GRU简介
 人工智能深度学习——RNN->LSTM->GRU
循环神经网络->长短期记忆神经网络->门循环单元模型
人工智能深度学习——RNN->LSTM->GRU
循环神经网络->长短期记忆神经网络->门循环单元模型
一、GRU介绍
GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流形的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。
GRU的参数较少,因此训练速度更快,GRU能够降低过拟合的风险。
在LSTM中引入了三个门函数:输入门、遗忘门和输出门来控制输入值、记忆值和输出值。而在GRU模型中只有两个门:分别是更新门和重置门。具体结构如下图所示:
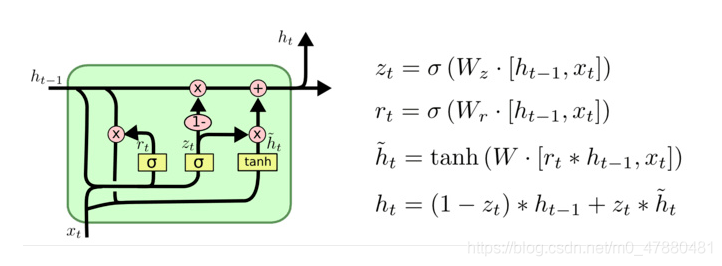
·
图中的zt和rt分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集 h~t


二、GRU与LSTM的比较
- GRU相比于LSTM少了输出门,其参数比LSTM少。
- GRU在复调音乐建模和语音信号建模等特定任务上的性能和LSTM差不多,在某些较小的数据集上,GRU相比于LSTM表现出更好的性能。
- LSTM比GRU严格来说更强,因为它可以很容易地进行无限计数,而GRU却不能。这就是GRU不能学习简单语言的原因,而这些语言是LSTM可以学习的。
- GRU网络在首次大规模的神经网络机器翻译的结构变化分析中,性能始终不如LSTM。
三、GRU的API
rnn = nn.GRU(input_size, hidden_size, num_layers, bias, batch_first, dropout, bidirectional)
初始化:
input_size: input的特征维度
hidden_size: 隐藏层的宽度
num_layers: 单元的数量(层数),默认为1,如果为2以为着将两个GRU堆叠在一起,当成一个GRU单元使用。
bias: True or False,是否使用bias项,默认使用
batch_first: Ture or False, 默认的输入是三个维度的,即:(seq, batch, feature),第一个维度是时间序列,第二个维度是batch,第三个维度是特征。如果设置为True,则(batch, seq, feature)。即batch,时间序列,每个时间点特征。
dropout:设置隐藏层是否启用dropout,默认为0
bidirectional:True or False, 默认为False,是否使用双向的GRU,如果使用双向的GRU,则自动将序列正序和反序各输入一次。
输入:
rnn(input, h_0)
输出:
output, hn = rnn(input, h0)
形状的和LSTM差不多,也有双向
四、情感分类demo修改成GRU
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
import os
import re
import pickle
import numpy as np
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
dataset_path = r'C:\Users\ci21615\Downloads\aclImdb_v1\aclImdb'
MAX_LEN = 500
def tokenize(text):
"""
分词,处理原始文本
:param text:
:return:
"""
fileters = ['!', '"', '#', '$', '%', '&', '\(', '\)', '\*', '\+', ',', '-', '\.', '/', ':', ';', '<', '=', '>', '\?', '@'
, '\[', '\\', '\]', '^', '_', '`', '\{', '\|', '\}', '~', '\t', '\n', '\x97', '\x96', '”', '“', ]
text = re.sub("<.*?>", " ", text, flags=re.S)
text = re.sub("|".join(fileters), " ", text, flags=re.S)
return [i.strip() for i in text.split()]
class ImdbDataset(Dataset):
"""
准备数据集
"""
def __init__(self, mode):
super(ImdbDataset, self).__init__()
if mode == 'train':
text_path = [os.path.join(dataset_path, i) for i in ['train/neg', 'train/pos']]
else:
text_path = [os.path.join(dataset_path, i) for i in ['test/neg', 'test/pos']]
self.total_file_path_list = []
for i in text_path:
self.total_file_path_list.extend([os.path.join(i, j) for j in os.listdir(i)])
def __getitem__(self, item):
cur_path = self.total_file_path_list[item]
cur_filename = os.path.basename(cur_path)
# 获取标签
label_temp = int(cur_filename.split('_')[-1].split('.')[0]) - 1
label = 0 if label_temp < 4 else 1
text = tokenize(open(cur_path, encoding='utf-8').read().strip())
return label, text
def __len__(self):
return len(self.total_file_path_list)
class Word2Sequence():
UNK_TAG = 'UNK'
PAD_TAG = 'PAD'
UNK = 0
PAD = 1
def __init__(self):
self.dict = {
self.UNK_TAG: self.UNK,
self.PAD_TAG: self.PAD
}
self.count = {} # 统计词频
def fit(self, sentence):
"""
把单个句子保存到dict中
:return:
"""
for word in sentence:
self.count[word] = self.count.get(word, 0) + 1
