爬取12306
站点转换
根据查看12306网站的html可以发现,站点都是用代码进行代替的,如:北京的代码为“BJP”,而我们在实际输入的时候不可能再去查询站点的代码,所以需要将中文站点转换为对应的代码。
经查询,12306提供了一个站点与代码对应的网站,我们只需要爬取这个网站的数据,分析整理出对应规则即可。

import requests,re
url = "https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9053"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36"}
response = requests.get(url,headers=headers)
经过比较,我们可以使用正则表达式进行分类,然后找出对应的关系
station_re = re.compile(r"'(.*)'")
station = station_re.findall(response.text)
l = "".join(station).split("|")
#print(l)
#中文名称
name = []
for i in range(1,len(l),5):
name.append(l[i])
#站点代码
code = []
for i in range(2,len(l),5):
code.append(l[i])
为了方便使用,将其放入字典中
#对应的字典
def to_dic():
name_code = dict((name[i],code[i]) for i in range(len(name)))
code_name = dict((code[i],name[i]) for i in range(len(name)))
return name_code,code_name
完整代码
import requests,re
url = "https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9053"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36"}
response = requests.get(url,headers=headers)
station_re = re.compile(r"'(.*)'")
station = station_re.findall(response.text)
l = "".join(station).split("|")
#print(l)
#中文名称
name = []
for i in range(1,len(l),5):
name.append(l[i])
#站点代码
code = []
for i in range(2,len(l),5):
code.append(l[i])
#print(code)
#对应的字典
def to_dic():
name_code = dict((name[i],code[i]) for i in range(len(name)))
code_name = dict((code[i],name[i]) for i in range(len(name)))
return name_code,code_name
def search(a):
'查询站点'
d = to_dic()
if a in d[0]:
print(d[0][a])
elif a in d[1]:
print(d[1][a])
else:
print("不存在此站点")
return None
if __name__ == "__main__":
print("结束时请输入“结束”或“over”")
while True:
a = input("请输入要查询的站点:")
if a == "结束" or a == "over":
break
else:
search(a)
将其打包成一个py文件(station_name_code.py),方便后面爬取12306时调取。
爬取12306
爬取信息
分析网页可以看出,数据都被放在了json文件中
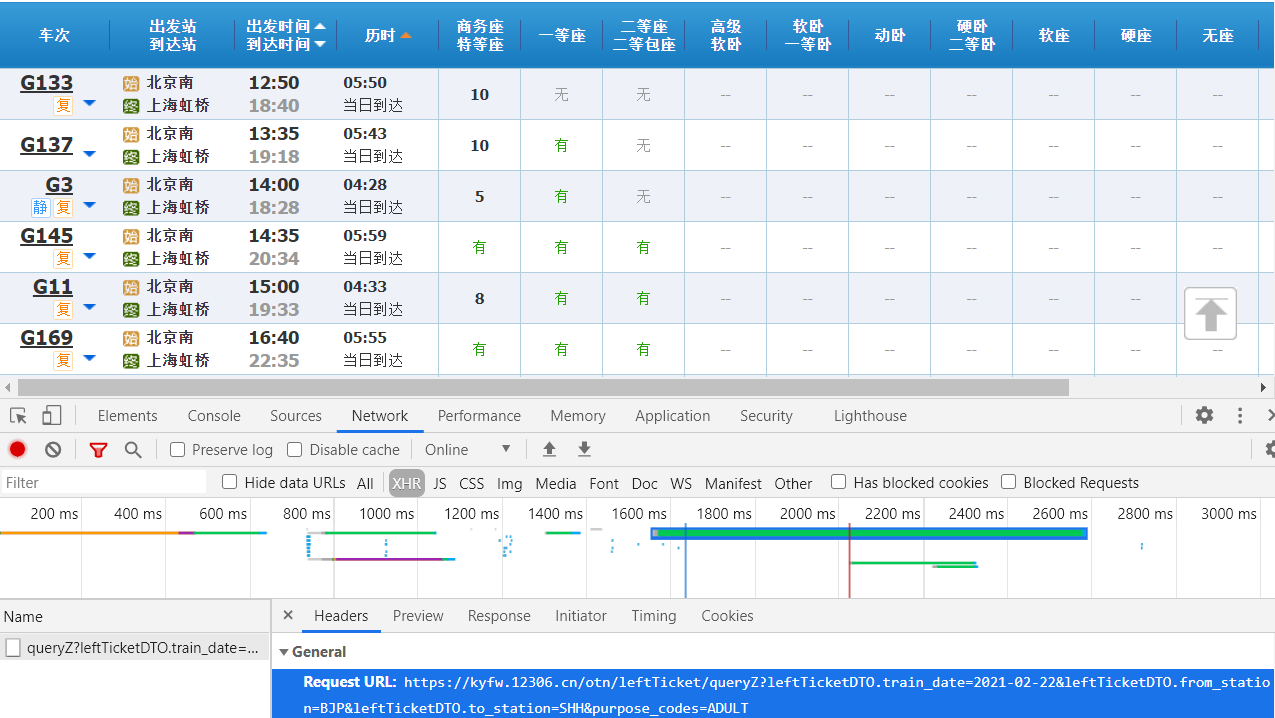
为避免错误,最好把浏览器中的User-Agent和cookie等一同传入
import requests
import json
def getDatas(year,month,date,_from,_to):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'kyfw.12306.cn',
'Referer': 'https://www.12306.cn/',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-site',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
