, 那就是节点之间 “长久的” 不能通信, 出现 延迟、超时 就是 “暂时的” 不能通信 —— 到底多久才算是 超时呢? 所以说, 我们 通常需要 对 分布式系统 设定个 响应的 时间期限。(—— 其实这就增加的CAP 理解的难度)
P 是指系统必须要容易分区, 也就是 通常所谓的 分区容忍性, 也就是 允许失败的 节点个数。 从量化的理论来讲, 允许失败的 节点个数越多, 分区容忍性越好, P 值越高。
P 的理解 非常有技巧。P 恰恰 说明的是 可以允许 分区存在或 节点失败。 但是, 其实, 我们 容不容忍 都是TM 没有选择余地的!
出现分区问题的时候,可能出现2个分区, 也可能3个, 那么如何选择其中一个呢? 谁来做这个决定呢? 首先, 肯定是系统内部来决定的, 通常, 我们需要在分布式系统中设置一个 master, master 又是怎么来的呢? 是选举出来的! 如果出现了分区, 那 master 还是master 吗? 不是了, 我们需要重新选举? 选举又是如何进行的呢? 我们需要考虑 各种选举算法。
关于A、C
C和A之间选择不是0和1的选择,而是一种连续式选择
从上面的例子看,好像选择C就必须放弃A,反之亦然。但是其实所有这些都有中间方案。C和A的定义也有各种灰度定义。
比如C的定义,最严格的定义就是一个分布式事务结束后,所有的副本在任何时刻都是一致的。但是这个定义可以放宽。时间不在是同时,而是一段时间,给一个时间窗口。或者一阶段内可以不一致,但最终变成一致的。比如上面的例子中,在发生分区的时候,可以暂时不一致,等到通信问题解决了,开始恢复一致性。
而对于A的定义来说,也是有各种层次,在发生分区的时候,可以选择限制部分操作,同时提供一个些事后比较好恢复的操作。
一种经典的系统设计模式
因为在分布式系统中,基本是没有办法选择不要分区的,所以为了保证系统的可用性,和一致性的博弈,经典的设计模式就是分情况对待。当不发生分区的时候保证完美的CA,到出现了分区,进入分区模式,等待分区恢复后,恢复系统,最终达到一致性后,再次进入完美CA状态。
--------------------- 作者:miniDan__ 来源:CSDN 原文:https://blog.csdn.net/physicsdandan/article/details/52118565 版权声明:本文为博主原创文章,转载请附上博文链接!
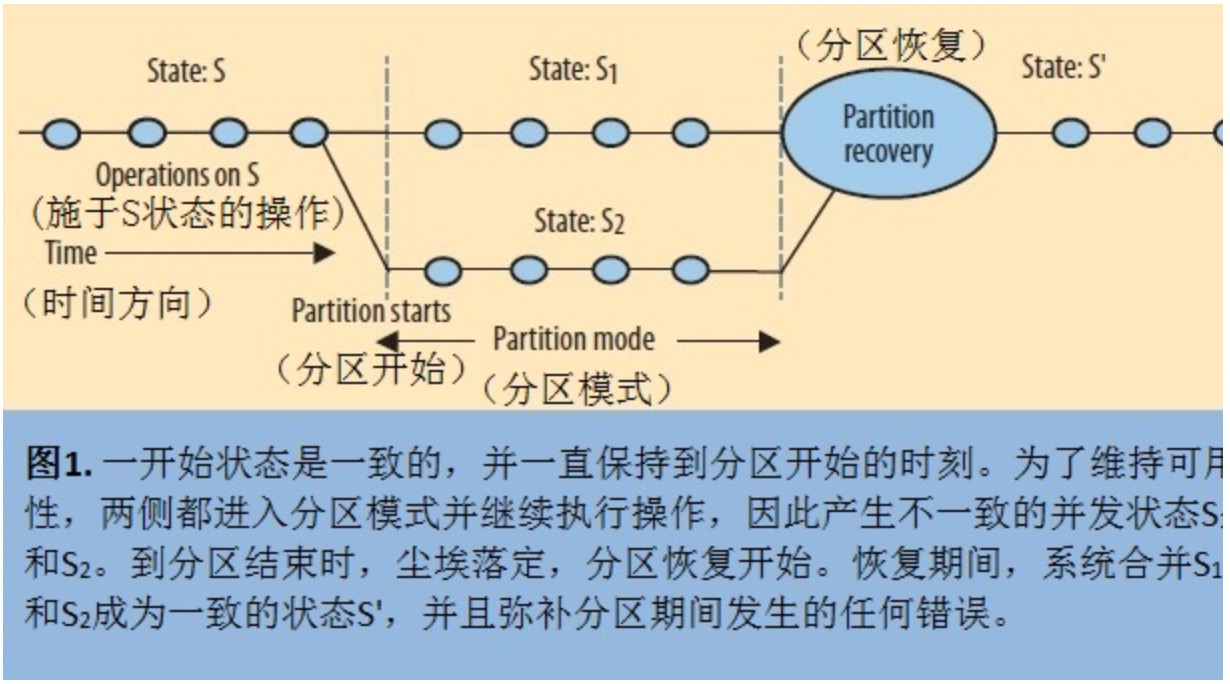
1 检测到分区开始
2 明确进入分区模式,限制某些操作,并且
3 当通信恢复后启动分区恢复过程
最后一步的目的是恢复一致性,以及补偿在系统分区期间程序产生的错误。
当系统进入到分区模式,它有两种可行的策略。其一是限制部分操作,因此会削弱可用性。其二是额外记录一些有利于后面分区恢复的操作信息。系统可通过持续尝试恢复通信来察觉分区何时结束。
小结
CAP 还是有一定的复杂性的,因为它是基础的理论, 当我们把各种问题考虑进去之后。情况变得复杂起来。
总之,CAP是非常骚的 理论, 非常扯淡、折腾人的理论。找到一些证据:
就是一个很混乱且缺乏解释力的理论,那么较劲干啥。
理论的原意大概是说你不可能设计一个系统在保证出现一些网络交换器故障导致一些批网络节点无法和另一批节点通信的情况下P依然保证数据一致性C,且保证服务可用A。
这理论听听就行了。如果你是个这个领域的新人,学会大规模系统里需要考虑交换机和路由器坏掉的情况就可以了。

参考:
https://www.zhihu.com/question/54105974?from=profile_question_card
https://blog.csdn.net/physicsdandan/article/details/52118565

 浙公网安备 33010602011771号
浙公网安备 33010602011771号