def build_vocab(self, min=5, max=None, max_feature=None):
"""
生成词典
:param min: 最小出现的次数
:param max: 最大次数
:param max_feature: 一共保留多少个词语
:return:
"""
# 删除词频小于min的word
if min is not None:
self.count = {word:value for word,value in self.count.items() if value > min}
# 删除词频大于max的word
if max is not None:
self.count = {word:value for word,value in self.count.items() if value < max}
# 限制保留的词语数
if max_feature is not None:
temp = sorted(self.count.items(), key=lambda x:x[-1],reverse=True)[:max_feature]
self.count = dict(temp)
for word in self.count:
self.dict[word] = len(self.dict)
# 得到一个反转的字典
self.inverse_dict = dict(zip(self.dict.values(), self.dict.keys()))
def transform(self, sentence, max_len=None):
"""
把句子转化为序列
:param sentence: [word1, word2...]
:param max_len: 对句子进行填充或裁剪
:return:
"""
if max_len is not None:
if max_len > len(sentence):
sentence = sentence + [self.PAD_TAG] * (max_len - len(sentence)) # 填充
if max_len < len(sentence):
sentence = sentence[:max_len] # 裁剪
return [self.dict.get(word, self.UNK) for word in sentence]
def inverse_transform(self, indices):
"""
把序列转化为句子
:param indices: [1,2,3,4...]
:return:
"""
return [self.inverse_dict.get(idx) for idx in indices]
def __len__(self):
return len(self.dict)
def fit_save_word_sequence():
"""
从数据集构建字典
:return:
"""
ws = Word2Sequence()
train_path = [os.path.join(dataset_path, i) for i in ['train/neg', 'train/pos']]
total_file_path_list = []
for i in train_path:
total_file_path_list.extend([os.path.join(i, j) for j in os.listdir(i)])
for cur_path in tqdm(total_file_path_list, desc='fitting'):
sentence = open(cur_path, encoding='utf-8').read().strip()
res = tokenize(sentence)
ws.fit(res)
# 对wordSequesnce进行保存
ws.build_vocab(min=10)
# pickle.dump(ws, open('./lstm_model/ws.pkl', 'wb'))
return ws
def get_dataloader(mode='train', batch_size=20, ws=None):
"""
获取数据集,转换成词向量后的数据集
:param mode:
:return:
"""
# 导入词典
# ws = pickle.load(open('./model/ws.pkl', 'rb'))
# 自定义collate_fn函数
def collate_fn(batch):
"""
batch是list,其中是一个一个元组,每个元组是dataset中__getitem__的结果
:param batch:
:return:
"""
batch = list(zip(*batch))
labels = torch.LongTensor(batch[0])
texts = batch[1]
# 获取每个文本的长度
lengths = [len(i) if len(i) < MAX_LEN else MAX_LEN for i in texts]
# 每一段文本句子都转换成了n个单词对应的数字组成的向量,即500个单词数字组成的向量
temp = [ws.transform(i, MAX_LEN) for i in texts]
texts = torch.LongTensor(temp)
del batch
return labels, texts, lengths
dataset = ImdbDataset(mode)
dataloader = DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
return dataloader
class ImdbLstmModel(nn.Module):
def __init__(self, ws):
super(ImdbLstmModel, self).__init__()
self.hidden_size = 64 # 隐藏层神经元的数量,即每一层有多少个LSTM单元
self.embedding_dim = 200 # 每个词语使用多长的向量表示
self.num_layer = 1 # 即RNN的中LSTM单元的层数
self.bidriectional = True # 是否使用双向LSTM,默认是False,表示双向LSTM,也就是序列从左往右算一次,从右往左又算一次,这样就可以两倍的输出
self.num_directions = 2 if self.bidriectional else 1 # 是否双向取值,双向取值为2,单向取值为1
self.dropout = 0.5 # dropout的比例,默认值为0。dropout是一种训练过程中让部分参数随机失活的一种方式,能够提高训练速度,同时能够解决过拟合的问题。这里是在LSTM的最后一层,对每个输出进行dropout
# 每个句子长度为500
# ws = pickle.load(open('./model/ws.pkl', 'rb'))
print(len(ws))