"Cookie": "_uab_collina=161396635873945822102574; JSESSIONID=631FB91746707366DCBBA5BE2C7453A1; BIGipServerotn=1106248202.24610.0000; RAIL_EXPIRATION=1614230065687; RAIL_DEVICEID=io7zYXeM-Gz8YUk5ZnOn0GjmqcUoFTj4kauIJForuflzNbyVp0X8kMyAxmqJYYJAhD8NCH3XBPNqdP3i225ICWhEvFl8Rr854pgCzjRbeBru9zok8pfJayROxlXHA4KMD4zV5AlBd8SqAbVVZbCvtviysCtLN_CH; BIGipServerpool_passport=165937674.50215.0000; route=c5c62a339e7744272a54643b3be5bf64; _jc_save_fromStation=%u5317%u4EAC%2CBJP; _jc_save_toStation=%u4E0A%u6D77%2CSHH; _jc_save_fromDate=2021-02-22; _jc_save_toDate=2021-02-22; _jc_save_wfdc_flag=dc",
}
urls = "https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date={}-{}-{}&leftTicketDTO.from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT".format(str(year),str(month),str(date),_from,_to)
# print(urls)
res = requests.get(urls,headers=headers)
if res.status_code == 200:
# print(res.text)
res = json.loads(res.text)
datas = res["data"]["result"]
# print(datas) #页面的所有火车票信息(字符串列表)
return datas
else:
print('网页未响应')
return
pass
删选信息
根据对比删选出所需要的信息,并归类整理便于使用。

#对单条信息删选,找出需要的信息
def _re(data):
message = data.split("|") #经过拆分可看出“预定”都是在第二个(索引为1)
#print(message)
return message #单条火车信息组成的列表
#对信息归类整理
def prt(mes):
a = mes[3] #车次
b1 = code(mes[4]) #出发站(更改为汉字)
b2 = code(mes[7]) #到达站(更改为汉字)
time1 = mes[8] #出发时间
time2 = mes[9] #到达时间
time3 = mes[10] #历时
time4 = mes[13] #日期
c1 = mes[32] #商务座(特等座)
c2 = mes[31] #一等座
c3 = mes[30] #二等座
c4 = mes[26] #无座
c5 = mes[23] #软卧
c6 = mes[28] #硬卧
c7 = mes[29] #硬座
l = [a,b1,b2,time1,time2,time3,time4,c1,c2,c3,c4,c5,c6,c7]
for i in range(len(l)):
if l[i]=="":
l[i] = "无"
dic0 = {"车次:":a,"出发站:":b1,"到达站:":b2,
"出发时间:":time1,"到达时间:":time2,"历时:":time3,"日期:":time4,
"商务座:":c1,"一等座:":c2,"二等座:":c3,"无座:":c4,"软卧:":c5,"硬卧:":c6,"硬座:":c7}
list0 = ["车次:",l[0],"出发站:",l[1],"到达站:",l[2],
"出发时间:",l[3]," 到达时间:",l[4],"历时:",l[5],"日期:",l[6],
"商务座:",l[7],"一等座:",l[8],"二等座:",l[9],"无座:",l[10],"软卧:",l[11],"硬卧:",l[12],"硬座:",l[13]]
return list0
此时,所需要的车次,余票等信息都已找出。
保存
将爬取的信息保存到本地(可保存为txt、excel、json或数据库等)
### 保存为txt
#文本返回保存(将数据(列表)转换称可被保存的格式)
def txt_format(l):
'文本格式优化'
for i in range(1,len(l),2):
l[i] = "{0:{1}<5}\t".format(l[i],chr(12288)) #汉字的半角问题
l = "".join(l)
return l
def save_txt(m): #保存为txt文件或直接输出
with open(path+"火车票.txt","a") as f:
f.write(m)
f.write('\r\n')
f.write('\r\n')
def go_txt(year,month,date,_from,_to): #保存为txt
datas = getDatas(year,month,date,_from,_to)
