[MIT 6.S081] Lab: Multithreading
Lab: Multithreading
在这个实验中主要是要熟悉一下多线程的一些东西,比如实现一个用户态线程,还有使用一些 api 。
Uthread: switching between threads
这个任务的主要目的是实现用户态线程的调度,不过这个用户态线程个人认为是有栈协程。在这个任务中,需要实现在一个 CPU 资源的情况下调度三个线程的操作。
考虑一下内核态线程是怎么切换的,当前这个线程放弃 CPU ,把 CPU 交还给调度器线程,然后调度器线程再挑一个可以运行的内核态线程并切换到它。在这个过程中,需要保存上下文环境,也就是局部变量之类。不过,由于 保存上下文环境需要调用一个由汇编写的函数,c 在调用函数的过程中会将那些变量压入栈中保存,至于堆更不需要关心,他们不会被覆盖。因此,对于上下文切换,只剩下了 swtch.S 中所要保存的寄存器。
# Context switch
#
# void swtch(struct context *old, struct context *new);
#
# Save current registers in old. Load from new.
.globl swtch
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret
现在我们所要实现的用户态线程也是一样的东西,我们依然要保存这些寄存器,那么也需要一个数据结构保存它们,也就是加入一个 struct context 来保存。
在 uthread_switch.S 文件中保存和载入寄存器。
.text
/*
* save the old thread's registers,
* restore the new thread's registers.
*/
.globl thread_switch
thread_switch:
/* YOUR CODE HERE */
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret /* return to ra */
在 uthread.c 中添加一个数据结构 struct context ,并将其作为 struct thread 的字段。
struct context {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
struct thread {
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
struct context context;
};
在 thread_schedule 函数中,我们需要将上下文环境保存好。
void
thread_schedule(void)
{
...
/* YOUR CODE HERE
* Invoke thread_switch to switch from t to next_thread:
* thread_switch(??, ??);
*/
thread_switch((uint64)&(t->context), (uint64)&(current_thread->context));
} else
next_thread = 0;
}
现在就剩下一个初始化的问题,对于上下文环境,我们要怎么初始化它?
对于 thread_switch ,它最终会将载入的 context 的 ra 作为其返回地址,在这里我们的每一个线程都要执行一个函数,自然就是将这个函数的调用地址作为 ra 的返回地址了。其次,在切换的过程中,也会重新加载 sp ,现在对于每个线程来说,它的栈都必须是单独的,因为它们之间没有什么关联,因此我们也要为每个线程设置一个新的栈。
如果你这边 sp 设置不好的话,那么在函数调用的压栈和出栈过程中,会修改到不该访问的内存位置,这是一个需要注意的地点。
void
thread_create(void (*func)())
{
struct thread *t;
for (t = all_thread; t < all_thread + MAX_THREAD; t++) {
if (t->state == FREE) break;
}
t->state = RUNNABLE;
// YOUR CODE HERE
for (int i = 0; i < STACK_SIZE; i ++) {
t->stack[i] = 0;
}
t->context.sp = (uint64)(t->stack + STACK_SIZE);
t->context.ra = (uint64)func;
}
Using threads
在这个任务中,要为哈希表的并发编程给它上一下锁,让它能够正常工作。
这里上锁就是要防止数据竞争,让它安全的话,可以直接对哈希表上一个大锁,但是这样就没有效率。因此,可以细化粒度为单独的桶,因为桶与桶之间是可以区分的。
首先,我们为每个桶加一把锁。
struct entry {
int key;
int value;
struct entry *next;
};
struct entry *table[NBUCKET];
pthread_mutex_t table_lock[NBUCKET];
然后,我们要在 put 和 get 操作中,获取当前要操作桶的锁,像 RAII 一样上锁和释放锁。
static
void put(int key, int value)
{
int i = key % NBUCKET;
pthread_mutex_t *lock = &table_lock[i];
pthread_mutex_lock(lock);
// is the key already present?
struct entry *e = 0;
for (e = table[i]; e != 0; e = e->next) {
if (e->key == key)
break;
}
if(e){
// update the existing key.
e->value = value;
} else {
// the new is new.
insert(key, value, &table[i], table[i]);
}
pthread_mutex_unlock(lock);
}
static struct entry*
get(int key)
{
int i = key % NBUCKET;
pthread_mutex_t *lock = &table_lock[i];
pthread_mutex_lock(lock);
struct entry *e = 0;
for (e = table[i]; e != 0; e = e->next) {
if (e->key == key) break;
}
pthread_mutex_unlock(lock);
return e;
}
最后,这些锁需要初始化和销毁,在 main 函数的开头和结尾部分做一下。
int
main(int argc, char *argv[])
{
// pthread_mutex_init(&lock, NULL);
for (int i = 0; i < NBUCKET; i ++) {
pthread_mutex_init(&table_lock[i], NULL);
}
...
for (int i = 0; i < NBUCKET; i ++) {
pthread_mutex_destroy(&table_lock[i]);
}
}
对于问答的问题,其实就是两线程如果同时插入一个,那么这个过程中可能出现竞争,前一个还没插完后一个就插完了,后面那个就索引到原先的,前面那个就可能下一个还是原先的,这样就错误了。
Barrier
这里就是设置一个屏障,让过来到这边的线程先等一下所有线程,然后等到全部到达以后再一起开始。
逻辑也是这样,先对这个屏障上锁,因为会有很多线程并发访问它。如果线程数还没达标,那么就让这个线程等待一下,同时将释放锁,给下一个线程的访问。接着,最后一个线程到达以后,我们重新处理一下线程计数,并将轮数增加,然后唤醒一下这边的所有线程,接着锁又被获取到,然后就释放锁了。
static void
barrier()
{
// YOUR CODE HERE
//
// Block until all threads have called barrier() and
// then increment bstate.round.
//
pthread_mutex_lock(&bstate.barrier_mutex);
bstate.nthread ++;
if (bstate.nthread < nthread) {
pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);
} else {
bstate.round ++;
bstate.nthread = 0;
pthread_cond_broadcast(&bstate.barrier_cond);
}
pthread_mutex_unlock(&bstate.barrier_mutex);
}
Grade
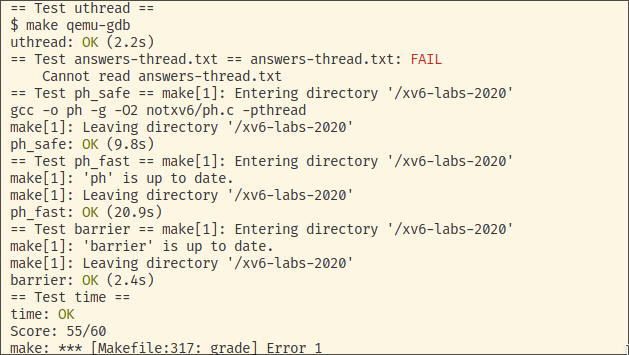
这里没加 answers-thread.txt 文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号