XX二手车爬虫203破解
个人学习总结,有不足的地方请大佬们指出。
1、之前爬取瓜子二手车时,添加登录的cookie就可以获取页面数据。后续发现此方法不行。每次请求的时候,获取不到页面的信息,postman进行获取,结果显示203(请求成功,内容显示失败),203 (Non-Authoritative Information/非官方信息)。
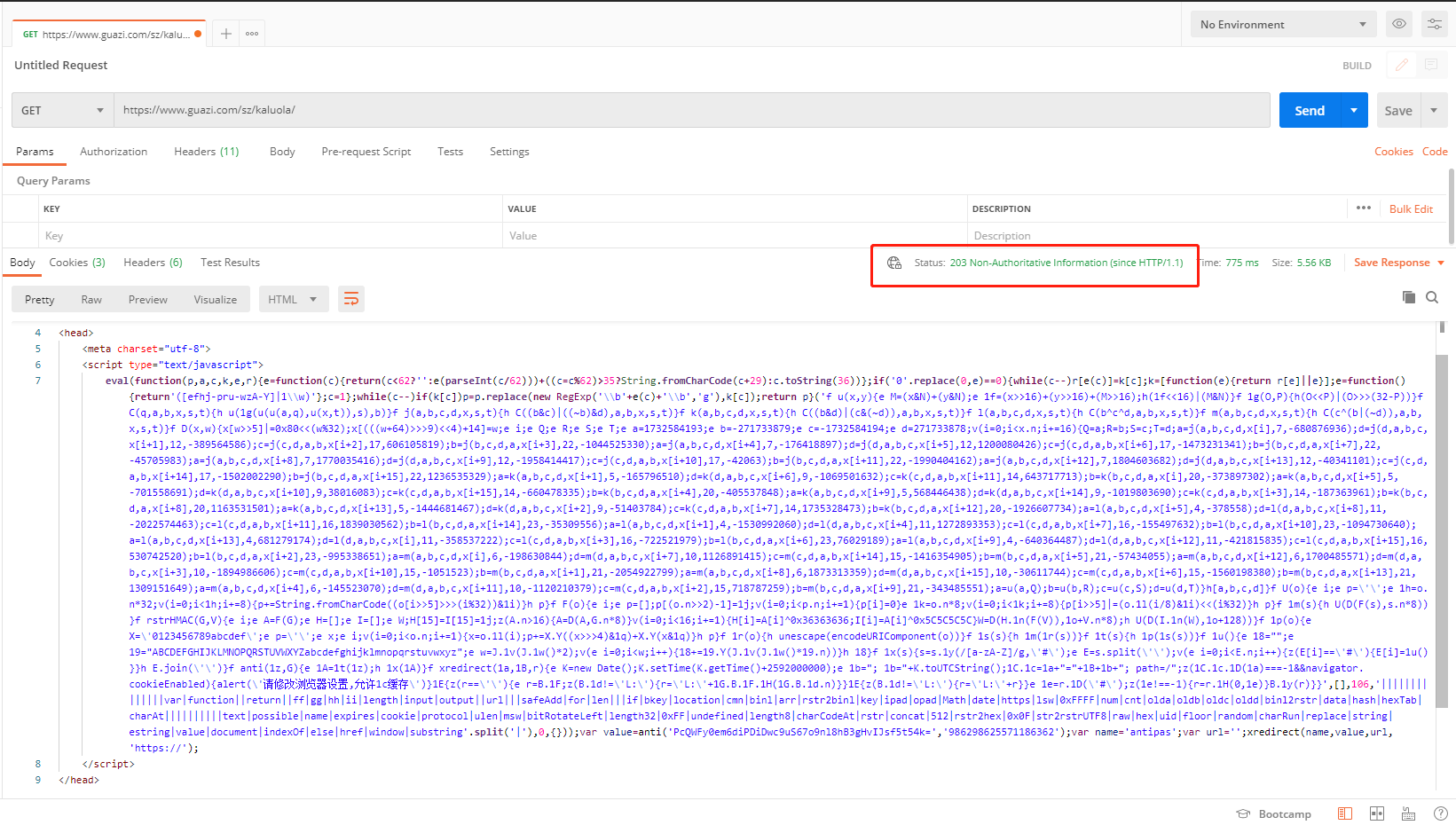
2、从postman请求结果可以看出,请求错误!因为此处是跟cookie有关,因此分析一下网页的cookie。
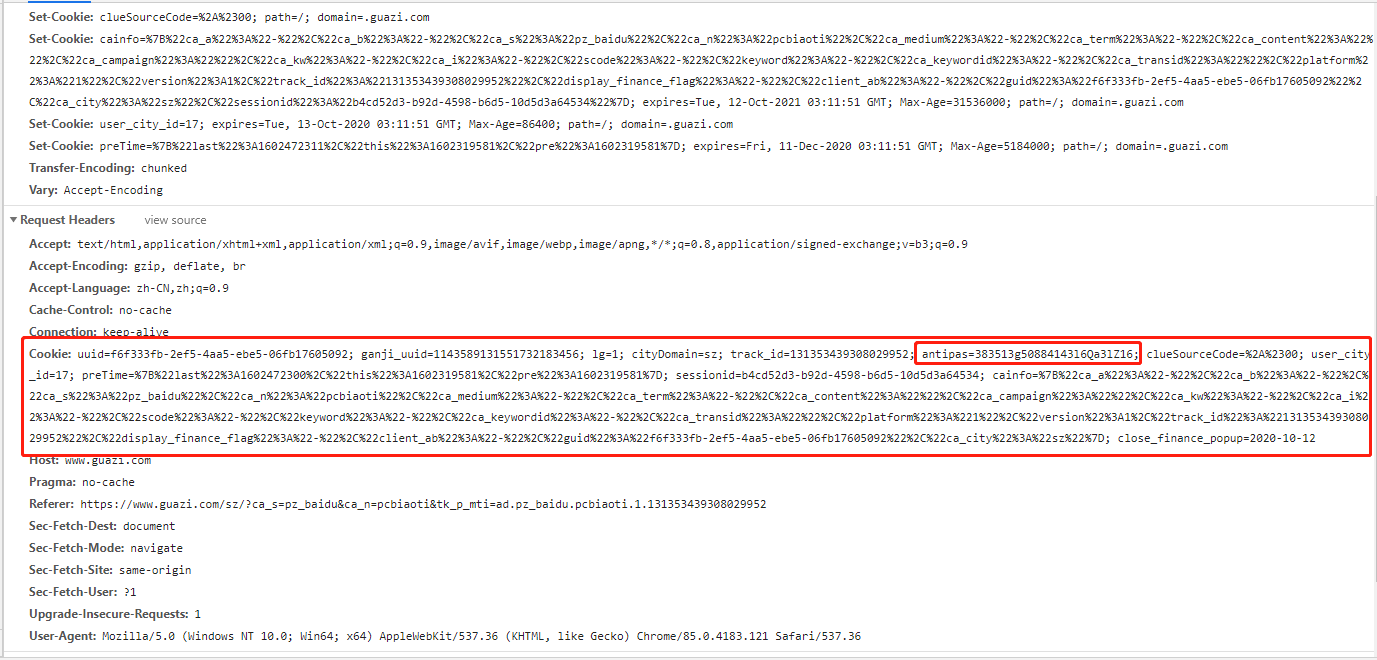
3、有关系的是cookie中的antipas,将postman中返回的代码拷贝出来,放入一个新的html中打开。进行分析。次方法避免了将混乱的js代码进行扣取。
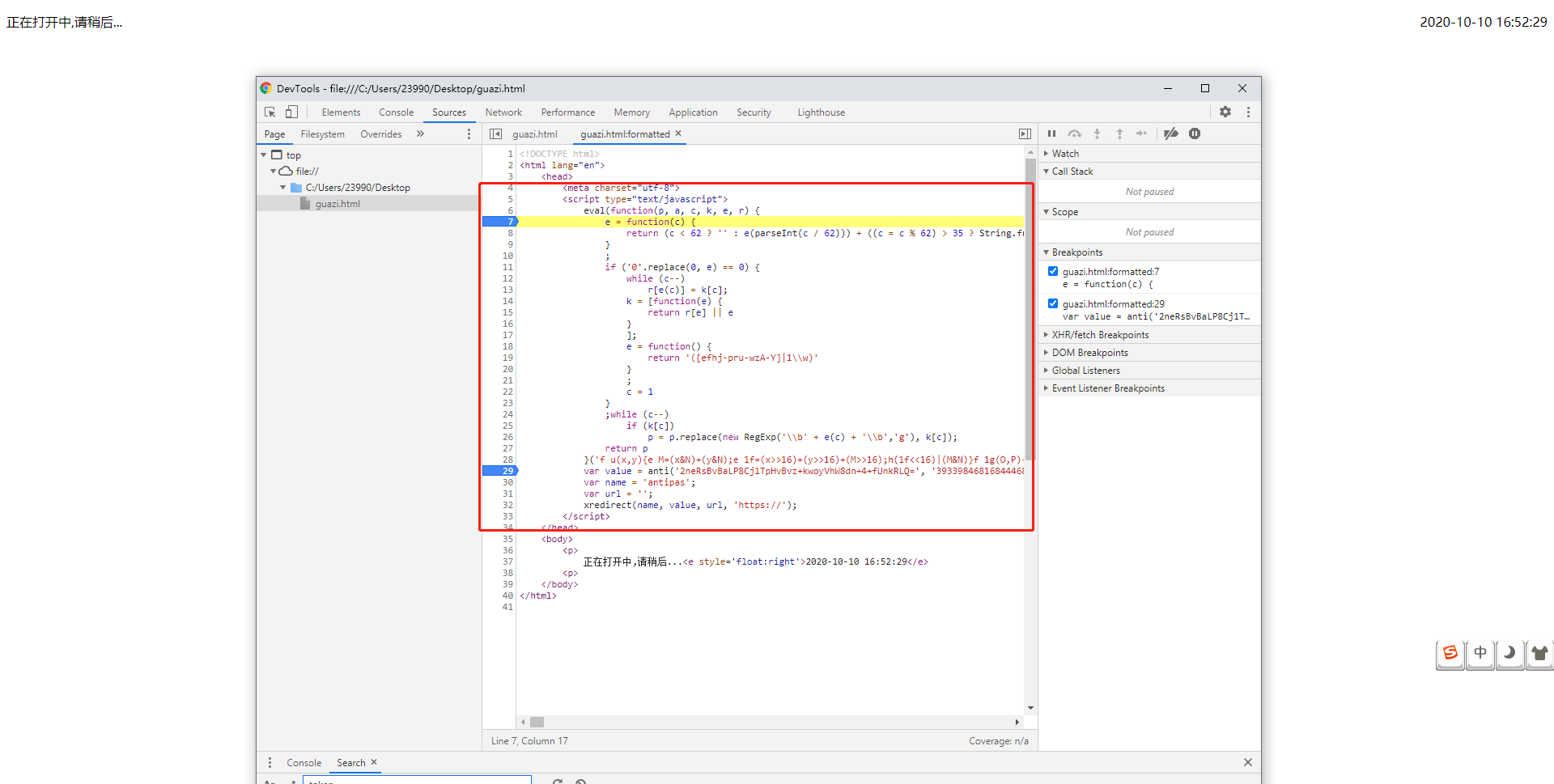