for data in datas:
mes = _re(data) #找出需要的信息
prt_txt = prt(mes) #对信息归类整理
m = txt_format(prt_txt)
# print(m,"\n") #返回到屏幕
save_txt(m) #保存为txt
### 保存为excel
import openpyxl
import os
#保存为excel
def save_excel(l,i): #保存为excel文件
while os.path.exists(path+"火车票.xlsx") == False: #若文件不存在则创建
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = "火车票信息"
wb.save(path+"火车票.xlsx")
wb = openpyxl.load_workbook(path+"火车票.xlsx") #读取excel表
sheet = wb["火车票信息"]
if sheet["A1"].value == None: #首行,用于标识对应的数据
sheet["A1"] = l[0].replace(":","")
sheet["B1"] = l[2].replace(":","")
sheet["C1"] = l[4].replace(":","")
sheet["D1"] = l[6].replace(":","")
sheet["E1"] = l[8].replace(":","")
sheet["F1"] = l[10].replace(":","")
sheet["G1"] = l[12].replace(":","")
sheet["H1"] = l[14].replace(":","")
sheet["I1"] = l[16].replace(":","")
sheet["J1"] = l[18].replace(":","")
sheet["K1"] = l[20].replace(":","")
sheet["L1"] = l[22].replace(":", "")
sheet["M1"] = l[24].replace(":", "")
sheet["N1"] = l[26].replace(":", "")
i = str(i)
sheet["A"+i] = l[1]
sheet["B"+i] = l[3]
sheet["C"+i] = l[5]
sheet["D"+i] = l[7]
sheet["E"+i] = l[9]
sheet["F"+i] = l[11]
sheet["G"+i] = l[13]
sheet["H"+i] = l[15]
sheet["I"+i] = l[17]
sheet["J"+i] = l[19]
sheet["K"+i] = l[21]
sheet["L"+i] = l[23]
sheet["M"+i] = l[25]
sheet["N"+i] = l[27]
wb.save(path+"火车票.xlsx")
pass
def go_excel(year,month,date,_from,_to): #保存为excel
datas = getDatas(year,month,date,_from,_to)
i = 2
for data in datas:
mes = _re(data)
prt_txt = prt(mes)
save_excel(prt_txt,i) #保存为excel
i += 2
其它
-
汉字编码转换
我们在终端输入的是中文,而网站需要的是站点代码,所以需要进行转换。就用到了开篇的"站点转换"。
# 导入站点转换的py文件 import station_name_code #汉字编码转换 def code(name): name_code = station_name_code.to_dic()[0] code_name = station_name_code.to_dic()[1] if name in name_code: return name_code[name] elif name in code_name: return code_name[name] else: print("站点不存在") -
选择路径
对于不同用户,存放文件的路径的需求是不同的,所以额外设置一个可以选择路径的功能。
import tkinter as tk from tkinter import filedialog def select_path(): '选择路径' root = tk.Tk() root.withdraw() folderpath = filedialog.askdirectory() path = folderpath + '/' return path
整体代码
#!-*-coding:utf-8 -*-
# python3.7
# @Author:fuq666@qq.com
# Update time:2020-09-10
# Filename:爬取火车票信息
"""
实现功能:选择时间和始终站(中文),可查出该日期的所有车次及余票,结果可返回为txt或excel文件。
待改进:1.强制输入站点为中文,或站点代码
2.可选时间的限制,相对于当前时间(一个月后则无效?)
