软件工程第2次作业 pytorch 基础练习及螺旋数据分类
【第二部分】代码练习
2.1 pytorch 基础练习
总览colab界面
挂载google Drive到colab代码
# 挂载google Drive
from google.colab import drive
drive.mount('/content/drive/')
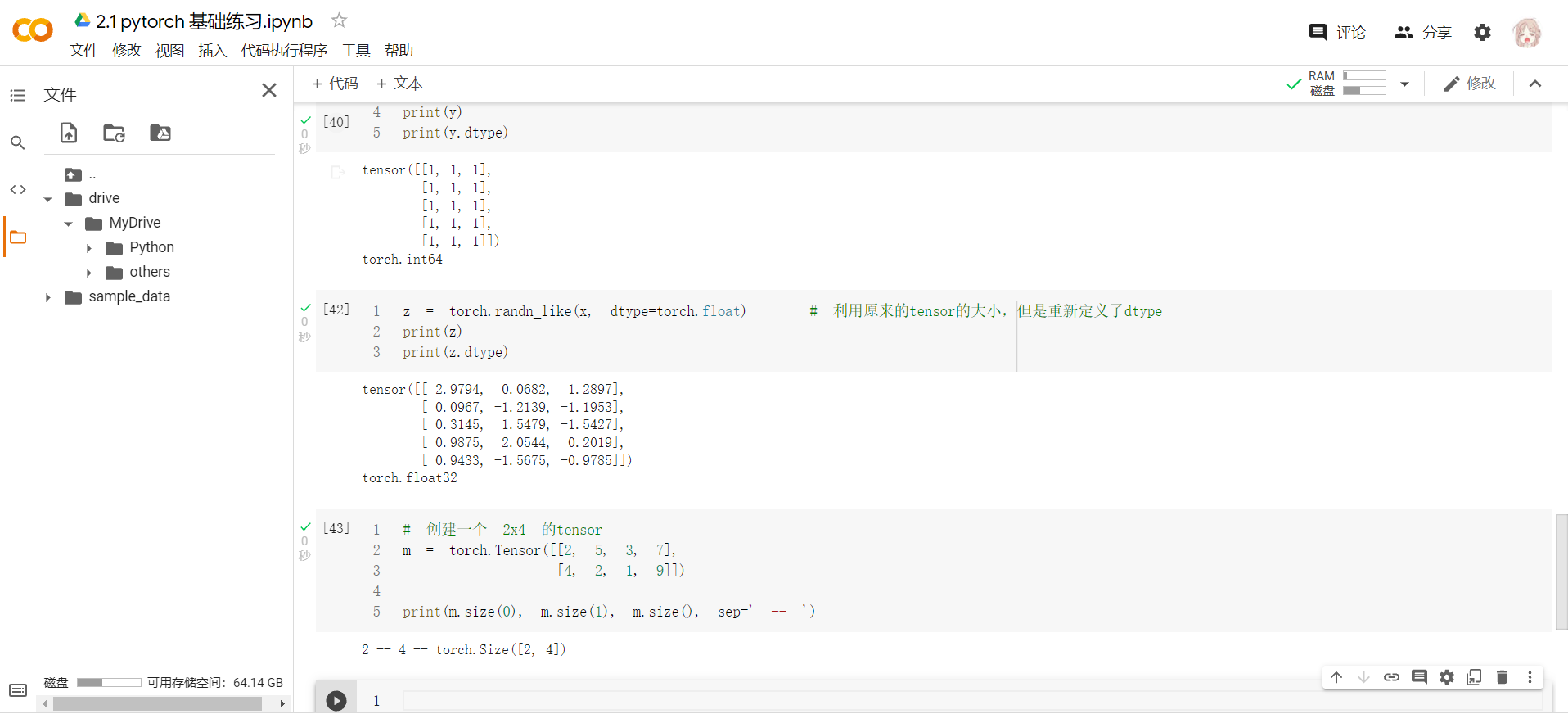
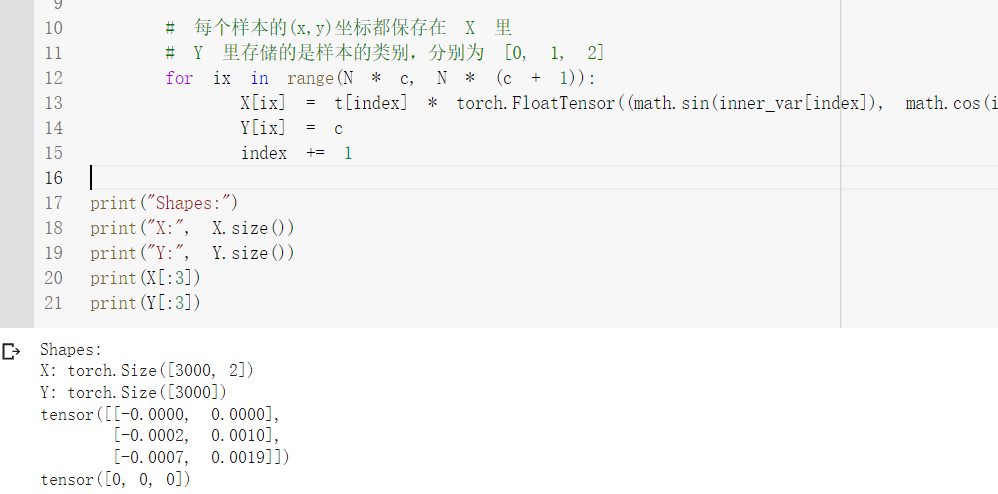
int类型为int32,long类型为int64
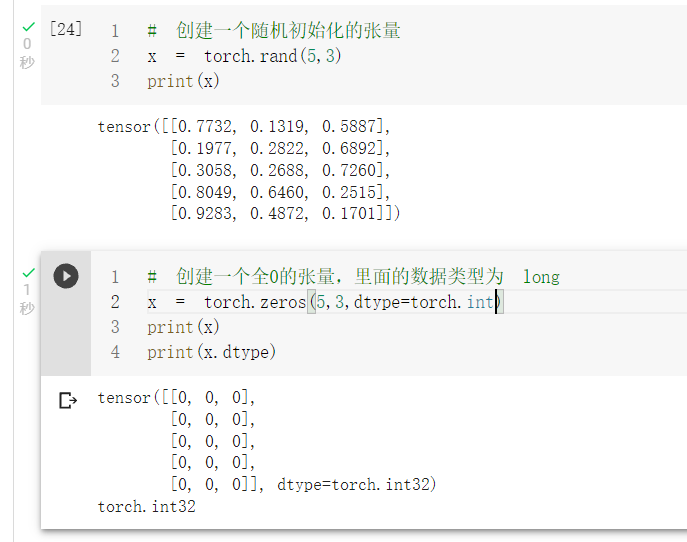
在执行代码的过程中发现报错
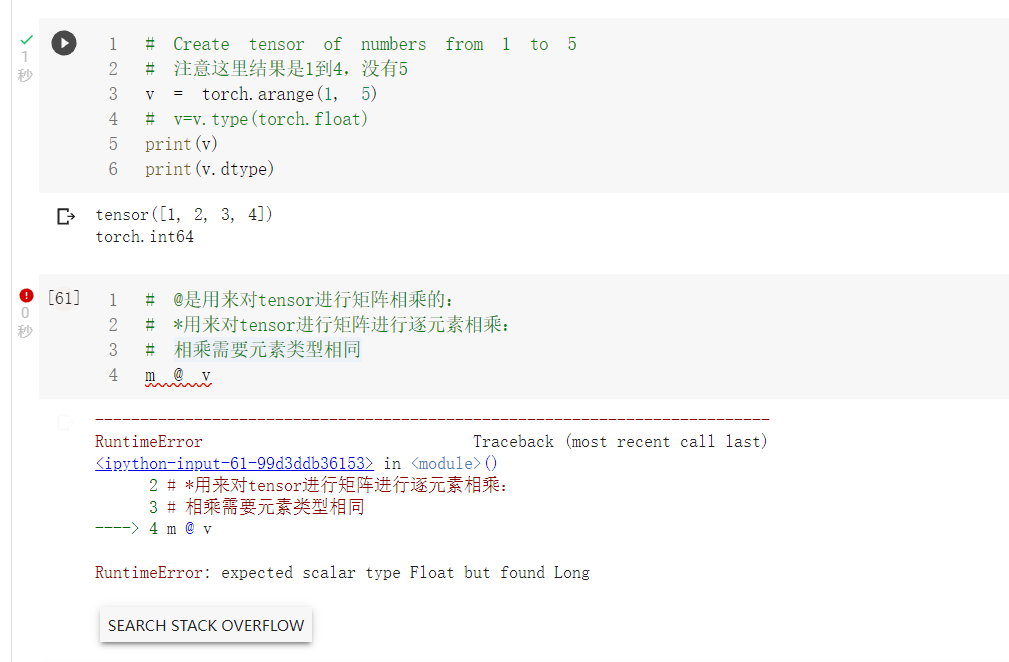
利用type修改元素类型后,成功执行

transpose()只能一次操作两个维度
函数返回输入矩阵input的转置。交换维度dim0和dim1
- input (Tensor) – 输入张量,必填
- dim0 (int) – 转置的第一维,默认0,可选
- dim1 (int) – 转置的第二维,默认1,可选
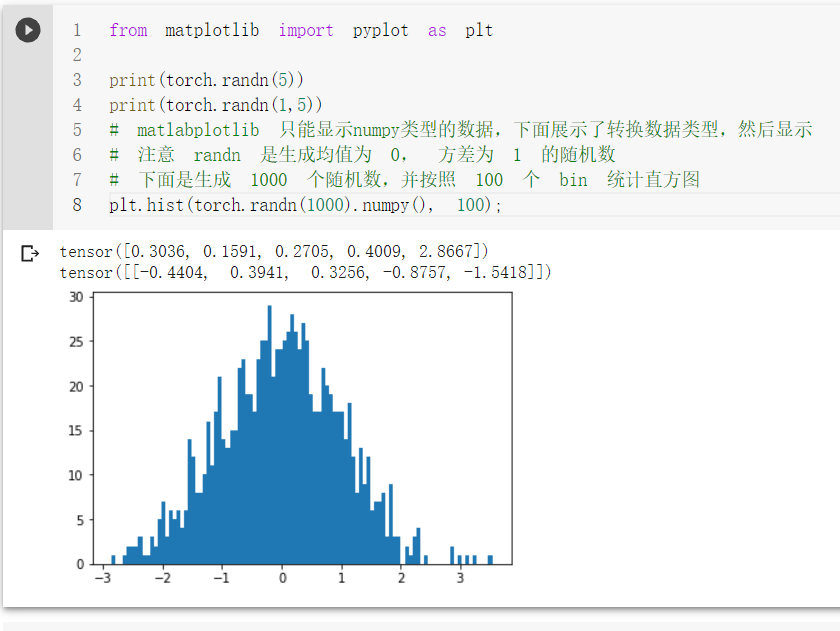
