NBA球员信息获取
昨天介绍了一个不用写代码的web项目,今天说一下数据的获取。
球员信息网站:https://nba.hupu.com/players/
首先进行页面的分析:
此图片的url:https://nba.hupu.com/players/
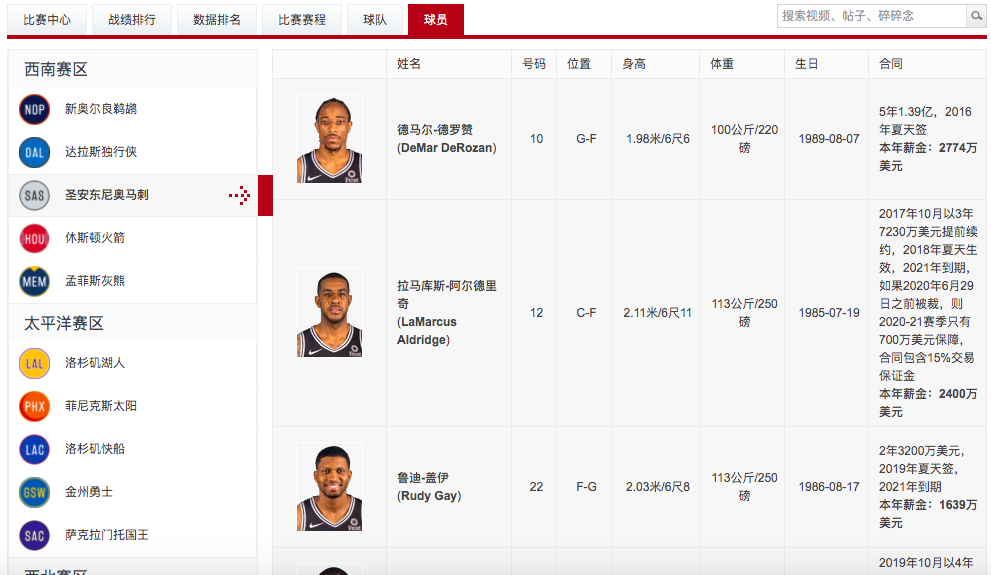
点击左边的球队url会根据球队的不同进行相应的变化:
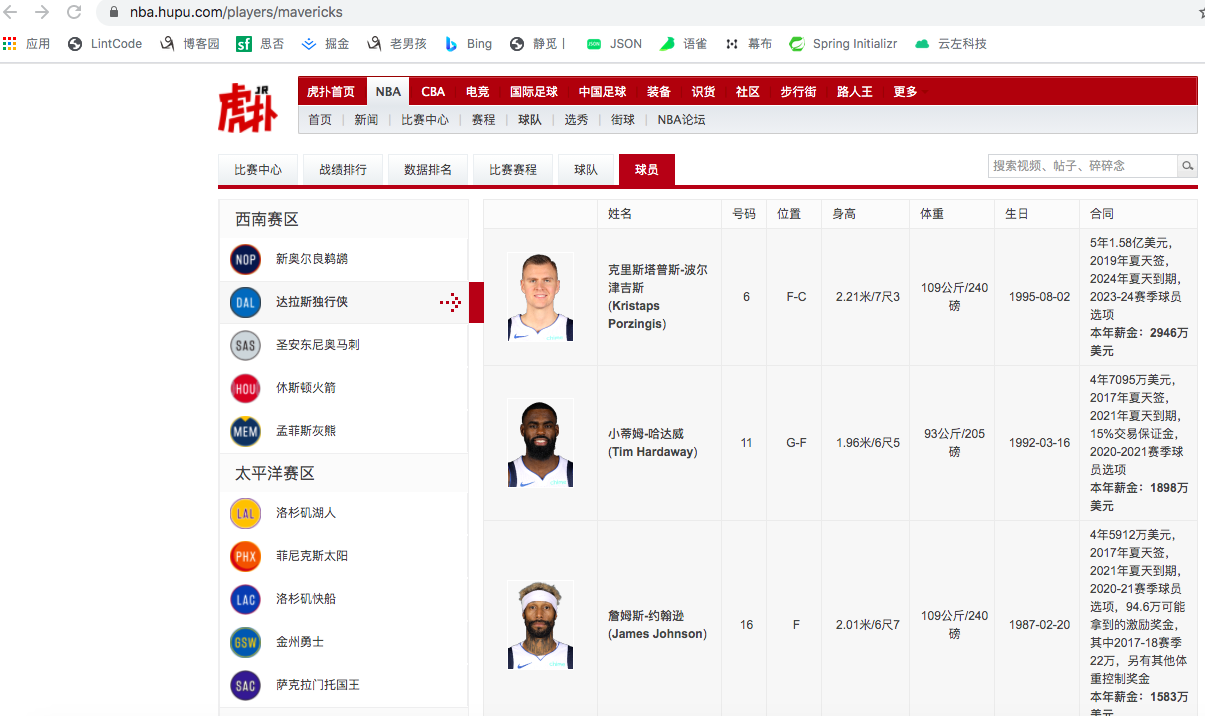
因此,我们只需要获取到所有的球队名称就能获取到所有的url信息了。
此时查看一下球队信息,对页面进行分析:
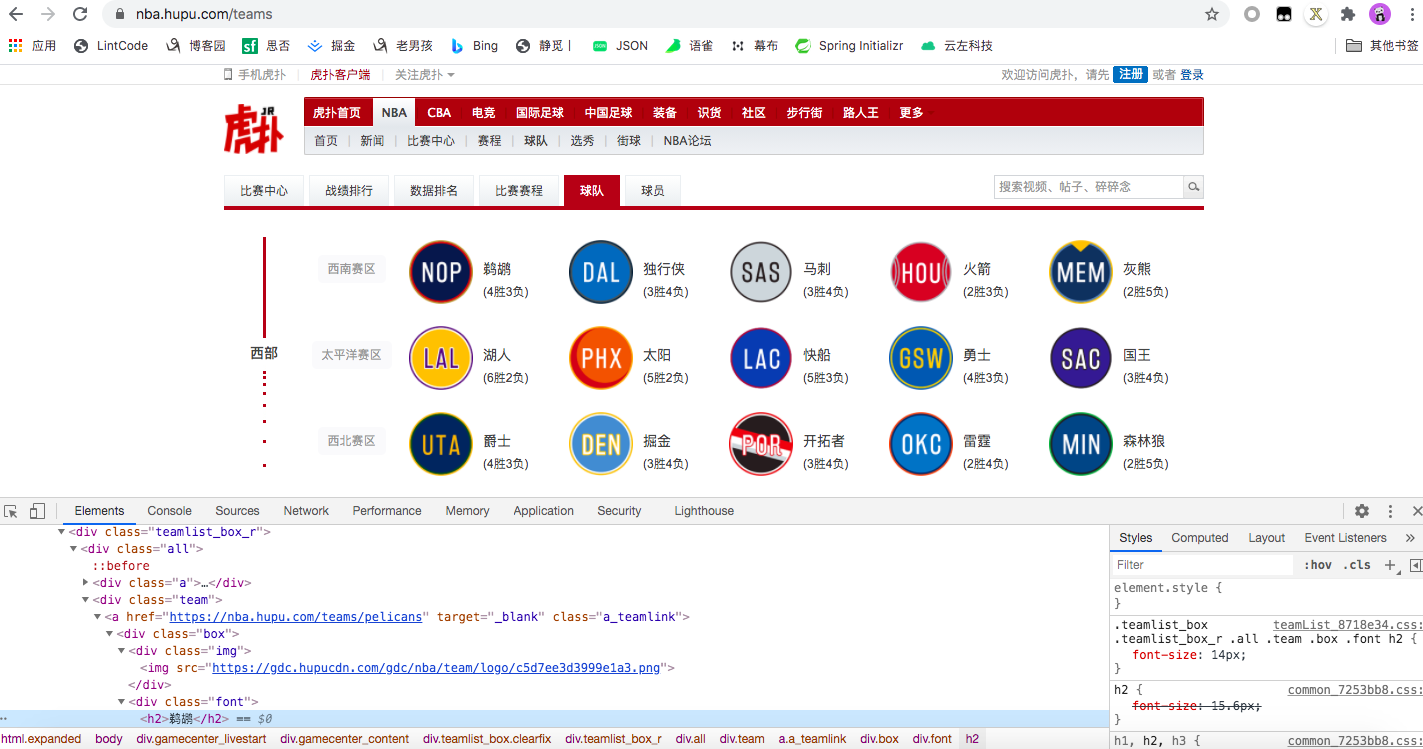
此处有球队详情的url:https://nba.hupu.com/teams/pelicans和球员信息的url比对https://nba.hupu.com/players/pelicans
发现只要将teams替换为players就获取到所有的url了
第二步:代码实现
import requests
from lxml import etree
def get_url(url):
response = requests.get(url, headers).text
dom = etree.HTML(response)
player_urls = dom.xpath('//*[@class="team"]//a/@href')
for player_url in player_urls:
player_url = "".join(player_url).replace("teams","players")
get_player(player_url)
def get_player(url):
response = requests.get(url,headers).text
dom = etree.HTML(response)
players = dom.xpath('//*[@class="players_table"]/tbody//tr')
for player in players[1:]:
cname = player.xpath('./td/b/a/text()')
ename = player.xpath('./td/p/b/text()')
num = player.xpath('./td[3]/text()')
place = player.xpath('./td[4]/text()')
height = player.xpath('./td[5]/text()')
weight = player.xpath('./td[6]/text()')
birth = player.xpath('./td[7]/text()')
ht = player.xpath('./td/b/text()')
print(cname,ename,num,place,height,weight,birth,ht)
if __name__ == '__main__':
url = 'https://nba.hupu.com/teams'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36 Edg/86.0.622.68',
}
get_url(url)
结果展示:

一共获取了500名球员信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号