编码
2018-07-10 17:44 冻奶香甜玉米片 阅读(302) 评论(0) 收藏 举报UTF是为unicode 编码设计的一种 在传输 和 存储 时节省空间的编码方案
#coding:utf-8
# -*- coding:utf-8 -*-
python3中读文件的默认编码是utf-8
python执行文件,先把文本进行语法分析,之后加载到内存时使用的是unicode编码,因为python3把字符串以utf-8读到内存时,同时把字符串转换为unicode编码
在python2中 unicode也是一种数据类型
在python2中
#coding:utf-8
s="路飞"
s是使用utf-8字符编码的
可以用s.decode(utf-8)转化为unicode,括号里面要填原字符编码,然后转化成unicode,该函数统一转为unicode
s2=s.decode(utf-8)
encode()可以把unicode的字符编码转为其他字符编码
s2.encode(gbk)
则转为GBK字符编码,可以在windows里使用
总结:
在py3中 默认文件编码是utf-8,默认字符串编码是unicode(在内存中自动转换为unicode),即使文件头声明了其他编码,字符串编码也不会变
在py2中 默认文件编码是 ascii编码,默认字符串编码是ascii,如果文件头声明了其他编码,则字符串编码也会跟着改变
(估计文件头声明编码的作用是让解释器选择用什么编码去解释,不单在字符串上)
py2中
内存里的表示方法:bytes类型
对字符串而言,字符串和bytes类型就是一回事,只是中间多了一种对照转换(其实显示出来的东西能不能都这么认为:中间多了一种规定转换,如照片视频由像素组成,像素对照颜色转换?)
但是在py3中,str就是unicode格式的字符串,bytes就是单纯的二进制
s=对象名.decode("utf-8") 或 s=u"路飞"
直接把字符串变成unicode
据说整体代码都转换成unicode,不单指字符串,61课,17:08分,alex said
py2有unicode这个类型
py3没有unicode这个类型
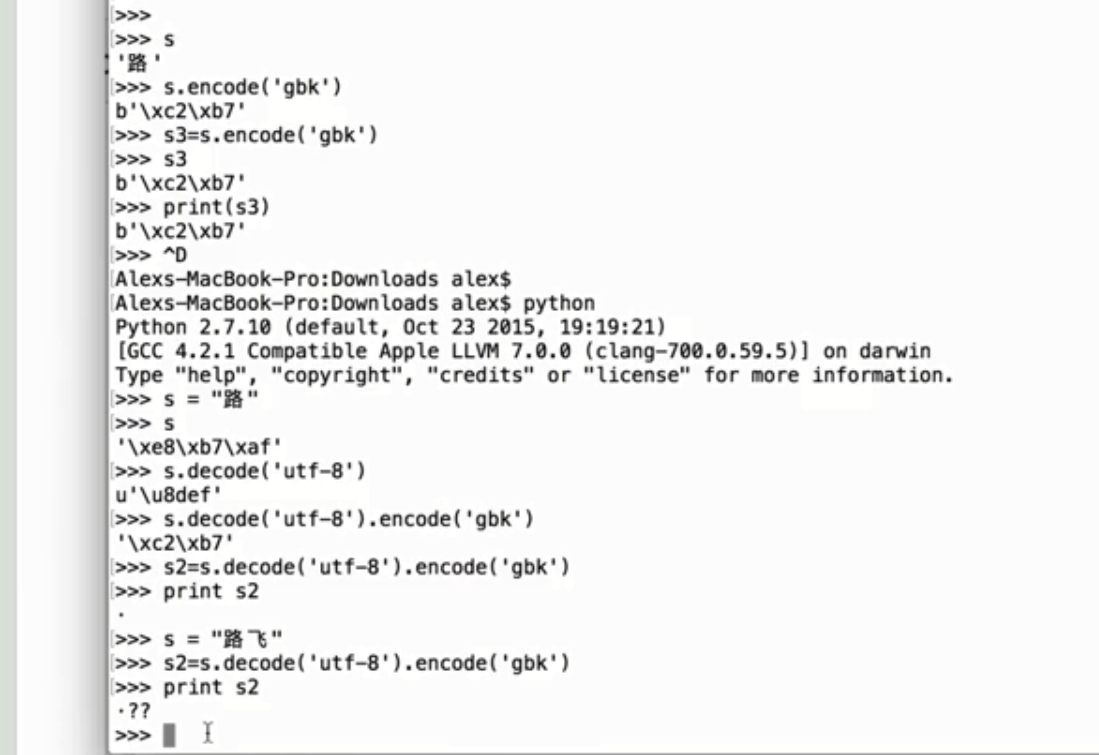
py2中 print encode后的GBK会直接显示汉子
而py3中,只会输出二进制
等于在py3中,只能通过unicode看到字型,其他编码只会按bytes展示
(编码后是为了储存和传输)
定义的文件头是告诉python解释器用什么编码读文件
62课 15:28 文件内容的编码是什么意思

 浙公网安备 33010602011771号
浙公网安备 33010602011771号