3.增加购票系统?
4.变为GUI桌面程序
"""
import requests,openpyxl
import os,json,re,time
import station_name_code
import tkinter as tk
from tkinter import filedialog
def getDatas(year,month,date,_from,_to):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'kyfw.12306.cn',
'Referer': 'https://www.12306.cn/',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-site',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
"Cookie": "_uab_collina=161396635873945822102574; JSESSIONID=631FB91746707366DCBBA5BE2C7453A1; BIGipServerotn=1106248202.24610.0000; RAIL_EXPIRATION=1614230065687; RAIL_DEVICEID=io7zYXeM-Gz8YUk5ZnOn0GjmqcUoFTj4kauIJForuflzNbyVp0X8kMyAxmqJYYJAhD8NCH3XBPNqdP3i225ICWhEvFl8Rr854pgCzjRbeBru9zok8pfJayROxlXHA4KMD4zV5AlBd8SqAbVVZbCvtviysCtLN_CH; BIGipServerpool_passport=165937674.50215.0000; route=c5c62a339e7744272a54643b3be5bf64; _jc_save_fromStation=%u5317%u4EAC%2CBJP; _jc_save_toStation=%u4E0A%u6D77%2CSHH; _jc_save_fromDate=2021-02-22; _jc_save_toDate=2021-02-22; _jc_save_wfdc_flag=dc",
}
urls = "https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date="+str(year)+"-"+str(month)+"-"+str(date)+"&leftTicketDTO.from_station="+_from+"&leftTicketDTO.to_station="+_to+"&purpose_codes=ADULT"
# print(urls)
res = requests.get(urls,headers=headers)
if res.status_code == 200:
# print(res.text)
res = json.loads(res.text)
datas = res["data"]["result"]
# print(datas) #页面的所有火车票信息(字符串列表)
return datas
else:
print('网页未响应')
return
pass
#对单条信息删选,找出需要的信息
def _re(data):
'删选每条信息'
message = data.split("|") #经过拆分可看出“预定”都是在第二个(索引为1)
#print(message)
return message #单条火车信息组成的列表
#对信息归类整理
def prt(mes):
'对应归类整理'
a = mes[3] #车次
b1 = code(mes[4]) #出发站(更改为汉字)
b2 = code(mes[7]) #到达站(更改为汉字)
time1 = mes[8] #出发时间
time2 = mes[9] #到达时间
time3 = mes[10] #历时
time4 = mes[13] #日期
c1 = mes[32] #商务座(特等座)
c2 = mes[31] #一等座
c3 = mes[30] #二等座
c4 = mes[26] #无座
c5 = mes[23] #软卧
c6 = mes[28] #硬卧
c7 = mes[29] #硬座
l = [a,b1,b2,time1,time2,time3,time4,c1,c2,c3,c4,c5,c6,c7]
for i in range(len(l)):
if l[i]=="":
l[i] = "无"
dic0 = {"车次:":a,"出发站:":b1,"到达站:":b2,
"出发时间:":time1,"到达时间:":time2,"历时:":time3,"日期:":time4,
"商务座:":c1,"一等座:":c2,"二等座:":c3,"无座:":c4,"软卧:":c5,"硬卧:":c6,"硬座:":c7}
list0 = ["车次:",l[0],"出发站:",l[1],"到达站:",l[2],
"出发时间:",l[3]," 到达时间:",l[4],"历时:",l[5],"日期:",l[6],
"商务座:",l[7],"一等座:",l[8],"二等座:",l[9],"无座:",l[10],"软卧:",l[11],"硬卧:",l[12],"硬座:",l[13]]
return list0
#文本返回保存(将数据(列表)转换称可被保存的格式)
def txt_format(l):
'文本格式优化'
for i in range(1,len(l),2):
l[i] = "{0:{1}<5}\t".format(l[i],chr(12288)) #汉字的半角问题
l = "".join(l)
return l
#保存为txt
def save_txt(m):
'保存为txt文件或直接输出'
with open(path+"火车票.txt","a") as f:
f.write(m)
f.write('\r\n')
f.write('\r\n')
#保存为excel
def save_excel(l,i):