4、从图片的js中后四行可以看出大概意思:调用anti函数,将结果赋值给value,定义name,url。函数xredirect对结果进行判断,如果通过,返回带有数据的页面,否则则返回203页面。
5、页面调试,定位anti函数的位置
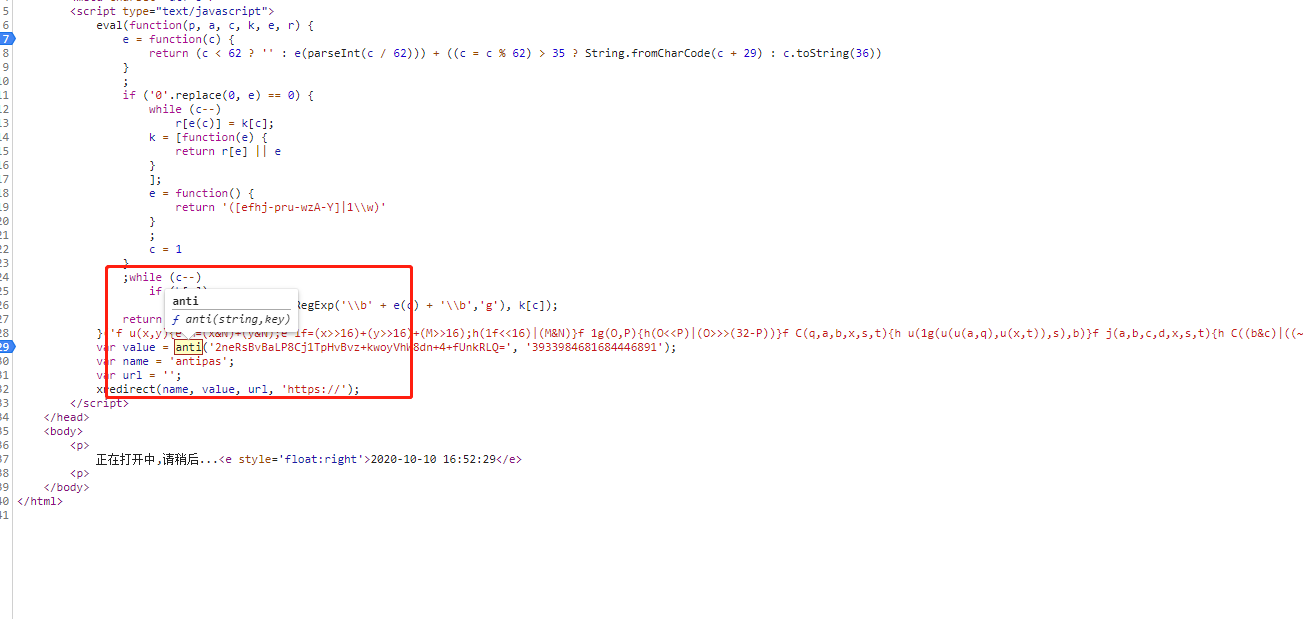

此时我们已经找到了关键的代码所在,此时就是写代码进行测试了!
思路:
1、获取203页面中anti里面的两个参数值
var value=anti('PcQWFy0em6diPDiDwc9uS67o9nl8hB3gHvIJsf5t54k=','986298625571186362')
2、将参数传入抠出来的js,进行编译
3、cookie携带返回值,进行页面的请求,查看信息
def scrape(url):
headers = {
'Host': 'www.guazi.com',
'Referer': 'https://www.guazi.com/cs/buy/o1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
}
try:
response = requests.get(url, headers=headers)
#检测状态!
if response.status_code == 200:
return response.text
elif "eval" in response.text:
# 通过正则获取到相关的字段和值
value_search = re.compile(r"anti\('(.*?)','(.*?)'\);")
string = value_search.search(response.text).group(1)
key = value_search.search(response.text).group(2)
print(string, key) # 输出anti中string和key的值
# 读取破解好的js文件
with open(r"/Users/snail/PycharmProjects/untitled/xuexi/guazi.js", "r", encoding='utf-8') as f:
f_read = f.read()
# 使用execjs模块来封装这段js[即:实例化js],传入的是读取后的js文件
js = execjs.compile(f_read)
js_return = js.call("anti", string, key) # 传递的是当前需要使用的"anti"方法,和两个方法中需要的参数
# print(js_return) # 输出anti方法进行加密处理后的cookie值
cookie_value = "antipas=" + js_return # 该cookie格式需要在前面加"antipas="字符串
headers["Cookie"] = cookie_value # 将cookie设置到头部
response_second = requests.get(url=url, headers=headers) # 再次请求网址
return response.text
结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号