【深度学习】Deep Learning Framework Matrix Multiplication Speed Compare(numpy & torch & mlx)
✨ 实验环境
SoC:M1 Pro 10 cores CPU 16 cores GPU
RAM:16GB
numpy:2.2.6
torch:2.8.0
mlx:0.28.0
✨FP16 & FP32
| 库 | 硬件平台 | 运算速度 | 主要原因 |
|---|---|---|---|
| PyTorch | GPU | FP16 显著快于 FP32 | 现代 GPU(如 Tensor Core)对 FP16 有硬件加速。 |
| MLX | Apple Silicon(GPU/NPU) | FP16 显著快于 FP32 | 针对 Apple 芯片的优化,充分利用其并行计算能力。 |
| NumPy | CPU | 差异不显著 | CPU 对 FP16 没有专门的硬件加速,主要依赖传统计算单元。 |
numpy 不算深度学习框架 仅作参考(
✨ 实验结果
分别测试了 torch mlx 使用 FP16 进行矩阵乘法
numpy 使用 FP32 进行矩阵乘法运算
实验结果如下
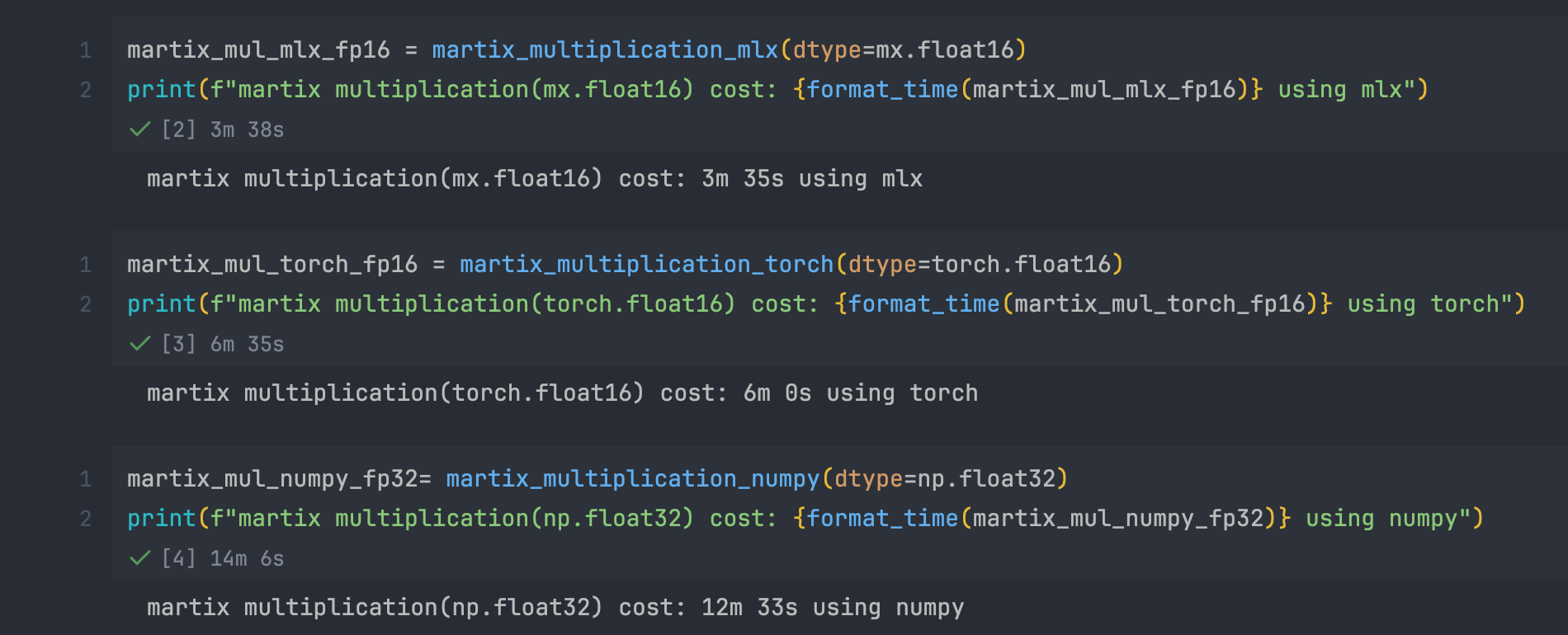
mlx FP16:3m 35s
torch FP16:6m 0s
numpy FP32:12m 33s
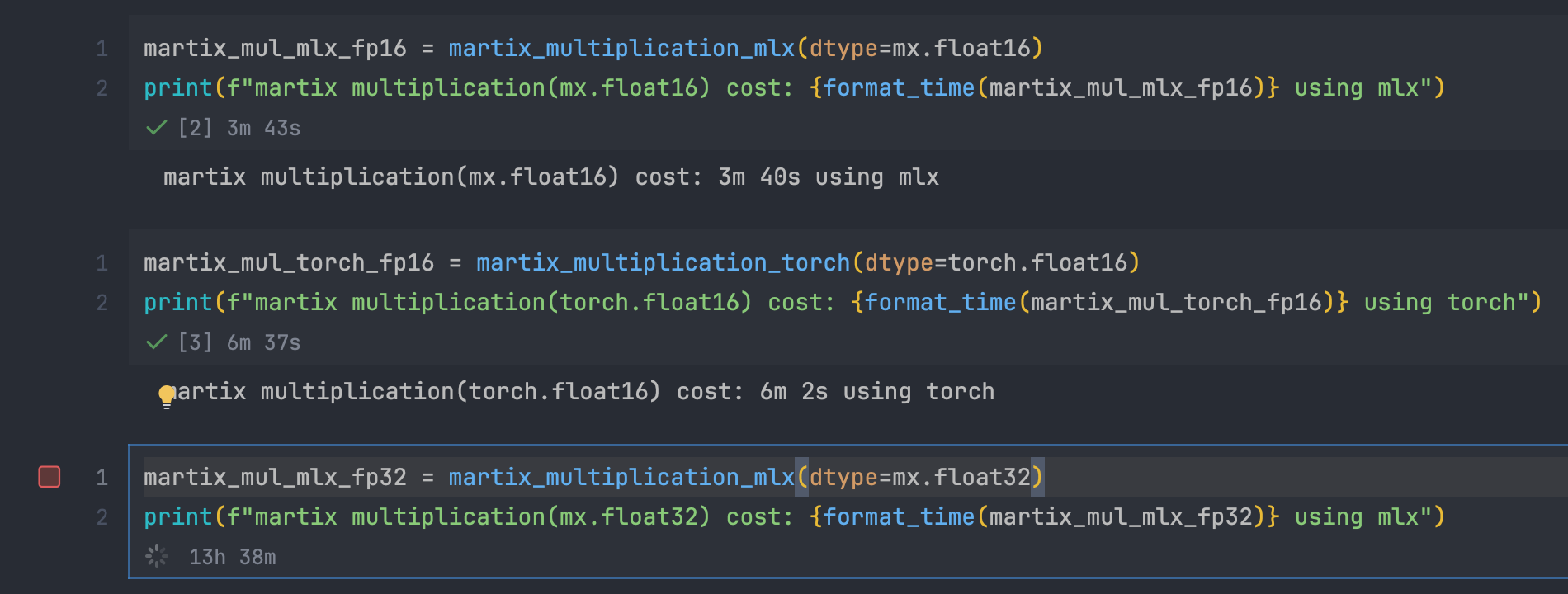
本来想 mlx torch numpy 都测试 FP16 FP32
但是发现没有加速的情况下运算实在太慢了= =
mlx FP32 耗时 13h 38m 还没有完成
✨ 代码实现
import gc
import time
import numpy as np
import mlx.core as mx
import torch
def martix_multiplication_mlx(dtype: mx.float16):
R = 10
duration = 0
for i in range(16):
N = 2**i
a = mx.random.uniform(-1.0, 1.0, [N, N], dtype=dtype)
b = mx.random.uniform(-1.0, 1.0, [N, N], dtype=dtype)
mx.eval(a)
mx.eval(b)
for r in range(R):
start_time = time.perf_counter()
c = a @ b
mx.eval(c)
duration += time.perf_counter() - start_time
del a, b, c
gc.collect()
mx.clear_cache()
return duration
def martix_multiplication_torch(dtype: torch.float16):
R = 10
duration = 0
for i in range(16):
N = 2**i
a = torch.rand(N, N, dtype=dtype, device='mps')
b = torch.rand(N, N, dtype=dtype, device='mps')
# 预热 GPU
_ = a @ b
duration = 0
for r in range(R):
start_time = time.perf_counter()
c = a @ b
torch.mps.synchronize()
duration += time.perf_counter() - start_time
del a, b, c
gc.collect()
torch.mps.empty_cache()
return duration
def martix_multiplication_numpy(dtype: np.float16):
R = 10
duration = 0
for i in range(16):
N = 2 ** i