一个均匀分布,一个是标准正态分布。
rand返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数。张量的形状由参数sizes定义。
randn返回一个张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量的形状由参数sizes定义。
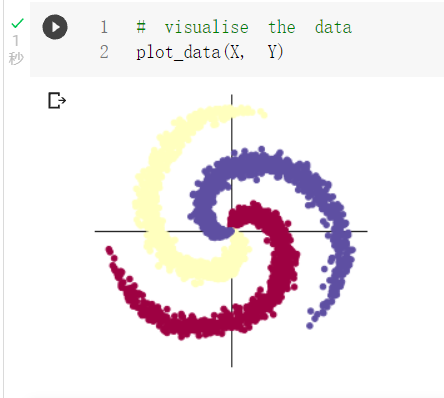
2.2 螺旋数据分类
Linux系统中的wget是一个下载文件的工具
(1)Tensor 和 Numpy都是矩阵,区别是前者可以在GPU上运行,后者只能在CPU上;
(2)Tensor和Numpy互相转化很方便,类型也比较兼容
device=torch.device("cpu")代表的使用cpu,而device=torch.device("cuda")则代表的使用GPU。
当我们指定了设备之后,就需要将模型加载到相应设备中,此时需要使用model=model.to(device),将模型加载到相应的设备中。
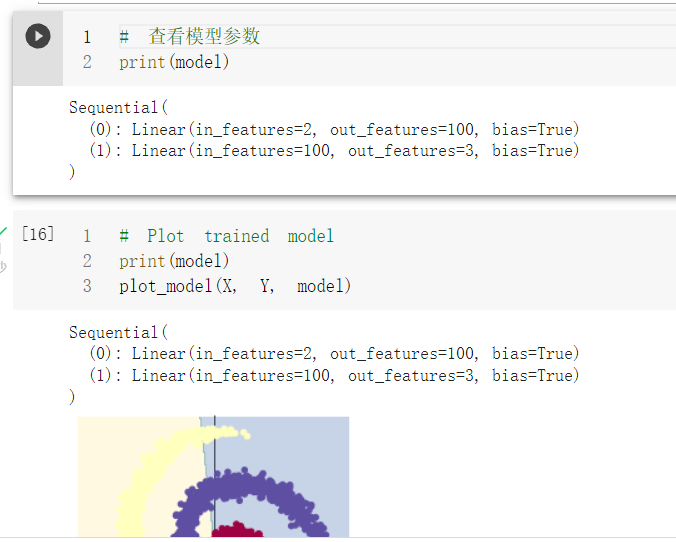
