软件工程第四次作业:猫狗大战挑战赛
吴博群 第四次作业:猫狗大战挑战赛
知识点总结
-
fine-tune 微调 固定前面若干层,作为特征提取器,只重新训练最后两层
-
把训练集分割为小一点的子训练集,这些子集被取名为mini-batch,同时处理整个训练集的梯度下降法通常被称为batch梯度下降法。如果每次处理的只是单个mini-batch,则此时的梯度下降法称之为mini-batch梯度下降法。
-
datasets 是 torchvision 中的一个包,可以用做加载图像数据。它可以以多线程(multi-thread)的形式从硬盘中读取数据,使用 mini-batch 的形式,在网络训练中向 GPU 输送。在使用CNN处理图像时,需要进行预处理。图片将被整理成
的大小,同时还将进行归一化处理。
-
ImageFolder假设所有的文件按文件夹保存好,每个文件夹下面存贮同一类别的图片,文件夹的名字为分类的名字。
-
torchvision中集成了很多在 ImageNet (120万张训练数据) 上预训练好的通用的CNN模型,可以直接下载使用。
-
我们的目标是使用预训练好的模型,因此,需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。
-
RandomHorizontalFlip:以0.5的概率水平翻转给定的PIL图像
RandomVerticalFlip:以0.5的概率竖直翻转给定的PIL图像
随机旋转:transforms.RandomRotation
transforms.Resize 重置图像分辨率
填充:transforms.Pad
修改亮度、对比度和饱和度:transforms.ColorJitter
转灰度图:transforms.Grayscale
-
分类的类别名(classes)和类别名与数字类别的映射关系字典(class_to_idx)
学习代码部分(不对代码做任何修改)
准备数据

对图像数据的增强

划分训练集和测试集,以及绑定标签到图像上

查看dataset的一些属性

查看一个batch中数据的情况
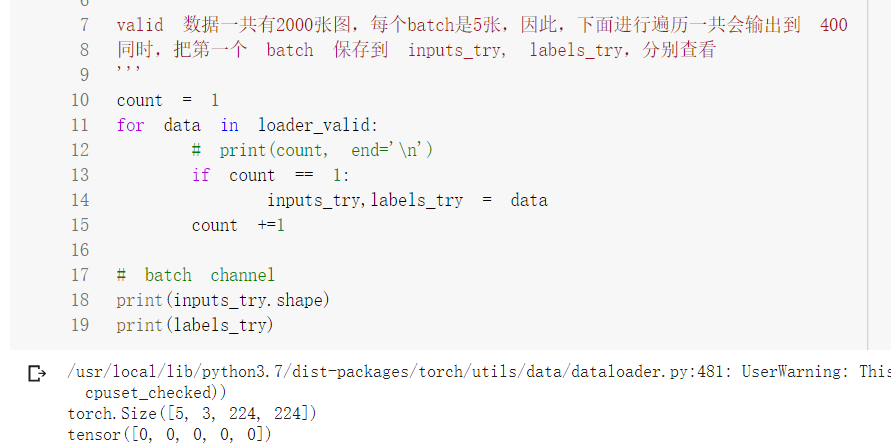
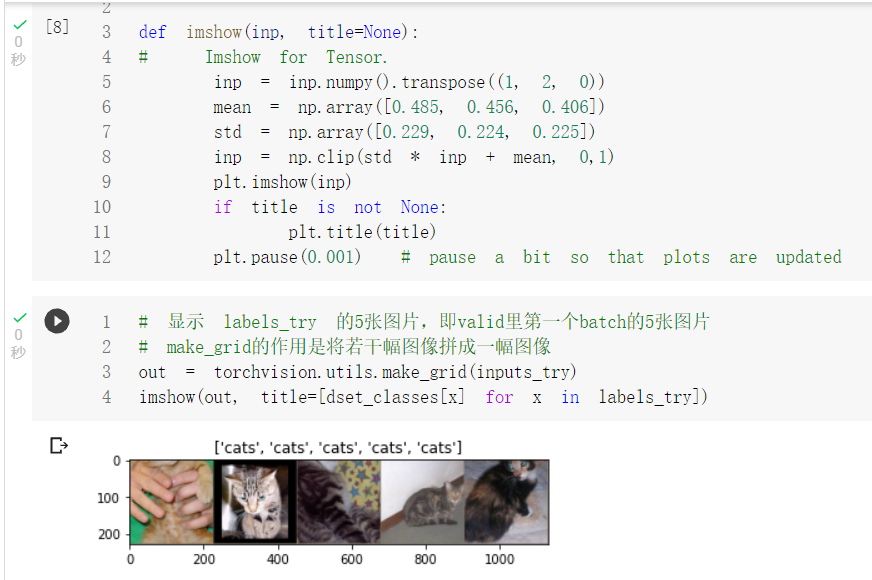
显示数据
采用冻结方法进行迁移学习
我们的目标是使用预训练好的模型,因此,需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。