# 创建 NumPy 数组
a = np.random.rand(N, N).astype(dtype)
b = np.random.rand(N, N).astype(dtype)
# NumPy 在 CPU 上运行,没有“预热”或“同步”的概念
# 因此,我们不需要执行 _ = a @ b 或 numpy.synchronize()
duration = 0
for r in range(R):
start_time = time.perf_counter()
c = a @ b
duration += time.perf_counter() - start_time
del a, b, c
gc.collect()
return duration
def format_time(seconds):
hours = int(seconds // 3600)
minutes = int((seconds % 3600) // 60)
seconds = seconds % 60
if hours > 0:
return f"{hours}h {minutes}m {seconds:.0f}s"
elif minutes > 0:
return f"{minutes}m {seconds:.0f}s"
else:
return f"{seconds:.0f}s"
martix_mul_mlx_fp16 = martix_multiplication_mlx(dtype=mx.float16)
print(f"martix multiplication(mx.float16) cost: {format_time(martix_mul_mlx_fp16)} using mlx")
martix_mul_torch_fp16 = martix_multiplication_torch(dtype=torch.float16)
print(f"martix multiplication(torch.float16) cost: {format_time(martix_mul_torch_fp16)} using torch")
martix_mul_numpy_fp32= martix_multiplication_numpy(dtype=np.float32)
print(f"martix multiplication(np.float32) cost: {format_time(martix_mul_numpy_fp32)} using numpy")
martix_mul_mlx_fp32 = martix_multiplication_mlx(dtype=mx.float32)
print(f"martix multiplication(mx.float32) cost: {format_time(martix_mul_mlx_fp32)} using mlx")
martix_mul_torch_fp32 = martix_multiplication_torch(dtype=torch.float32)
print(f"martix multiplication(torch.float32) cost: {format_time(martix_mul_torch_fp32)} using torch")
martix_mul_numpy_fp16 = martix_multiplication_numpy(dtype=np.float16)
print(f"martix multiplication(np.float16) cost: {format_time(martix_mul_numpy_fp16)} using numpy")
✨ 参考及引用
https://wangkuiyi.github.io/roofline.html
⭐ 转载请注明出处
本文作者:双份浓缩馥芮白
原文链接:https://www.cnblogs.com/Flat-White/p/19046521
版权所有,如需转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号