PyTorch的nn.Linear()是用于设置网络中的全连接层的,全连接层的输入与输出一般都设置为二维张量
torch.optim.SGD
- params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
- lr (
float) – 学习率 - momentum (
float, 可选) – 动量因子(默认:0) - weight_decay (
float, 可选) – 权重衰减(L2惩罚)(默认:0) - dampening (
float, 可选) – 动量的抑制因子(默认:0) - nesterov (
bool, 可选) – 使用Nesterov动量(默认:False)
PyTorch默认会对梯度进行累加。当你不想先前的梯度影响到当前梯度的计算时需要手动清零。
score, predicted = torch.max(y_pred, 1)
score, predicted = torch.max(y_pred, 1) 是沿着第二个方向(即X方向)提取最大值。最大的那个值存在 score 中,所在的位置(即第几列的最大)保存在 predicted 中
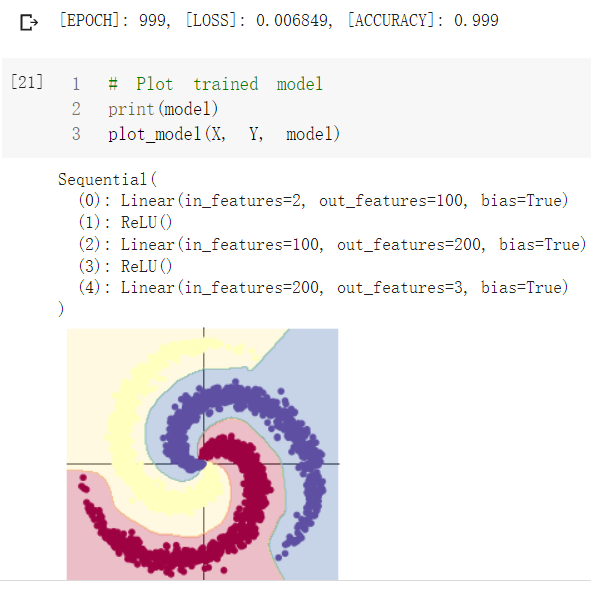