VGG16模型结构,可以看出,只需要调整最后一层全连接层即可
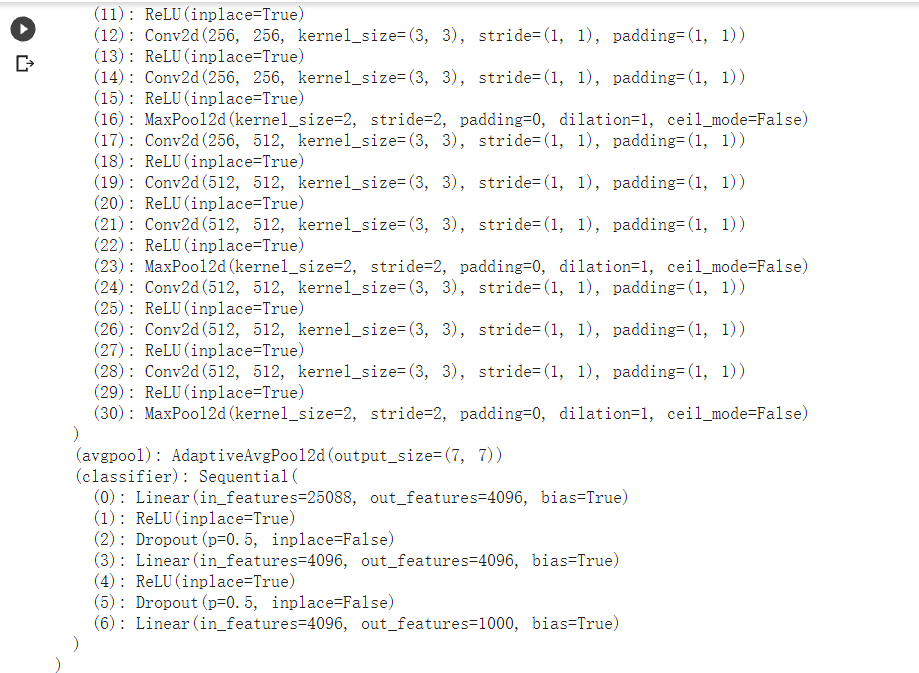
只使用优化器更新最后一层全连接层的参数

训练一个epoch得到的准确率

"猫狗大战"比赛
下载并解压数据

下载数据并解压,这里注意是rar格式的数据
人工给训练集和验证集标注数据
解压后发现并没有标注数据,故需要人工标注


标记数据成功
划分好了验证集和训练集的数据

查看数据,发现共有20000个训练集数据,2000个验证集数据

加载数据

沿用VGG16模型结构训练准确率
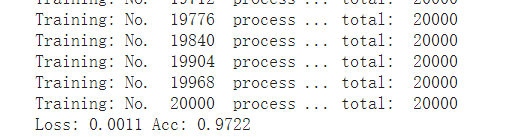
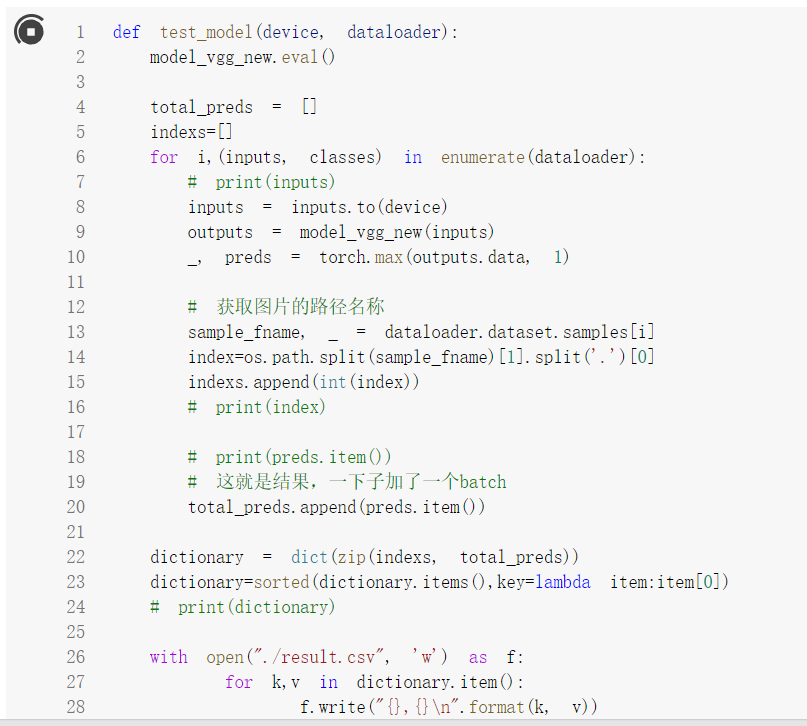
使用Test数据检测模型
生成便于ImageFolder读取的形式


其他步骤与之前的练习基本一致,不再赘述
生成提交需要的csv文件
提交解答,第一次序号乱了,泪目,成了随机预测的结果了,因为正好两个类,所以逼近0.5...

调整后所得的分数

如何优化
加入一些图像的增强

随着epoch的改变降低其学习率,并解冻冻结的层

当第二个epoch时,由于是微调模型参数,并没有必要训练那么多的次数,故借鉴了提前停止的思想,在大约训练了2000个数据时便停止训练

使用adam优化器,并调节其学习率(可随epoch动态下降,类似于模拟退火的思想
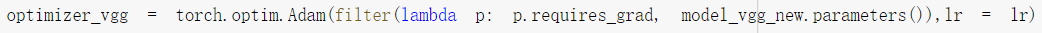
修改batch size为128一个批次
尝试了先训练,后冻结的方式,效果并不好,因为破坏了原有的模型结构
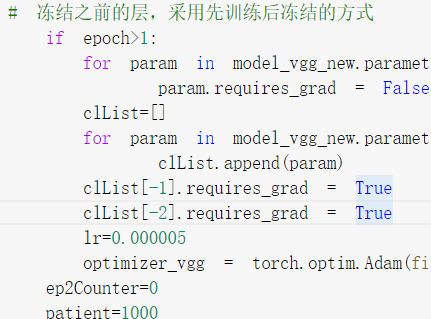

其实后来渐渐发现,这种本来训练数据就很相似的迁移学习,原本的模型参数能少改还是少改为好
测试集准确率
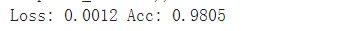
最终结果发现并没有太好的改善,发现前几名的方案大部分用了kaggle中的数据集进行了预训练,并且随着epoch的增加逐渐降低学习率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号