pandas
df转换为列表
data_list = df.to_dict(orient='records')
# [{'column1': 'a1', ···}, {'column1': 'a2', ···}, ···]
# 当df包含空值时,python会解析异常,应使用以下方法
import json
data_list = json.loads(df.to_json(orient='records'))
分组
"""根据cgi列分组,且对应到字典"""
grouped = df.groupby(['cgi'])
cgi_list = df['cgi'].to_list()
cgi_list = list(set(cgi_list))
group_df_dict = {}
for cgi in cgi_list:
cgi_df = grouped.get_group(cgi) # cgi对应的分组df
group_df_dict[cgi] = cgi_df
return group_df_dict
合并
df_all = pd.concat(df_list, ignore_index=True, axis=0)
分组运算
# dropna默认未True,是否去除空行
df = df_all.groupby(group_keys_list, as_index=False, dropna=False).agg({
'a': 'sum', #求和
'b': 'mean', # 平均值
'c': 'max', # 最大值
'd': 'min', # 最小值
'e': 'size', # 频率(包含NaN值)
}).reset_index()
重置行索引
df = df.reset_index()
判断dataframe是否为空
if df.empty:
print('为空')
插入数据库
from sqlalchemy import create_engine
import pandas as pd
engine = create_engine(
'mysql+pymysql://{0}:{1}@{2}:{3}/{4}?charset=utf8'.format(user,password,host,port,database,))
dataframe.to_sql(table, con=engine,
if_exists='append', index=False,
index_label=None,chunksize=None, dtype=None,
method=None,)
# if_exists:append:往表中添加,replace:替换原表,fail:表存在就失败
##优点:插入速度快
##缺点:必须严格对应数据表,主键相同时无法更新数据
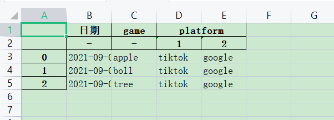
多级表头
import pandas as pd
index_tuple = [('a', '日期', '-'), ('b', 'game', '-'), ('c', 'platform', '1'), ('d', 'platform', '2')]
data = [
{'a': '2021-09-01', 'b': 'apple', 'c': 'tiktok', 'd': 'google'},
{'a': '2021-09-01', 'b': 'boll', 'c': 'tiktok', 'd': 'google'},
{'a': '2021-09-02', 'b': 'tree', 'c': 'tiktok', 'd': 'google'},
]
index_name = ['first', '', '']
index = pd.MultiIndex.from_tuples(index_tuple, names=index_name) # 生成多级表头
sort_cols = {item[0]: item[1] for item in index_tuple}
data_list = [[item[key] for key in sort_cols] for item in data] # 数据与表头对应
df = pd.DataFrame(data_list, columns=index)
df = df.sort_index(ascending=True)
df.columns = df.columns.droplevel() # 删除第一级。或droplevel(['first'])
path = 'tmp.xlsx'
# 保存
# df.to_excel('path', merge_cells=True)
# 或
writer = pd.ExcelWriter(path, engine='openpyxl')
df.to_excel(writer, merge_cells=True, sheet_name='Sheet1')
writer.sheets['Sheet1'].delete_rows(len(index_name)-1+1) # 删除空白行
writer.save()
转换为dataframe
列表转换为df
import pandas as pd
data = [
{'a': 1, 'b': 2},
{'a': 2, 'b': 6},
{'a': 3, 'b': 4},
]
df = pd.Dataframe(data)
字典转换为df
import pandas as pd
data = {'a': 1, 'b': 2, 'c': 3}
df = pd.DataFrame.from_dict(data, orient='index', columns=['num'])
df = df.reset_index().rename(columns={'index': 'letter'})
透视与反透视
透视
import pandas as pd
data_list = [
{'a': 1, 'b': 'aaa', 'c': 2},
{'a': 1, 'b': 'bbb', 'c': 22},
{'a': 2, 'b': 'aaa', 'c': 23},
{'a': 2, 'b': 'bbb', 'c': 24},
]
df = pd.DataFrame(data_list)
tmp_df = pd.pivot_table(df, index=['a'], columns=['b'], values=['c']).reset_index()
反透视
import pandas as pd
data_list = [
{'a': 'ae', 'b': 'bs', 'c': 1, 'd': 25, 'e': 3},
{'a': 'fe', 'b': 'fa', 'c': 2, 'd': 22, 'e': 37},
{'a': 'ea', 'b': 'ge', 'c': 3, 'd': 23, 'e': 3},
{'a': 'fz', 'b': 'fw', 'c': 4, 'd': 21, 'e': 72},
{'a': 'te', 'b': 'fe', 'c': 5, 'd': 12, 'e': 83},
]
tmp_df = pd.DataFrame(data_list)
df = pd.melt(tmp_df, id_vars=['a', 'b'])
df.rename(columns={'variable': 'item', 'value': 'amount'}, inplace=True)
遇上方知有

 浙公网安备 33010602011771号
浙公网安备 33010602011771号