self.embedding = nn.Embedding(len(ws), self.embedding_dim)
# self.lstm = nn.LSTM(self.embedding_dim,self.hidden_size,self.num_layer,bidirectional=self.bidriectional,dropout=self.dropout)
self.gru = nn.GRU(input_size=self.embedding_dim, hidden_size=self.hidden_size, bidirectional=self.bidriectional)
self.fc = nn.Linear(self.hidden_size * self.num_directions, 20)
self.fc2 = nn.Linear(20, 2)
def init_hidden_state(self, batch_size):
"""
初始化 前一次的h_0(前一次的隐藏状态)和c_0(前一次memory)
:param batch_size:
:return:
"""
h_0 = torch.rand(self.num_layer * self.num_directions, batch_size, self.hidden_size)
return h_0
def forward(self, input):
# 句子转换成词向量
x = self.embedding(input)
# 如果batch_first为False的话转换一下seq_len和batch_size的位置
x = x.permute(1,0,2) # [seq_len, batch_size, embedding_num]
# 初始化前一次的h_0(前一次的隐藏状态)和c_0(前一次memory)
h_0 = self.init_hidden_state(x.size(1)) # [num_layers * num_directions, batch, hidden_size]
output, h_n = self.gru(x, h_0)
# 只要最后一个lstm单元处理的结果,这里多去的hidden state
out = torch.cat([h_n[-2, :, :], h_n[-1, :, :]], dim=-1)
out = self.fc(out)
out = F.relu(out)
out = self.fc2(out)
return F.log_softmax(out, dim=-1)
train_batch_size = 64
test_batch_size = 5000
def train(epoch, ws):
"""
训练
:param epoch: 轮次
:param ws: 字典
:return:
"""
mode = 'train'
imdb_lstm_model = ImdbLstmModel(ws)
optimizer = optim.Adam(imdb_lstm_model.parameters())
for i in range(epoch):
train_dataloader = get_dataloader(mode=mode, batch_size=train_batch_size, ws=ws)
for idx, (target, input, input_length) in enumerate(train_dataloader):
optimizer.zero_grad()
output = imdb_lstm_model(input)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
pred = torch.max(output, dim=-1, keepdim=False)[-1]
acc = pred.eq(target.data).numpy().mean() * 100.
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\t ACC: {:.6f}'.format(i, idx * len(input), len(train_dataloader.dataset),
100. * idx / len(train_dataloader), loss.item(), acc))
torch.save(imdb_lstm_model.state_dict(), 'model/gru_model.pkl')
torch.save(optimizer.state_dict(), 'model/gru_optimizer.pkl')
def test(ws):
mode = 'test'
# 载入模型
lstm_model = ImdbLstmModel(ws)
lstm_model.load_state_dict(torch.load('model/lstm_model.pkl'))
optimizer = optim.Adam(lstm_model.parameters())
optimizer.load_state_dict(torch.load('model/lstm_optimizer.pkl'))
lstm_model.eval()
test_dataloader = get_dataloader(mode=mode, batch_size=test_batch_size, ws=ws)
with torch.no_grad():
for idx, (target, input, input_length) in enumerate(test_dataloader):
output = lstm_model(input)
test_loss = F.nll_loss(output, target, reduction='mean')
pred = torch.max(output, dim=-1, keepdim=False)[-1]
correct = pred.eq(target.data).sum()
acc = 100. * pred.eq(target.data).cpu().numpy().mean()
print('idx: {} Test set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(idx, test_loss, correct, target.size(0), acc))
if __name__ == '__main__':
# 构建字典
ws = fit_save_word_sequence()
# 训练
train(10, ws)
# 测试
# test(ws)
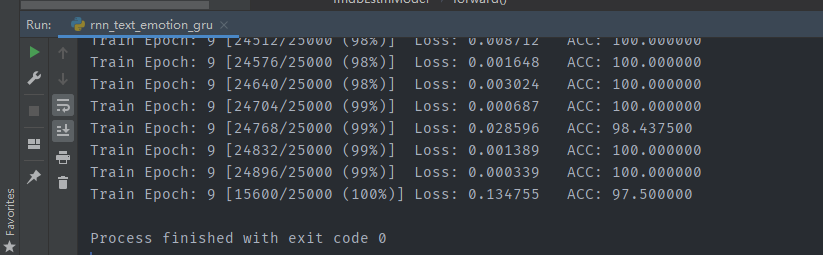
结果展示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号