'保存为excel文件'
while os.path.exists(path+"火车票.xlsx") == False:
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = "火车票信息"
wb.save(path+"火车票.xlsx")
wb = openpyxl.load_workbook(path+"火车票.xlsx")
sheet = wb["火车票信息"]
if sheet["A1"].value == None: #首行
sheet["A1"] = l[0].replace(":","")
sheet["B1"] = l[2].replace(":","")
sheet["C1"] = l[4].replace(":","")
sheet["D1"] = l[6].replace(":","")
sheet["E1"] = l[8].replace(":","")
sheet["F1"] = l[10].replace(":","")
sheet["G1"] = l[12].replace(":","")
sheet["H1"] = l[14].replace(":","")
sheet["I1"] = l[16].replace(":","")
sheet["J1"] = l[18].replace(":","")
sheet["K1"] = l[20].replace(":","")
sheet["L1"] = l[22].replace(":", "")
sheet["M1"] = l[24].replace(":", "")
sheet["N1"] = l[26].replace(":", "")
i = str(i)
sheet["A"+i] = l[1]
sheet["B"+i] = l[3]
sheet["C"+i] = l[5]
sheet["D"+i] = l[7]
sheet["E"+i] = l[9]
sheet["F"+i] = l[11]
sheet["G"+i] = l[13]
sheet["H"+i] = l[15]
sheet["I"+i] = l[17]
sheet["J"+i] = l[19]
sheet["K"+i] = l[21]
sheet["L"+i] = l[23]
sheet["M"+i] = l[25]
sheet["N"+i] = l[27]
wb.save(path+"火车票.xlsx")
pass
## 运行顺序
def go_txt(year,month,date,_from,_to):
'保存为txt'
datas = getDatas(year,month,date,_from,_to)
for data in datas:
mes = _re(data) #找出需要的信息
prt_txt = prt(mes) #对信息归类整理
m = txt_format(prt_txt)
print(m,"\n") #返回到屏幕
save_txt(m) #保存为txt
def go_excel(year,month,date,_from,_to):
'保存为excel'
datas = getDatas(year,month,date,_from,_to)
i = 2
for data in datas:
mes = _re(data)
prt_txt = prt(mes)
save_excel(prt_txt,i)
i += 2
#站点编码转换
def code(name):
'站点编码转换'
d = station_name_code.to_dic()
name_code = d[0]
code_name = d[1]
if name in name_code:
return name_code[name]
elif name in code_name:
return code_name[name]
else:
print("站点不存在")
#选择保存路径
def select_path():
'选择保存路径'
import tkinter as tk
from tkinter import filedialog
root = tk.Tk()
root.withdraw()
folderpath = filedialog.askdirectory()
path = folderpath + '/'
return path
#主程序
def main():
year=input("输入年份(如:2020):")
month=input("输入月份(如:01):")
date=input("输入日期(如:01):")
_from=input("输入出发站(如:北京):")
_to=input("输入到达站(如:武汉):")
choice=int(input("返回至屏幕和txt文件输入“0”,返回至excel文件输入“1”:"))
# year = 2021
# month = '02'
# date = 20
# _from = '北京'
# _to = '武汉'
# choice = 0
_from = code(_from) #转换
_to = code(_to)
if choice == 0:
try:
go_txt(year,month,date,_from,_to) #txt文件和(或)返回到屏幕
except:
print("未找到")
else:
try:
go_excel(year,month,date,_from,_to) #excel表格
except:
print("未找到")
if __name__ == "__main__":
print('请选择结果保存路径:')
time.sleep(0.5)
path = select_path()
# path = r'C:/Users/15394/Desktop/'
main()
print('保存在{}'.format(path))
print("Done")
注
- 根据自己的浏览器信息更改cookie数据
遇上方知有

 浙公网安备 33010602011771号
浙公网安备 33010602011771号