对神经网络结构进行部分改进,在输入输出层之间添加了一个隐藏层,并且添加了relu激活函数,构成了一个简单的3层神经网络,输入-隐层-输出,但是这足以达到很好的非线性程度

最终可以达到接近100%的分类正确率
完结撒花

实验总结
1. 矩阵相乘的类型,以及需要元素的类型相同
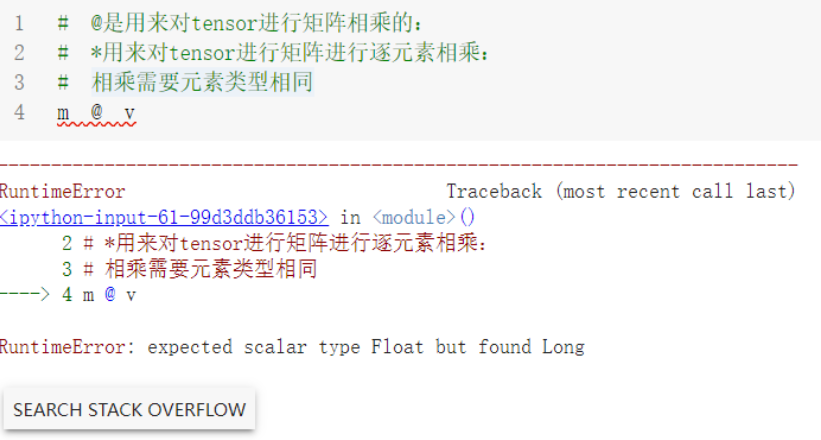
通过错误信息可以看到需要二者元素类型相同
2. pytorch的计算图与梯度
PyTorch默认会对梯度进行累加。当你不想先前的梯度影响到当前梯度的计算时需要手动清零。在训练模型的过程中,只要降低梯度清零的频率,就可以利用这种多次累计梯度的方式在较小的显存下实现较大的batchsize。
梯度累加就是,每次获取1个batch的数据,计算1次梯度,梯度不清空,不断累加,累加一定次数后,根据累加的梯度更新网络参数,然后清空梯度,进行下一次循环。
由于pytorch的动态计算图,当我们使用loss.backward()和opimizer.step()进行梯度下降更新参数的时候,梯度并不会自动清零(注意此时计算图会被删除,因为PyTorch的计算图为动态图,每次进行前向传播都会重新构建计算图,所以在计算backward后,会自动删除与该Tensor相关的计算图。如果需要连续多次计算backward,可以设置retain_graph参数为True。)。故计算图的清除与梯度的更新这两个操作是独立操作。
backward():反向传播求解梯度。
step():更新权重参数。
综上说明了pytorch的一个特点是每一步都是独立功能的操作,因此也就有需要梯度清零的说法,如若不显示的进行optimizer.zero_grad()这一步操作,backward()的时候就会累加梯度
3.为什么没有显式使用softmax
可以看出预测结果每一个点为三个值,即对应着三种类别的概率

但是从神经网络模型中并未发现使用了softmax激活函数(在tf.keras中需要在输出层显式指定激活函数,值最大的维度所对应的位置则作为该样本对应的类)
查阅资料后发现是在计算损失函数loss使用的torch.nn.CrossEntropyLoss()已经实现了logsoftmax
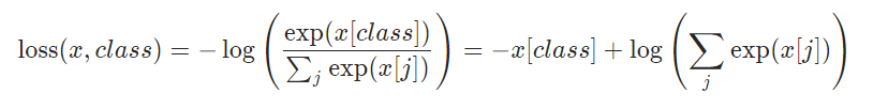
如果显式加入nn.Softmax()对模型影响也不大
4.修改网络结构使准确率提高到99.99%
就加了一个带relu的全连接层,没啥好说的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号